







经历了大模型2024一整年度的兵荒马乱,从年初的sora文生视频到minimax顿悟后的开源,要说年度最大赢家,当属deepseek莫属:年中,deepseek-v2以其1/100的售价,横扫包括gpt4、qwen、百度等一系列商用模型;年底,deepseek-v3发布,以moe为核心的专家网络技术,让其以极低的推理成本,获得了媲美gpt-4o的效果。

本篇文章作为年度技术洞察类文章,今天的重点不是deepseek的训练与推理,如果对训练和推理感兴趣,我在年中写过一篇训练与推理的实战,其中详细讲述了DeepSeek-V2大模型的训练和推理,详细可点击:AI智能体研发之路-模型篇(二):DeepSeek-V2-Chat 训练与推理实战(只需将V2替换为V3,即可体验最新版本deepseek)。今天的重点是更深一个层次,带大家代码级认识MoE混合专家网络技术。
1.2 技术洞察—MoE(Mixture-of-Experts,混合专家网络)MoE(Mixture-of-Experts) 并不是一个新词,近7-8年间,在我做推荐系统精排模型过程中,业界将MoE技术应用于推荐系统多任务学习,以MMoE(2018,google)、PLE(2020,腾讯)为基石,通过门控网络为多个专家网络加权平均,定义每个专家的重要性,解决多目标、多场景、多任务等问题。近1-2年间,基于MoE思想构建的大模型层出不穷,通过路由网络对多个专家网络进行选择,提升推理效率,经典模型有DeepSeekMoE、Mixtral 8x7B、Flan-MoE等。
万丈高楼平地起,今天我们不聊空中楼阁,而是带大家实现一个MoE网络,了解MoE代码是怎么构建的,大家可以以此代码为基础,继续垒砖,根据自己的业务场景,创新性的构建自己的专家网络。
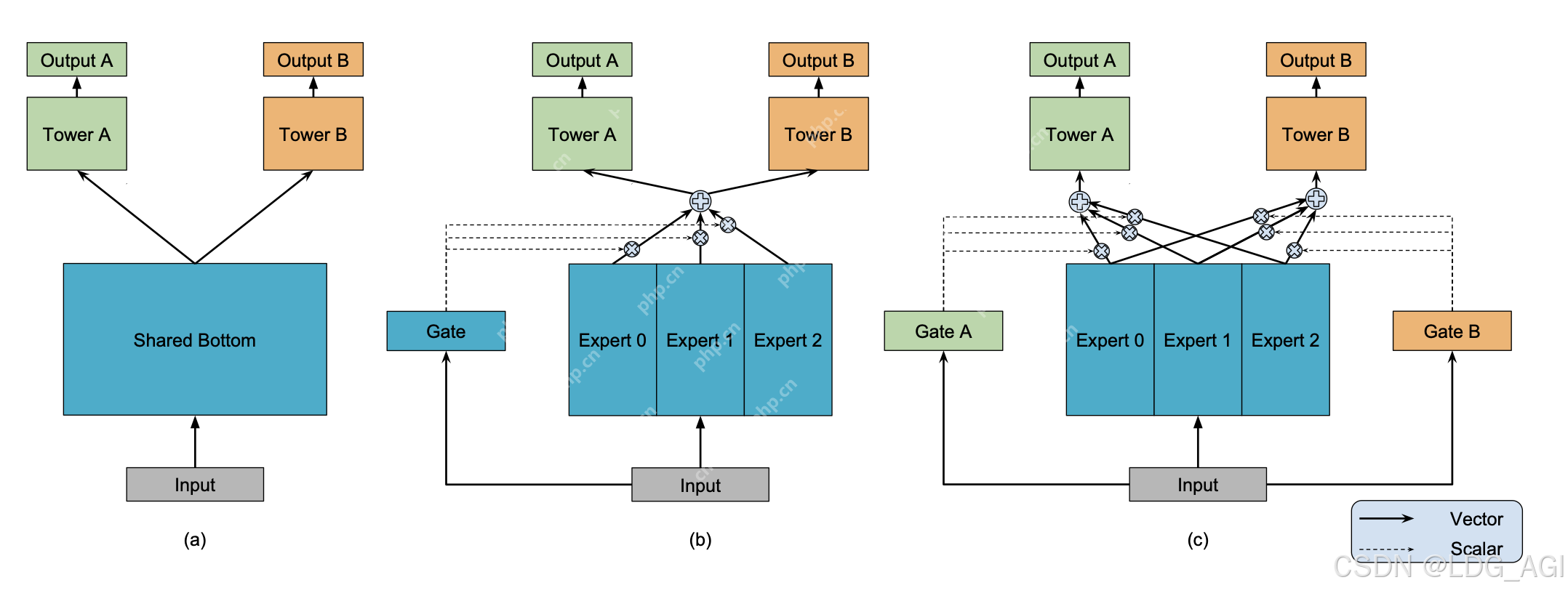
二、MoE(Mixture-of-Experts,混合专家网络)2.1 技术原理MoE(Mixture-of-Experts)全称为混合专家网络,主要由多个专家网络、多个任务塔、门控网络构成。核心原理:样本数据分别输入num_experts个专家网络进行推理,每个专家网络实际上是一个前馈神经网络(MLP),输入维度为x,输出维度为output_experts_dim;同时,样本数据输入门控网络,门控网络也是一个MLP(可以为多层,也可以为一层),输出为num_experts个experts专家的概率分布,维度为num_experts(菜用softmax将输出归一化,各个维度加起来和为1);将每个专家网络的输出,基于gate门控网络的softmax加权平均,作为Task的输入,所以Task的输入统一维度均为output_experts_dim。在每次反向传播迭代时,对Gate和num_experts个专家参数进行更新,Gate和专家网络的参数受任务Task A、B共同影响。
