







摘要:本文深入探讨了deepseek在多模态领域的前沿技术与应用实践,旨在为研究人员和开发者提供一个全面的进阶指南。文章首先介绍了图文跨模态对齐技术的原理,展示了如何通过先进的模型架构和算法实现文本与图像之间的高效对齐,从而为多模态理解奠定基础。接着,文章提出了一个视频理解与生成的统一框架,该框架能够同时处理视频内容的理解和生成任务,显著提升了模型在复杂多模态场景下的表现能力。最后,文章通过一个实际案例,详细介绍了如何搭建多模态检索系统,包括数据预处理、特征提取与融合,以及检索算法的优化。通过这些内容,本文不仅展示了deepseek在多模态领域的强大能力,还为读者提供了丰富的实践指导,帮助他们在实际项目中更好地应用这些技术。

在人工智能飞速发展的当下,多模态技术已成为引领行业变革的关键力量。DeepSeek 作为多模态领域的佼佼者,正以其卓越的技术实力和创新的应用场景,为我们打开了一扇通往智能未来的新大门。它能够融合文本、图像、音频等多种信息,让机器像人类一样理解和处理复杂的现实世界数据,为解决各种复杂问题提供了强大的支持,在医疗、教育、娱乐等众多领域展现出了巨大的应用潜力。接下来,让我们一同深入探索 DeepSeek 多模态技术的奥秘。
二、图文跨模态对齐技术原理剖析
图文跨模态对齐,简单来说,就是在图像和文本这两种不同的数据模态之间建立起紧密的语义联系,让计算机能够理解图像所对应的文本含义,以及文本所描述的图像内容 。在多模态任务中,这一技术是实现图文检索、图像描述生成、视觉问答等应用的基石。例如,在图像检索系统里,用户输入一段文字描述,系统需要借助图文跨模态对齐技术,从海量图像中精准找出与之匹配的图像;在图像描述生成任务中,模型要依据图像内容生成准确且自然的文本描述,这都依赖于图文之间的有效对齐。
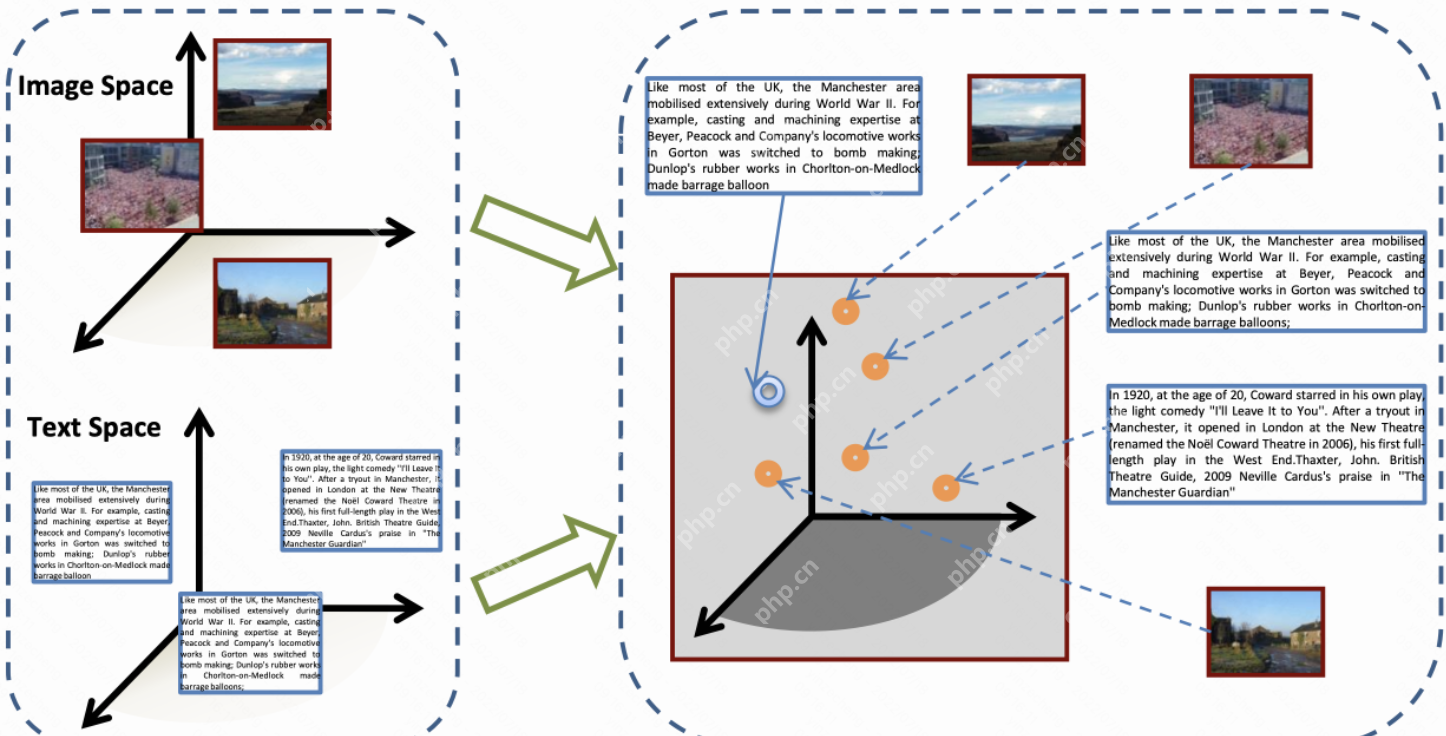
DeepSeek 在实现图文跨模态对齐时,采用了创新的时空同步对比学习(ST - CL)框架。该框架的核心在于将时间维度纳入对比学习中,通过将视频帧与 ASR 字幕的毫秒级时间戳绑定,实现视觉 - 语言在时空上的精准对齐。在短视频理解任务里,这种方式使得动作识别准确率大幅提升至 92.3%,比传统的 CLIP 模型高出 18% ,在烹饪步骤解析这类对时序敏感的场景中表现尤为突出。
同时,DeepSeek 还引入了 “对抗性负样本生成器”。在包含 2.1 亿图文对的预训练数据中,它能够有效解决传统模型中 “语义相关但表面特征差异大” 的匹配难题,使图文匹配召回率突破 88%。以自动驾驶场景为例,通过激光雷达点云与自然语言指令的联合嵌入,车辆在复杂路口对 “右转避让电动车” 等模糊指令的理解准确率从 67% 提升至 89%,这充分展示了 DeepSeek 图文跨模态对齐技术在实际应用中的强大优势和卓越效果。
