







efficientnetv2 是由 google research 的 brain team 在 2021 年 icml 会议上发布的一篇论文。该论文通过神经架构搜索(nas)和缩放技术,优化了训练速度和参数效率。模型中引入的新操作,如 fused-mbconv,进一步提升了搜索空间的效率。efficientnetv2 模型的训练速度比 efficientnetv1 快得多,同时模型大小缩小了 6.8 倍。
论文大纲如下:
-
理解和提高 EfficientNetV1 的训练效率
- 使用非常大的图像尺寸进行训练会导致训练速度变慢。
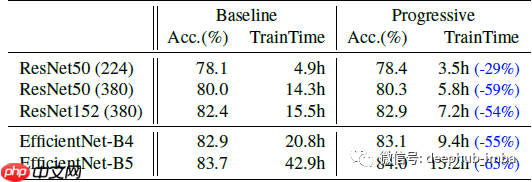
- FixRes 技术通过使用较小的图像尺寸进行训练,可以将训练速度提高多达 2.2 倍,同时提高准确度。
- Depth-wise 卷积在模型早期层执行缓慢,但在后期层效率较高。
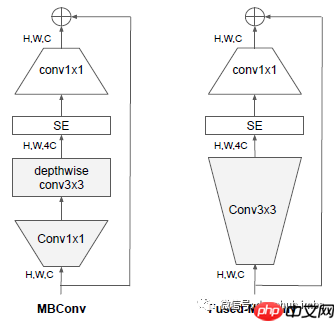
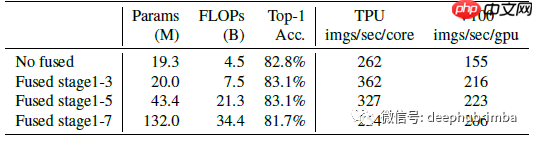
- Fused-MBConv 操作通过将 MBConv 中的 depthwise conv3×3 和扩展 conv1×1 替换为单个常规 conv3×3,提高了训练速度。

