






在ai图像生成领域,通义万相2.1作为领先的扩散模型,其官方api虽功能强大,但定制能力有限。lora(low-rank adaptation)技术正是解决这一痛点的关键钥匙——它允许开发者以极低成本实现模型个性化定制。本文将详细解析训练通义万相2.1 lora的全流程,助你掌握定制专属ai艺术家的核心技能。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
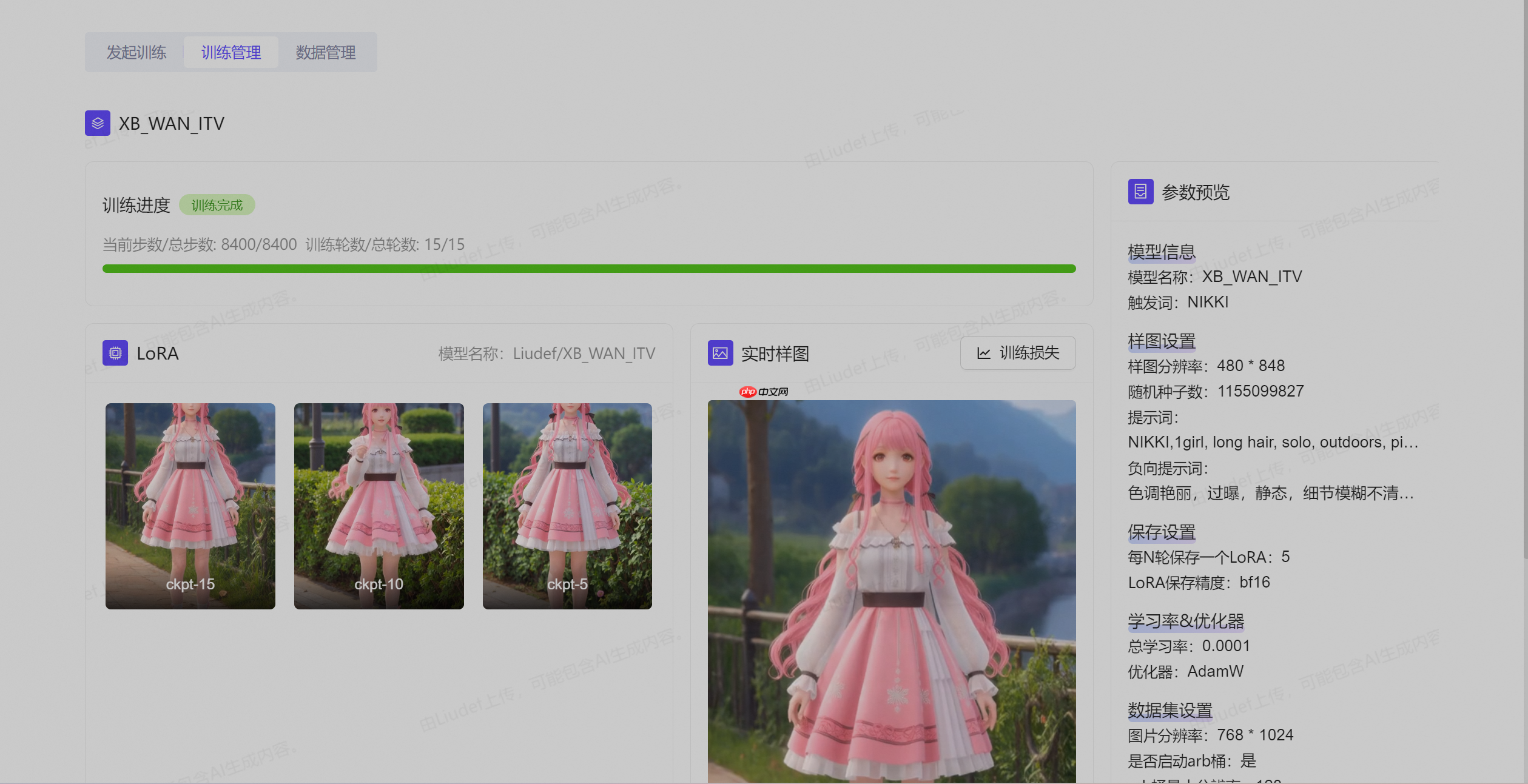
一、 认识通义万相2.1与LoRA
1.1 通义万相2.1 核心特性
- 多模态理解:精准解析复杂文本提示(Prompt)
- 高分辨率输出:支持1024×1024及以上分辨率生成
- 艺术风格覆盖:涵盖写实、二次元、国风等十余种风格
- 细节增强:改进的纹理生成与光影处理算法
1.2 LoRA技术原理剖析
传统微调需更新数十亿参数,而LoRA采用低秩分解技术:
W' = W + ΔW = W + BA^T
其中:
- W:原始权重矩阵(d×k维)
- B:低秩矩阵(d×r维)
- A:低秩矩阵(r×k维)
- r:关键的超参数rank(秩),通常 r
优势对比:
| 方法 | 参数量 | 存储空间 | 训练速度 | 切换效率 |
|---|---|---|---|---|
| 全量微调 | 100% | 10GB+ | 慢 | 低 |
| LoRA | 0.1%-1% | 1-100MB | 快5-10倍 | 秒级切换 |
二、 训练环境与工具准备
2.1 硬件要求建议
| 设备 | 最低配置 | 推荐配置 |
|---|---|---|
| GPU | RTX 3060 (12GB) | RTX 4090 (24GB) |
| VRAM | 12GB | 24GB+ |
| RAM | 16GB | 32GB+ |
| 存储 | 50GB SSD | 1TB NVMe SSD |
2.2 核心软件栈
# 创建Python虚拟环境 conda create -n wanxiang-lora python=3.10 conda activate wanxiang-lora # 安装关键库 pip install torch==2.1.0+cu121 -f https://download.pytorch.org/whl/torch_stable.html pip install diffusers transformers accelerate peft xformers pip install datasets pillow tensorboard
2.3 模型获取
from diffusers import StableDiffusionPipeline model_path = "wanxiang/wanxiang-v2.1" pipe = StableDiffusionPipeline.from_pretrained(model_path)
三、 数据集构建黄金法则
3.1 数据要求明细
| 指标 | 最低标准 | 优质标准 |
|---|---|---|
| 图片数量 | 20张 | 50-100张 |
| 分辨率 | 512×512 | ≥1024×1024 |
| 标注一致性 | 基础描述 | 结构化Prompt |
3.2 标注模板示例
{subject} {action}, {art_style} style,
{lighting}, {composition},
detailed {texture}, color scheme: {colors}
实例:

“赛博朋克少女站在霓虹街头,未来主义风格,霓虹灯光与雾气效果,中心构图,皮革与金属质感,主色调:紫色/蓝色/荧光绿”
3.3 数据增强技巧