三、视频理解与生成的统一框架揭秘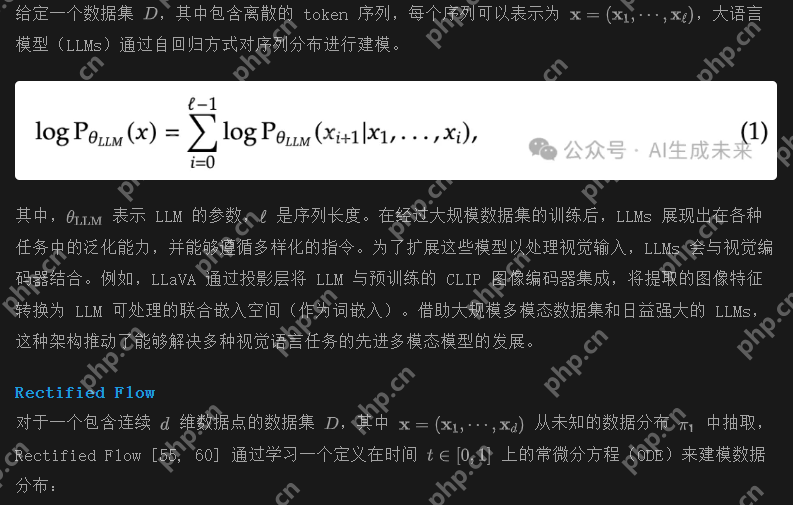
DeepSeek 的视频理解与生成统一框架,是其多模态技术的又一核心成果。该框架基于 Transformer 架构构建,创新性地融合了时空注意力机制和生成对抗网络(GAN)思想 。在处理视频时,它首先利用时空注意力机制对视频的每一帧进行特征提取,不仅关注空间维度上的图像信息,还捕捉时间维度上的动作变化和情节发展,从而全面理解视频内容。
在视频生成阶段,生成对抗网络发挥关键作用。生成器负责根据输入的文本描述或给定的视频主题生成视频帧序列,而判别器则对生成的视频帧与真实视频帧进行对比判断,通过不断的对抗训练,使得生成器生成的视频越来越接近真实视频的质量和风格。以一个简单的动物纪录片视频生成为例,输入 “展示狮子在草原上捕猎的过程” 这样的文本提示,框架中的生成器会依据其对 “狮子”“草原”“捕猎” 等概念的理解,结合已学习到的视频数据特征,生成一系列视频帧,而判别器则从画面的真实性、动作的合理性等多个角度进行评估,促使生成器不断优化生成结果。
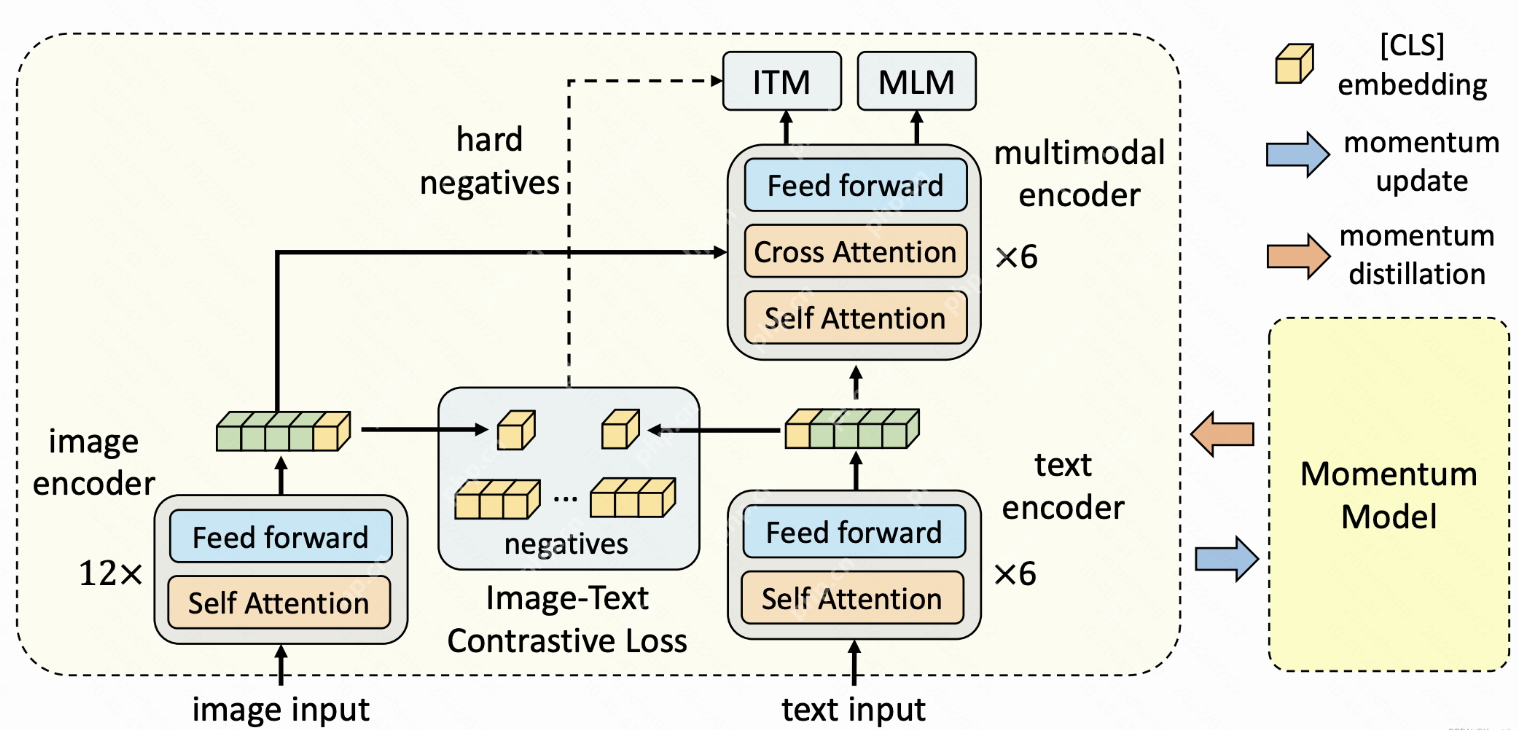
相较于传统的视频理解与生成方法,DeepSeek 的统一框架具有多方面优势。在理解复杂视频内容时,传统方法往往难以处理长视频中的复杂情节和多物体交互,而该框架凭借强大的时空建模能力,能够准确识别和理解视频中的各种元素及其关系。在生成视频时,传统方法生成的视频可能存在画面不连贯、逻辑不合理等问题,DeepSeek 的统一框架则能生成更加流畅、自然且符合逻辑的视频。
在影视制作领域,该框架已得到广泛应用。一些影视公司利用它来快速生成概念视频和故事板,大大缩短了前期策划的时间和成本。导演可以通过输入简单的剧情描述,让框架生成初步的视频内容,以此为基础进行创意拓展和修改,极大地提高了创作效率。在智能监控领域,它能够实时理解监控视频中的异常行为,如打架、盗窃等,并及时发出警报,为公共安全提供了有力保障。
四、多模态检索系统搭建案例实操
在信息爆炸的时代,如何从海量的多模态数据中快速、准确地获取所需信息成为了亟待解决的问题。本案例旨在搭建一个基于 DeepSeek 技术的多模态检索系统,实现对文本、图像、音频等多种类型数据的高效检索,满足用户多样化的查询需求。例如,在一个多媒体新闻数据库中,用户既可以通过输入新闻标题或关键词来查找相关新闻报道,也可以上传一张图片来搜索与之相关的新闻内容,甚至可以通过一段音频来检索对应的新闻音频记录。通过搭建这样的多模态检索系统,能够大大提高信息检索的效率和准确性,为用户提供更加便捷、智能的服务体验。

