







豆包大模型1.6是什么
豆包大模型1.6(doubao-seed-1.6)是字节跳动推出的一款多模态深度思考型大模型。它支持auto、thinking和non-thinking三种模式,能够处理文本、图像、视频等多样输入形式,并输出高质量文字内容。该模型具备256k的长上下文窗口,最大输入长度可达224k tokens,输出长度最高支持16k tokens,推理能力强劲。在多个权威测评中表现优异,尤其在推理与数学能力方面显著提升。该模型广泛应用于内容创作、智能对话、代码生成等领域,为开发者和企业提供强大的ai工具。目前,豆包1.6已上线火山引擎平台,支持api调用。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 豆包大模型1.6的主要功能
豆包大模型1.6的主要功能
- 推理能力:在推理速度、准确性与稳定性方面均有明显增强,适用于更复杂的业务场景。
- 边想边搜与DeepResearch:支持在推理过程中进行信息搜索,结合缺失数据完成推荐;DeepResearch功能可快速生成调研报告。
- 多模态理解能力:全系列原生支持多模态分析,能有效处理文本、图像、视频等多种类型的数据。
- 图形界面操作能力(GUI操作):基于视觉深度思考和精准定位技术,可与浏览器及其他软件交互执行任务。
豆包大模型1.6的三个模型
- doubao-seed-1.6:全能综合型模型,是国内首个支持256K上下文的思考模型。具备深度思考、多模态理解和图形界面操作等多项能力。用户可根据需要灵活开启或关闭深度思考功能,支持自适应模式,根据提示词难度自动切换是否启用深度思考,在提升效果的同时减少tokens消耗。
- doubao-seed-1.6-thinking:深度思考强化版,专注于提升复杂任务处理能力,如代码编写、数学计算、逻辑推理等。同样支持256K上下文,适合需要深入分析和复杂推理的应用场景。
- doubao-seed-1.6-flash:极速响应版本,具备低延迟特性,TOPT(Top-of-Pipeline Time)仅需10ms,响应迅速。支持深度思考与多模态理解,视觉识别能力媲美主流旗舰模型,适合对实时性要求高的应用,如即时交互和视觉任务处理。
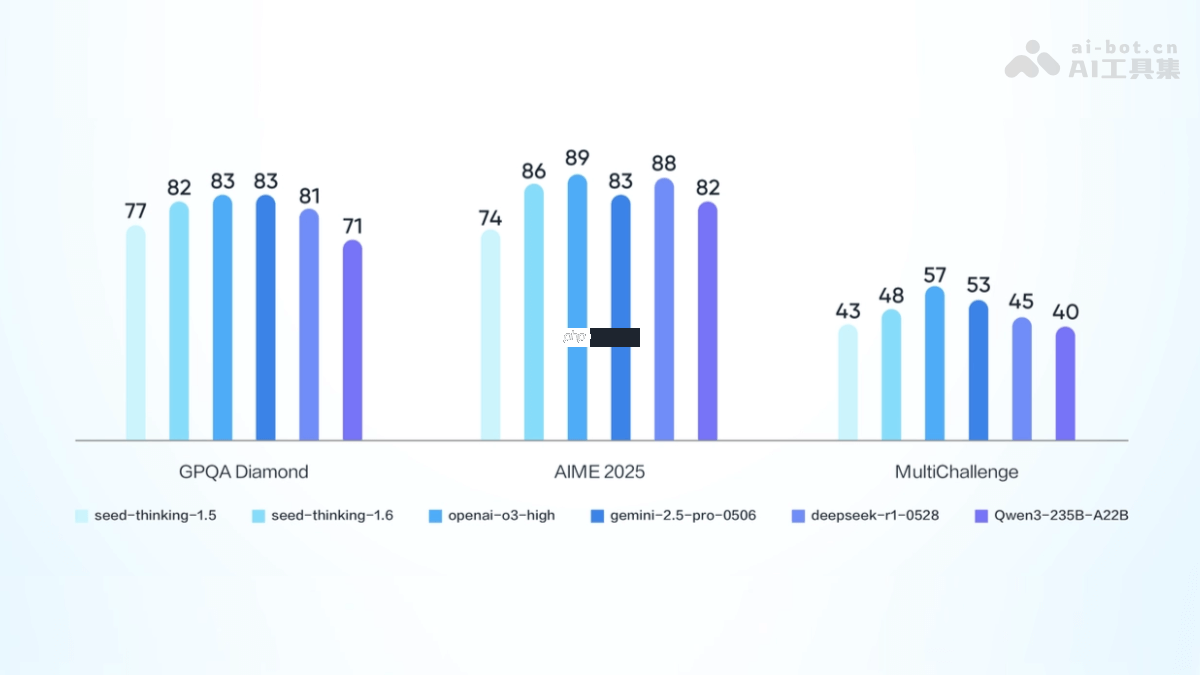
豆包大模型1.6的性能表现
- GPQA Diamond测试:豆包1.6-thinking模型得分81.5,处于全球领先水平,是当前最优的推理模型之一。
- 数学测评AIME25:豆包1.6-thinking模型得分为86.3,较上一代模型提升了12.3分。
 豆包大模型1.6的定价模式
豆包大模型1.6的定价模式
豆包大模型1.6采用统一价格体系,无论是否启用深度思考模式,无论是文本还是视觉输入,均按相同标准计费。
-
输入长度0-32K:
- 输入费用:0.8元/百万tokens。
- 输出费用:8元/百万tokens。
-
输入长度32K-128K:
- 输入费用:1.2元/百万tokens。
- 输出费用:16元/百万tokens。
-
输入长度128K-256K:
- 输入费用:2.4元/百万tokens。
- 输出费用:24元/百万tokens。
-
输入32K、输出200 tokens以内:
- 输入费用:0.8元/百万tokens。
- 输出费用:2元/百万tokens。
如何使用豆包大模型1.6
- 注册并登录火山引擎平台:访问火山引擎官网,按照指引完成注册与登录。
- 开通豆包大模型服务:进入服务页面,找到豆包大模型1.6相关选项。
- 激活服务:依据页面引导完成服务开通。
- 选择模型版本:根据需求选择合适的模型版本,如doubao-seed-1.6、doubao-seed-1.6-thinking或doubao-seed-1.6-flash。
- 获取API密钥:服务开通后,平台将提供一个用于身份验证的API密钥。
-
调用模型接口:
- 通过API调用:豆包大模型1.6以API形式对外提供服务。
- 构造请求体:根据实际需求设置输入内容及参数。
- 发送请求:通过HTTP协议向模型API地址发送请求。
- 接收返回结果:模型处理完成后,返回相应结果数据。