from albumentations import * transform = Compose([ RandomResizedCrop(512, 512, scale=(0.8, 1.0)), HorizontalFlip(p=0.5), ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2), GaussNoise(var_limit=(10, 50)), ])
四、 LoRA训练全流程详解
4.1 配置文件关键参数
# lora_config.yaml rank: 64 # 核心维度参数 (8-128) alpha: 32 # 缩放因子 (通常=rank) target_modules: # 注入位置- "to_k"- "to_v"- "to_q"- "ff.net.0.proj" dropout: 0.05 bias: "none"
4.2 训练脚本核心代码
from peft import LoraConfig, get_peft_model # 创建LoRA配置 lora_config = LoraConfig( r=args.rank, lora_alpha=args.alpha, target_modules=target_modules, lora_dropout=args.dropout ) # 注入LoRA到模型 model.unet = get_peft_model(model.unet, lora_config) # 优化器配置 optimizer = torch.optim.AdamW( model.unet.parameters(), lr=1e-4, weight_decay=1e-4 ) # 训练循环 for epoch in range(epochs): for batch in dataloader: clean_images = batch["images"] latents = vae.encode(clean_images).latent_dist.sample() noise = torch.randn_like(latents) timesteps = torch.randint(0, 1000, (len(latents),)) noisy_latents = scheduler.add_noise(latents, noise, timesteps) noise_pred = model.unet(noisy_latents, timesteps).sample loss = F.mse_loss(noise_pred, noise) loss.backward() optimizer.step() optimizer.zero_grad()
4.3 关键训练参数推荐
| 参数 | 值域范围 | 推荐值 | 作用说明 |
|---|---|---|---|
| Rank ® | 8-128 | 64 | 控制模型复杂度 |
| Batch Size | 1-8 | 2 (24GB显存) | 影响训练稳定性 |
| Learning Rate | 1e-5 to 1e-4 | 1e-4 | 学习步长 |
| Steps | 500-5000 | 1500 | 迭代次数 |
| Warmup Ratio | 0.01-0.1 | 0.05 | 初始学习率预热 |
五、 模型测试与应用部署
5.1 LoRA权重加载
from diffusers import StableDiffusionPipeline
import torch
pipeline = StableDiffusionPipeline.from_pretrained( "wanxiang/wanxiang-v2.1", torch_dtype=torch.float16
)
pipeline.unet.load_attn_procs("lora_weights.safetensors")
pipeline.to("cuda")
# 生成图像
image = pipeline( "A robot painting in Van Gogh style, lora_weight=0.8", guidance_scale=7.5, num_inference_steps=50