- 在每个阶段同样扩大规模并不是最优的。EfficientNetV2 使用非均匀缩放策略,向模型后期逐渐添加更多层,并限制最大图像尺寸以减少内存消耗和加快训练速度。
-
NAS 和缩放
- NAS 搜索空间类似于 PNASNet,通过 NAS 进行卷积运算类型的设计选择,包括层数、内核大小、扩展比等。
- 通过减少图像尺寸和优化搜索空间,EfficientNetV2 实现了更快的训练速度和更高的准确度。
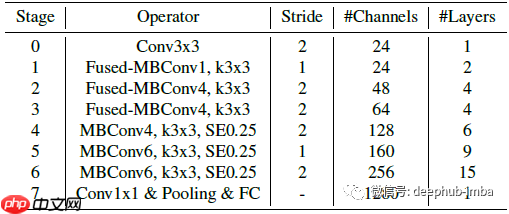
- EfficientNetV2 在早期层中广泛使用了 MBConv 和 Fused-MBConv,并更倾向于使用较小的扩展比和内核大小。
- 缩放策略中,EfficientNetV2-S 通过复合缩放比例放大得到 EfficientNetV2-M/L,并限制最大推理图像大小为 480。
-
Progressive Learning
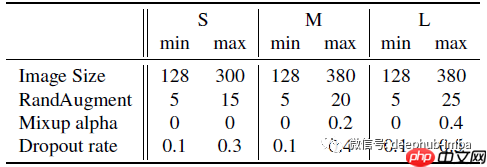
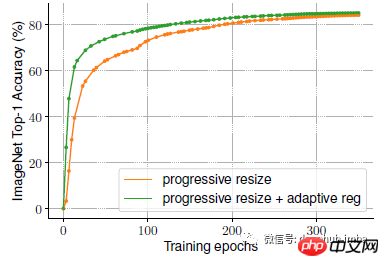
- 通过从小图像尺寸和弱正则化开始,逐渐增加学习难度,提高了模型的表现。




-
SOTA 比较
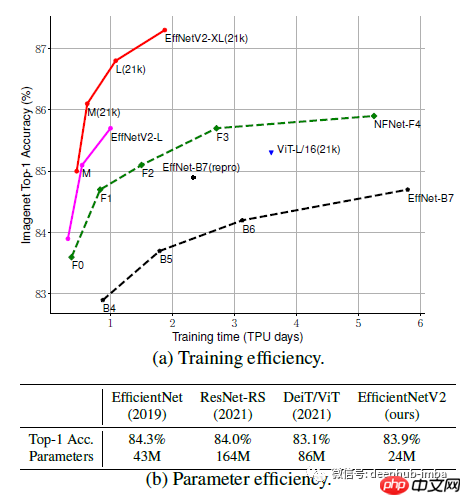
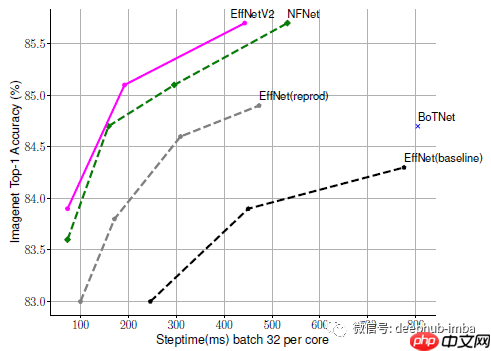
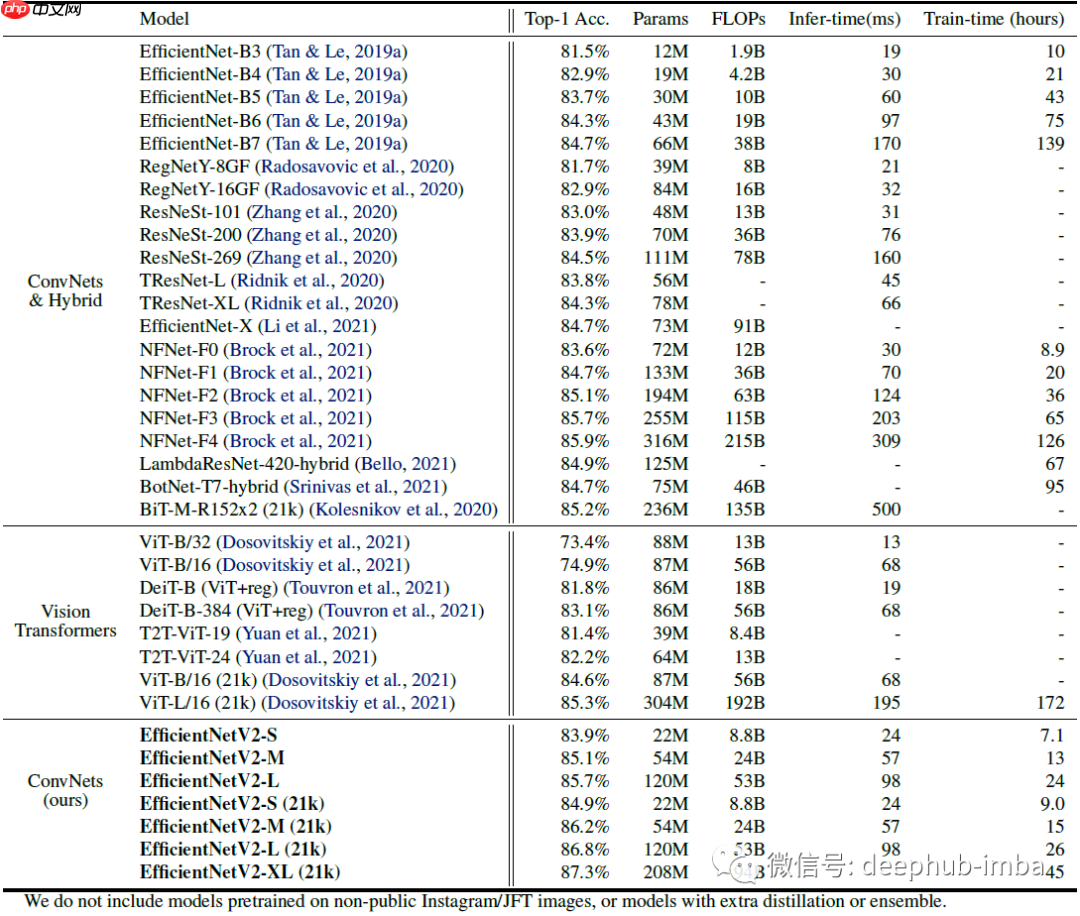