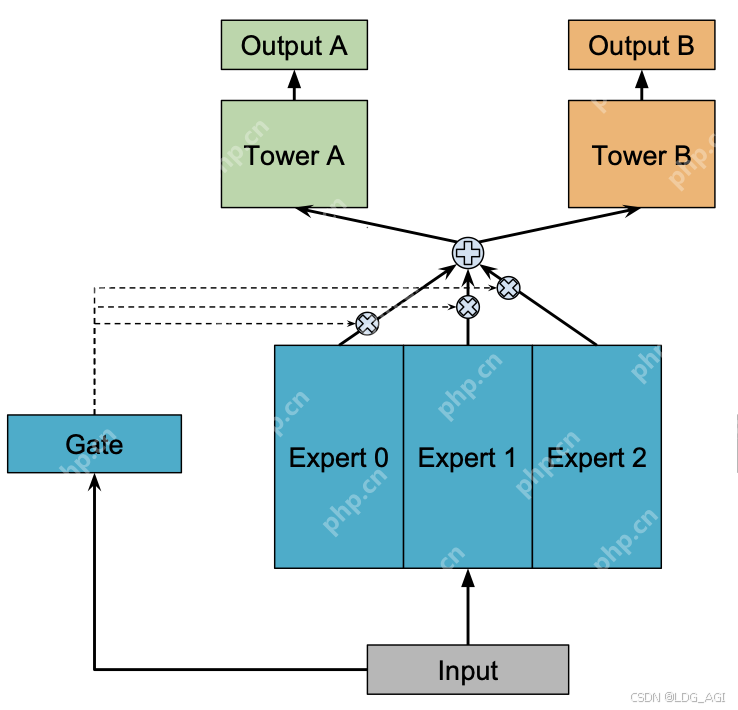
相较于传统的DNN网络,MoE的本质是通过多个专家网络对预估任务共同决策,引入Gate作为专家的裁判,给每一个专家打分,判定哪个专家更加权威。(DeepSeekMoE的Router与Gate类似,区别是Gate为每一个专家赋分,加权平均,Router对专家进行选择,推理速度更快)。相较于传统的DNN网络:
多个DNN专家网络投票共同决定推理结果,相较于单个DNN网络泛化性更好,准确率更高。Gate网络基于多个Task任务进行反馈收敛,可以学到多个Task任务数据的平衡性。缺点:
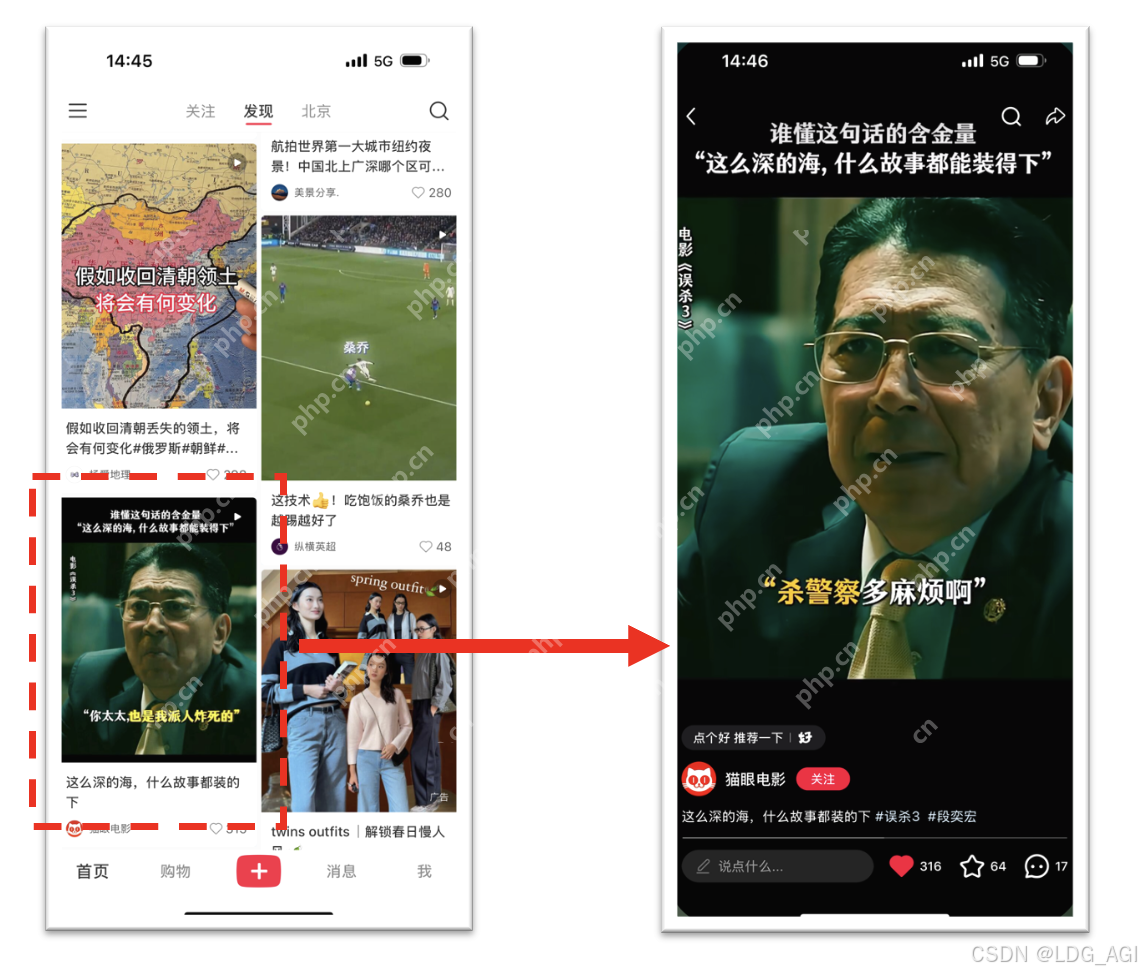
朴素的MoE仅使用了一个Gate网络,虽然Gate网络由多个Task任务共同收敛学习得到,具有一定的平衡性,但对于每个Task的个性化能力仍然不足。(Google针对此缺点发布了MMoE)底层多个专家网络均为共享专家,输入均为样本数据,参数的差异主要由初始化的不同得到,并不具备特异性。(腾讯针对此缺点发布了PLE)输入Input均为全部样本数据,学不出不同场景任务的差异性,需要在输入层对场景特征进行拆分(阿里针对此缺点发布了ESMM)2.3 业务代码实践2.3.1 业务场景与建模我们仍然以小红书推荐场景为例,用户在一级发现页场景中停留并点击了“误杀3”中的一个视频笔记,在二级场景视频播放页中观看并点赞了视频。
我们构建一个100维特征输入,4个experts专家网络,2个task任务的,1个门控的MoE网络,用于建模跨场景多任务学习问题,模型架构图如下:

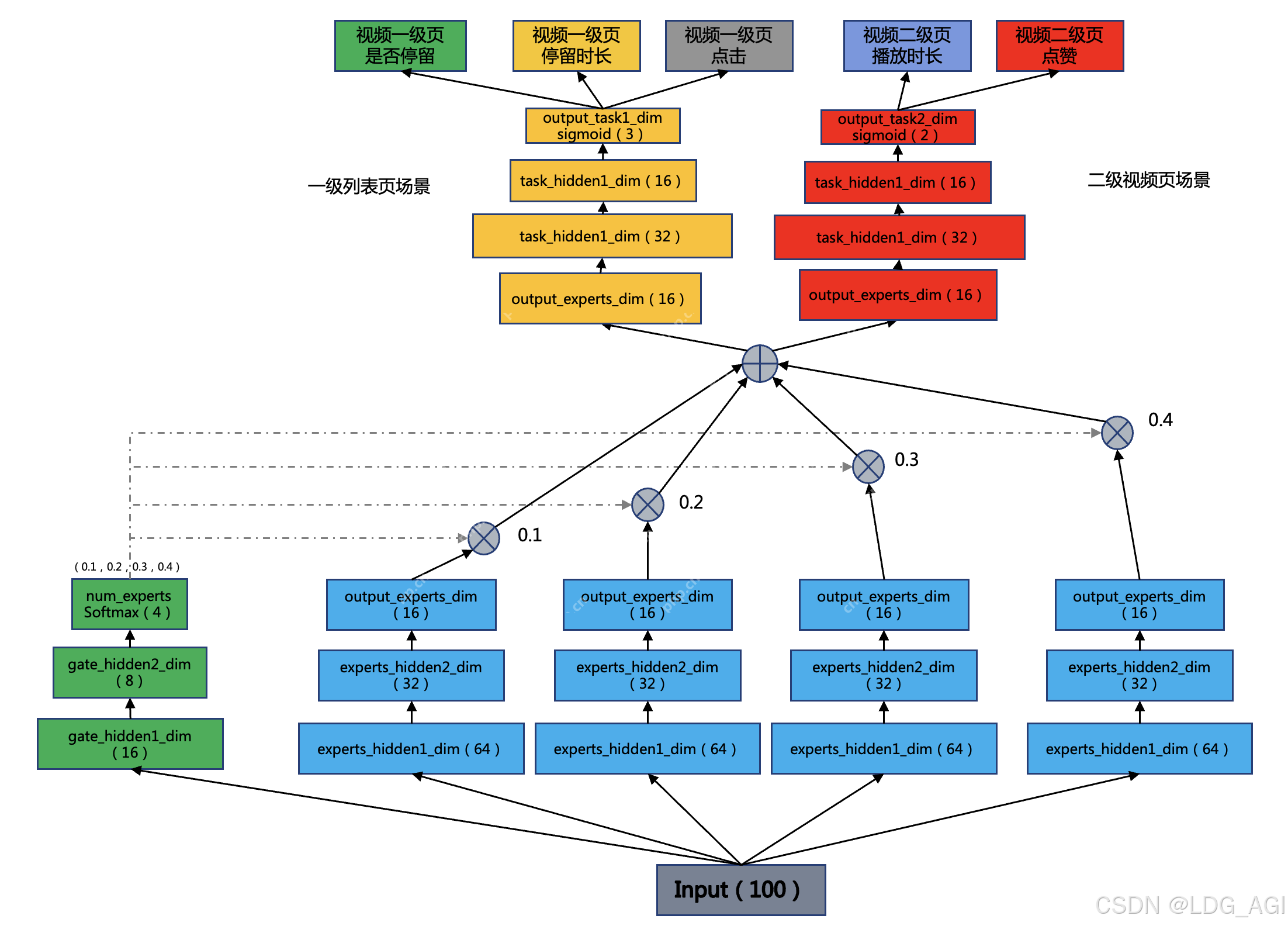
如架构图所示,其中有几个注意的点:
num_experts:门控gate的输出维度和专家数相同,均为num_experts,因为gate的用途是对专家网络最后一层进行加权平均,gate维度与专家数是直接对应关系。output_experts_dim:专家网络的输出维度和task网络的输入维度相同,task网络承接的是专家网络各维度的加权平均值,experts网络与task网络是直接对应关系。Softmax:Gate门控网络对最后一层采用Softmax归一化,保证专家网络加权平均后值域相同2.3.2 模型代码实现基于pytorch,实现上述网络架构,如下:
代码语言:javascript代码运行次数:0运行复制<code class="javascript">import torchimport torch.nn as nnimport torch.optim as optimfrom torch.utils.data import DataLoader, TensorDatasetclass MoEModel(nn.Module): def __init__(self, input_dim, experts_hidden1_dim, experts_hidden2_dim, output_experts_dim, task_hidden1_dim, task_hidden2_dim, output_task1_dim, output_task2_dim, gate_hidden1_dim, gate_hidden2_dim, num_experts): super(MoEModel, self).__init__() self.num_experts = num_experts self.output_experts_dim = output_experts_dim # 初始化多个专家网络 self.experts = nn.ModuleList([ nn.Sequential( nn.Linear(input_dim, experts_hidden1_dim), nn.ReLU(), nn.Linear(experts_hidden1_dim, experts_hidden2_dim), nn.ReLU(), nn.Linear(experts_hidden2_dim, output_experts_dim), nn.ReLU() ) for _ in range(num_experts) ]) # 定义任务1的输出层 self.task1_head = nn.Sequential( nn.Linear(output_experts_dim, task_hidden1_dim), nn.ReLU(), nn.Linear(task_hidden1_dim, task_hidden2_dim), nn.ReLU(), nn.Linear(task_hidden2_dim, output_task1_dim), nn.Sigmoid() ) # 定义任务2的输出层 self.task2_head = nn.Sequential( nn.Linear(output_experts_dim, task_hidden1_dim), nn.ReLU(), nn.Linear(task_hidden1_dim, task_hidden2_dim), nn.ReLU(), nn.Linear(task_hidden2_dim, output_task2_dim), nn.Sigmoid() ) # 