- 示例代码(Python):以下是一个使用Python调用豆包大模型1.6的简单示例:
<code>import requests
import json
<h1>API密钥和接口地址</h1><p>api_key = "your_api_key"
api_secret = "your_api_secret"
model_version = "doubao-seed-1.6" # 或doubao-seed-1.6-thinking、doubao-seed-1.6-flash
api_url = f"<a href="https://www.php.cn/link/dfd1e5f05a19b577a89a80f1cc545b7e">https://www.php.cn/link/dfd1e5f05a19b577a89a80f1cc545b7e</a>}"</p><h1>请求参数</h1><p>data = {
"input": "你的输入文本",
"parameters": {
"max_length": 256, # 输出的最大长度
"temperature": 0.7, # 随机性参数
"top_p": 0.9, # 核心采样参数
"top_k": 50, # 核心采样参数
"do_sample": True # 是否采样
}
}</p><h1>设置请求头</h1><p>headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}</p><h1>发起请求</h1><p>response = requests.post(api_url, headers=headers, data=json.dumps(data))</p><div class="aritcle_card flexRow">
<div class="artcardd flexRow">
<a class="aritcle_card_img" href="/ai/1715" title="Chromox"><img
src="https://img.php.cn/upload/ai_manual/000/000/000/175680315684832.png" alt="Chromox" onerror="this.onerror='';this.src='/static/lhimages/moren/morentu.png'" ></a>
<div class="aritcle_card_info flexColumn">
<a href="/ai/1715" title="Chromox">Chromox</a>
<p>Chromox是一款领先的AI在线生成平台,专为喜欢AI生成技术的爱好者制作的多种图像、视频生成方式的内容型工具平台。</p>
</div>
<a href="/ai/1715" title="Chromox" class="aritcle_card_btn flexRow flexcenter"><b></b><span>下载</span> </a>
</div>
</div><h1>处理返回结果</h1><p>if response.status_code == 200:
result = response.json()
print("模型输出:", result["output"])
else:
print("请求失败,状态码:", response.status_code)
print("错误信息:", response.text)</code>豆包大模型1.6的项目地址
豆包大模型1.6的应用场景
- 内容创作:可用于生成广告文案、新闻稿、故事、小说等内容,帮助用户高效产出优质文本。
- 智能对话:适用于智能客服与聊天机器人系统,提供自然流畅的多轮对话体验,提升用户互动效率。
- 代码生成:根据需求生成前端代码片段,辅助开发者排查问题,加快开发进度。
- 教育辅导:解答各类学科问题,生成教学材料,辅助学生学习和教师备课。
- 多模态内容生成:结合图像或视频输入,生成配套的文字描述或创意内容,助力多媒体内容创作。





