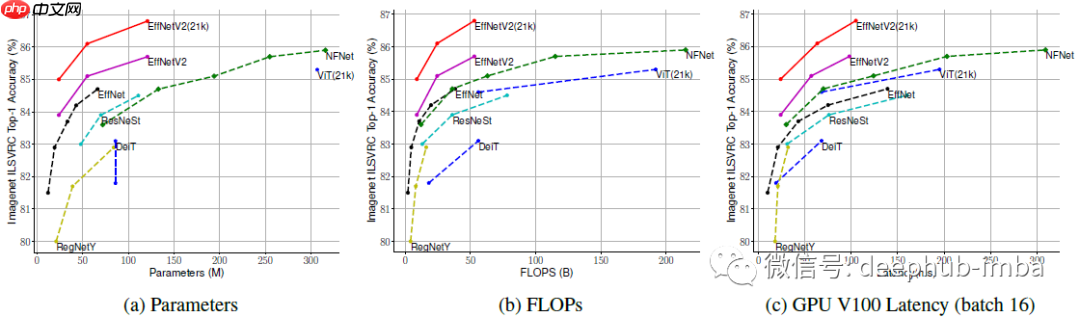
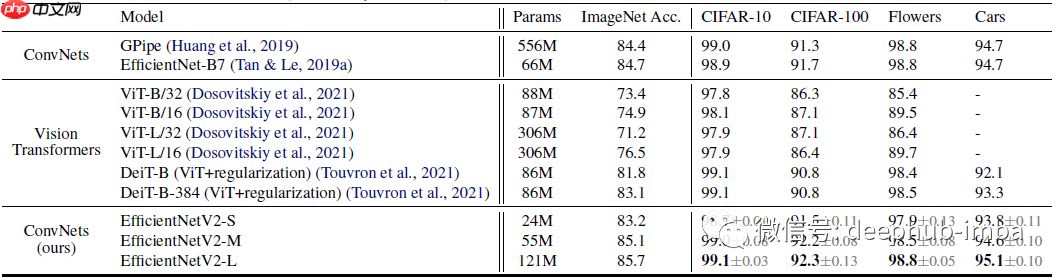
- 在 ImageNet 上,EfficientNetV2 模型比之前的 ConvNets 和 Transformer 模型速度更快,精度和参数效率更高。
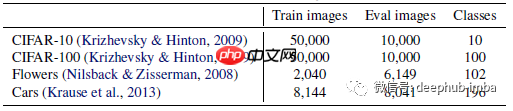
- 在迁移学习测试中,EfficientNetV2 模型在多个数据集上表现优于之前的模型。
-
消融研究
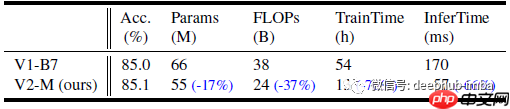
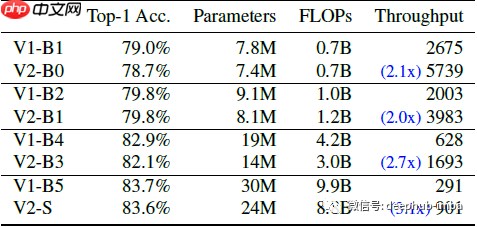
- 在相同学习设置下,EfficientNetV2 模型的性能优于 EfficientNets。
- 通过模型缩放和 Progressive Learning,EfficientNetV2 模型在训练速度和准确性上表现出色。
- 自适应正则化在早期训练阶段使用较小的正则化,帮助模型更快收敛并获得更好的最终精度。

引用[2021 ICML] [EfficientNetV2]EfficientNetV2: Smaller Models and Faster Training




