初始化门控网络 self.gating_network = nn.Sequential( nn.Linear(input_dim, gate_hidden1_dim), nn.ReLU(), nn.Linear(gate_hidden1_dim, gate_hidden2_dim), nn.ReLU(), nn.Linear(gate_hidden2_dim, num_experts), nn.Softmax(dim=1) ) def forward(self, x): # 计算输入数据通过门控网络后的权重 gates = self.gating_network(x) #print(gates) batch_size, _ = x.shape task1_inputs = torch.zeros(batch_size, self.output_experts_dim) task2_inputs = torch.zeros(batch_size, self.output_experts_dim) # 计算每个专家的输出并加权求和 for i in range(self.num_experts): expert_output = self.experts[i](x) task1_inputs += expert_output * gates[:, i].unsqueeze(1) task2_inputs += expert_output * gates[:, i].unsqueeze(1) task1_outputs = self.task1_head(task1_inputs) task2_outputs = self.task2_head(task2_inputs) return task1_outputs, task2_outputs# 实例化模型对象num_experts = 4 # 假设有4个专家experts_hidden1_dim = 64experts_hidden2_dim = 32output_experts_dim = 16gate_hidden1_dim = 16gate_hidden2_dim = 8task_hidden1_dim = 32task_hidden2_dim = 16output_task1_dim = 3output_task2_dim = 2# 构造虚拟样本数据torch.manual_seed(42) # 设置随机种子以保证结果可重复input_dim = 10num_samples = 1024X_train = torch.randint(0, 