).images[0]
5.2 权重融合技巧
# 将LoRA权重合并到基础模型
merged_model = pipeline.unet
for name, module in merged_model.named_modules(): if hasattr(module, "merge_weights"): module.merge_weights(merge_alpha=0.85) # 融合比例调节
# 保存完整模型
merged_model.save_pretrained("wanxiang_van_gogh_robot")
六、 高级调优策略
6.1 解决常见训练问题
| 问题现象 | 诊断方法 | 解决方案 |
|---|---|---|
| 过拟合 | 验证集loss上升 | 增加Dropout/L2正则化 |
| 欠拟合 | 训练loss停滞 | 增大Rank/延长训练时间 |
| 风格迁移不足 | 生成结果偏离目标 | 增强数据一致性/调整prompt权重 |
6.2 小资源训练技巧
# 启用8-bit优化器 accelerate launch --config_file config.yaml train.py \--use_8bit_adam # 梯度累积技术 training_args = TrainingArguments( per_device_train_batch_size=1, gradient_accumulation_steps=4, ) # 混合精度训练 torch.cuda.amp.autocast(enabled=True)
七、 实战案例:动漫角色IP训练
7.1 数据准备
- 素材收集:50张统一画风的角色三视图
-
标注规范:
[character_name] full body, {pose_description}, {background}, anime style by [artist_name]
7.2 训练参数
rank: 96 steps: 2000 lr_scheduler: cosine_with_warmup lr_warmup_steps: 100 prompt_template: "best quality, masterpiece, illustration, [character_name]"
7.3 生成效果对比
原始模型: "an anime girl with blue hair" + LoRA后:"Skye from Neon Genesis, aqua hair with glowing tips, mecha suit design, signature pose, studio Ghibli background"
结语:掌握LoRA的核心价值
通过LoRA微调通义万相2.1,开发者能以低于1%的参数量实现模型深度定制。关键技术要点包括:
- 数据质量决定上限:精心构建30-100张标注图像数据集
- Rank参数需平衡:64-128范围适合多数风格迁移任务
- 渐进式训练策略:从低学习率开始逐步提升强度
- 混合权重应用:通过lora_weight=0.5~0.9调节风格强度
随着工具链的持续优化,LoRA训练正从专家技能转变为标准工作流。最新进展表明,阿里云正在研发一站式LoRA训练平台,未来可通过WebUI实现零代码微调,进一步降低技术门槛。
实践建议:首次训练建议从rank=32的小规模实验开始,使用15-20张图片进行500步快速迭代,验证流程后再进行完整训练。每次实验应记录参数组合,建立自己的调参知识库。
附:训练监控命令
# 监控GPU状态 watch -n 1 nvidia-smi # 启动TensorBoard tensorboard --logdir=./logs --port 6006




