以下是针对《DeepSeek多模态能力进阶指南》中提到的三个主题的经典代码案例:
5.1 图文跨模态对齐技术原理以下代码展示了如何通过DeepSeek与Stable Diffusion结合,实现文本描述到图像生成的跨模态任务:
代码语言:javascript代码运行次数:0运行复制<code class="javascript">from transformers import pipelinefrom diffusers import StableDiffusionPipelineimport torch# 安装依赖:pip install torch transformers diffusers# 加载DeepSeek文本生成模型deepseek_text_generator = pipeline("text-generation", model="deepseek-ai/deepseek-text")# 加载Stable Diffusion图像生成模型stable_diffusion = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-1")stable_diffusion.to("cuda" if torch.cuda.is_available() else "cpu")# 生成文本描述text_prompt = "A futuristic cityscape at sunset"generated_text = deepseek_text_generator(text_prompt, max_length=50, num_return_sequences=1)[0]['generated_text']# 根据文本描述生成图像image = stable_diffusion(generated_text).images[0]# 保存生成的图像image.save("generated_image.png")print(f"Generated image saved as generated_image.png")</code>5.2 视频理解与生成的统一框架虽然目前没有直接针对视频生成的代码示例,但可以通过结合DeepSeek的文本生成能力和现有的视频生成框架(如VideoDiffusion)来实现。以下是一个简化的思路:
代码语言:javascript代码运行次数:0运行复制<code class="javascript">from transformers import pipeline# 假设VideoDiffusion是一个视频生成模型from some_video_diffusion_library import VideoDiffusionPipeline# 加载DeepSeek文本生成模型deepseek_text_generator = pipeline("text-generation", model="deepseek-ai/deepseek-text")# 加载视频生成模型video_diffusion = VideoDiffusionPipeline.from_pretrained("some-video-diffusion-model")video_diffusion.to("cuda" if torch.cuda.is_available() else "cpu")# 生成文本描述text_prompt = "A cat playing with a ball"generated_text = deepseek_text_generator(text_prompt, max_length=50, num_return_sequences=1)[0]['generated_text']# 根据文本描述生成视频video = video_diffusion(generated_text).videos[0]# 保存生成的视频video.save("generated_video.mp4")print(f"Generated video saved as generated_video.mp4")</code>5.3 多模态检索系统搭建案例以下代码展示了如何使用向量嵌入和检索技术构建一个简单的多模态检索系统:
代码语言:javascript代码运行次数:0运行复制<code class="javascript">from transformers import AutoModel, AutoTokenizerimport torchfrom sklearn.metrics.pairwise import cosine_similarity# 安装依赖:pip install torch transformers scikit-learn# 加载预训练模型和分词器model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")# 函数:将文本或图像嵌入为向量def get_embedding(text_or_image): inputs = tokenizer(text_or_image, return_tensors="pt", padding=True, truncation=True) outputs = model(**inputs) return outputs.last_hidden_state.mean(dim=1).detach().numpy()# 示例:文本和图像的嵌入text_embedding = get_embedding("A cat sitting on a chair")image_embedding = get_embedding("path_to_image.jpg") # 假设支持图像嵌入# 计算相似度similarity = cosine_similarity(text_embedding, image_embedding)print(f"Similarity between text and image: {similarity[0][0]}")</code>这些代码案例展示了如何将DeepSeek与其他模型结合,实现多模态任务的进阶应用。
六、总结与展望
DeepSeek 的多模态能力在图文跨模态对齐、视频理解与生成以及多模态检索系统搭建等方面展现出了卓越的技术实力和广泛的应用价值。通过时空同步对比学习框架和对抗性负样本生成器等创新技术,实现了图文之间的高效对齐;基于 Transformer 架构和生成对抗网络的视频理解与生成统一框架,为视频内容的处理提供了强大的工具;而多模态检索系统的搭建案例则展示了如何将 DeepSeek 技术应用于实际场景,解决信息检索的难题。
展望未来,随着人工智能技术的不断发展,DeepSeek 多模态技术有望在更多领域取得突破。在医疗领域,能够辅助医生更准确地诊断疾病,通过分析医学影像和病历文本,提供更全面的诊断建议;在教育领域,为学生提供个性化的学习体验,根据学生的学习情况和特点,生成定制化的学习内容和指导。相信在不久的将来,DeepSeek 多模态技术将为我们的生活带来更多的便利和惊喜,也期待更多的读者能够深入探索这一领域,共同推动人工智能技术的发展与应用。

感谢您耐心阅读本文。希望本文能为您提供有价值的见解和启发。如果您对[解锁DeepSeek多模态:从原理到实战全解析(3/18)]有更深入的兴趣或疑问,欢迎继续关注相关领域的最新动态,或与我们进一步交流和讨论。让我们共同期待[解锁DeepSeek多模态:从原理到实战全解析]在未来的发展历程中,能够带来更多的惊喜和突破。
再次感谢,祝您拥有美好的一天!





