2, (num_samples, input_dim)).float()y_train_task1 = torch.rand(num_samples, output_task1_dim) # 假设任务1的输出维度为5y_train_task2 = torch.rand(num_samples, output_task2_dim) # 假设任务2的输出维度为3# 创建数据加载器train_dataset = TensorDataset(X_train, y_train_task1, y_train_task2)train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True)model = MoEModel(input_dim, experts_hidden1_dim, experts_hidden2_dim, output_experts_dim, task_hidden1_dim, task_hidden2_dim, output_task1_dim, output_task2_dim, gate_hidden1_dim, gate_hidden2_dim, num_experts)# 定义损失函数和优化器criterion_task1 = nn.MSELoss()criterion_task2 = nn.MSELoss()optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练循环num_epochs = 100for epoch in range(num_epochs): model.train() running_loss = 0.0 for batch_idx, (X_batch, y_task1_batch, y_task2_batch) in enumerate(train_loader): # 前向传播: 获取预测值 #print(batch_idx, X_batch ) #print(f'Epoch [{epoch+1}/{num_epochs}-{batch_idx}], Loss: {running_loss/len(train_loader):.4f}') outputs_task1, outputs_task2 = model(X_batch) # 计算每个任务的损失 loss_task1 = criterion_task1(outputs_task1, y_task1_batch) loss_task2 = criterion_task2(outputs_task2, y_task2_batch) total_loss = loss_task1 + loss_task2 # 反向传播和优化 optimizer.zero_grad() total_loss.backward() optimizer.step() running_loss += total_loss.item() if epoch % 10 == 0: print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(train_loader):.4f}')print(model)for param_tensor in model.state_dict(): print(param_tensor, "\t", model.state_dict()[param_tensor].size())# 模型预测model.eval()with torch.no_grad(): test_input = torch.randint(0, 2, (1, input_dim)).float() # 构造一个测试样本 pred_task1, pred_task2 = model(test_input) print(f'一级场景预测结果: {pred_task1}') print(f'二级场景预测结果: {pred_task2}')</code>2.3.3 模型训练与推理测试运行上述代码,模型启动训练,Loss逐渐收敛,测试结果如下:

使用print(model)打印模型结构如下
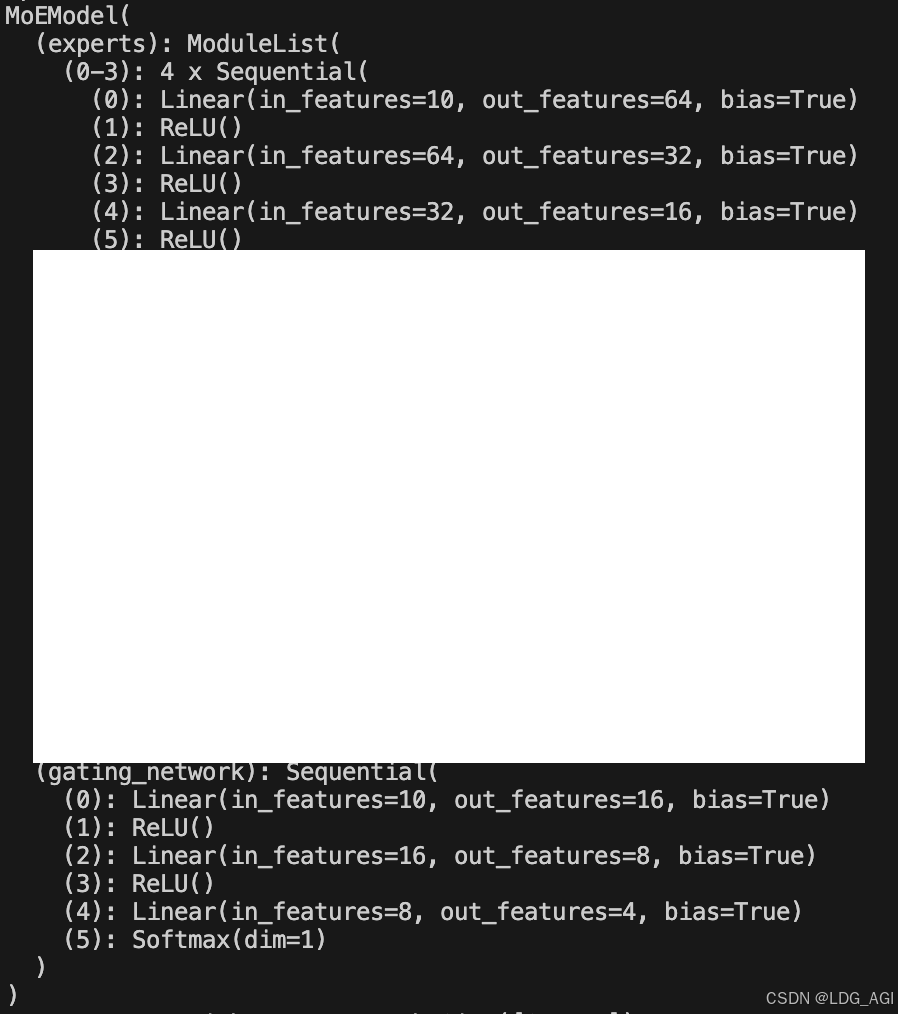
本文代码级脚踏实地讲解了DeepSeek大模型、MMoE推荐模型中的MoE(Mixture-of-Experts)技术,该技术的主要思想是通过门控(gate)或路由(router)网络,对多个专家进行加权平均或筛选,将一个DNN网络裂变为多个DNN网络后,投票决定预测结果,相较于单一的DNN网络,具有更强的容错性、泛化性与准确性,同时可以提高推理速度,节省推理资源。
技术洞察结论:MoE技术未来将成为大模型和推荐系统进一步突破的关键技术,个人认为该技术为2024年算法基础技术中的SOTA,但其实并没有那么神秘,通过本篇文章,可以试着动手实现一个MoE,再基于自己的业务场景,对齐专家网络、门控网络、任务网络进行创新,期待本篇文章对您有帮助!
如果您还有时间,欢迎阅读本专栏的其他文章:
【深度学习】多目标融合算法(一):样本Loss加权(Sample Loss Reweight)
【深度学习】多目标融合算法(二):底部共享多任务模型(Shared-Bottom Multi-task Model)





























