请我喝杯咖啡☕
*我的帖子解释了 emnist。
emnist()可以使用emnist数据集,如下所示:
*备忘录:

- 第一个参数是 root(必需类型:str 或 pathlib.path)。 *绝对或相对路径都是可能的。
- 第二个参数是 split(required-type:str)。 *可以设置“byclass”、“bymerge”、“balanced”、“letters”、“digits”或“mnist”。
- 有训练参数(可选-默认:false-类型:float):
*备注:
- 对于 split="byclass" 和 split="byclass",如果为 true,则使用训练数据(697,932 张图像),如果为 false,则使用测试数据(116,323 张图像)。
- 对于 split="balanced",如果为 true,则使用训练数据(112,800 张图像),如果为 false,则使用测试数据(188,00 张图像)。
- 对于 split="letters",如果为 true,则使用训练数据(124124,800 张图像),如果为 false,则使用测试数据(20,800 张图像)。
- 对于 split="digits",如果为 true,则使用训练数据(240,000 张图像),如果为 false,则使用测试数据(40,000 张图像)。
- 对于 split="mnist",如果为 true,则使用训练数据(60,000 张图像),如果为 false,则使用测试数据(10,000 张图像)。
- 有转换参数(可选-默认:无-类型:可调用)。
- 有 target_transform 参数(可选-默认:无-类型:可调用)。
- 有下载参数(可选-默认:false-类型:bool):
*备注:
- 如果为 true,则从互联网下载数据集并解压(解压)到根目录。
- 如果为 true 并且数据集已下载,则将其提取。
- 如果为 true 并且数据集已下载并提取,则不会发生任何事情。
- 如果数据集已经下载并提取,则应该为 false,因为它速度更快。
- 您可以从此处手动下载并提取数据集,例如数据/emnist/raw/.
- 存在图像默认翻转并逆时针旋转90度的错误,因此需要对其进行转换。
from torchvision.datasets import emnist
train_data = emnist(
root="data",
split="byclass"
)
train_data = emnist(
root="data",
split="byclass",
train=true,
transform=none,
target_transform=none,
download=false
)
test_data = emnist(
root="data",
split="byclass",
train=false
)
len(train_data), len(test_data)
# 697932 116323
train_data
# dataset emnist
# number of datapoints: 697932
# root location: data
# split: train
train_data.root
# 'data'
train_data.split
# 'byclass'
train_data.train
# true
print(train_data.transform)
# none
print(train_data.target_transform)
# none
train_data.download
#
train_data[0]
# (, 35)
train_data[1]
# (, 36)
train_data[2]
# (, 6)
train_data[3]
# (, 3)
train_data[4]
# (, 22)
train_data.classes
# ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
# 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm',
# 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z',
# 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm',
# 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
from torchvision.datasets import emnist
train_data = emnist(
root="data",
split="byclass",
train=true
)
test_data = emnist(
root="data",
split="byclass",
train=false
)
import matplotlib.pyplot as plt
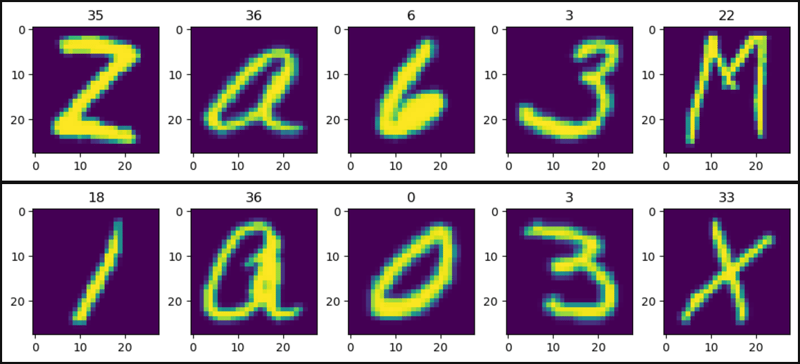
def show_images(data):
plt.figure(figsize=(12, 2))
col = 5
for i, (image, label) in enumerate(data, 1):
plt.subplot(1, col, i)
plt.title(label)
plt.imshow(image)
if i == col:
break
plt.show()
show_images(data=train_data)
show_images(data=test_data)
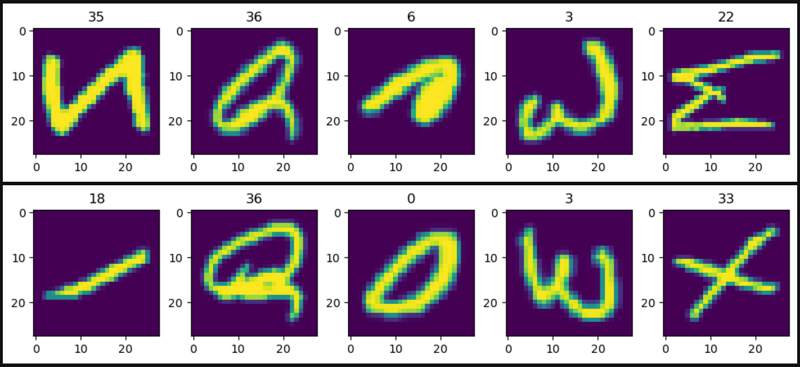
from torchvision.datasets import EMNIST
from torchvision.transforms import v2
train_data = EMNIST(
root="data",
split="byclass",
train=True,
transform=v2.Compose([
v2.RandomHorizontalFlip(p=1.0),
v2.RandomRotation(degrees=(90, 90))
])
)
test_data = EMNIST(
root="data",
split="byclass",
train=False,
transform=v2.Compose([
v2.RandomHorizontalFlip(p=1.0),
v2.RandomRotation(degrees=(90, 90))
])
)
import matplotlib.pyplot as plt
def show_images(data):
plt.figure(figsize=(12, 2))
col = 5
for i, (image, label) in enumerate(data, 1):
plt.subplot(1, col, i)
plt.title(label)
plt.imshow(image)
if i == col:
break
plt.show()
show_images(data=train_data)
show_images(data=test_data)