






传统的文本搜索通过统计学的方法对文本进行特征度量,但这仅考虑了文本的表面特征。DPR通过将文本的一般表示,即,高维空间下的稀疏向量,转化为富含语言知识和文本信息的低维空间下的稠密向量,来实现文本的近似搜索。DPR在问答系统、搜索系统等多个领域得到了应用。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

基于RocketQA实现文本搜索
传统的文本搜索通过统计学的方法对文本进行特征度量,但这仅考虑了文本的表面特征。DPR通过将文本的一般表示,即,高维空间下的稀疏向量,转化为富含语言知识和文本信息的低维空间下的稠密向量,来实现文本的近似搜索。DPR在问答系统、搜索系统等多个领域得到了应用。
在信息搜索领域,如果能够通过编码器将文本映射到具体的语义空间,每段文本对应在该空间下的向量,那么信息搜索问题便可转化为在给定空间下向量间的最近邻搜索问题。
Dual encoder架构使用两个bert系模型,query model和context model分别将问题和对应的查找文本映射到768维的语义空间。为保证在实际检索过程中的精度,其训练策略为尽可能使问题和对应的文本之间的距离接近,而与无关的问题间的距离拉远。Cross model则使用一个bert系模型同时对问题和文本进行编码。
RocketQA为百度在Dense Passage Retrieval的基础上对训练策略进行优化和改进得到的模型。一般的训练策略为:对于给定问题文本,使其在空间中的表示尽可能靠近正样本同时远离负样本。In batch训练策略则将同一批次内除正样本之外的其他样本均视为负样本。相比于在同一批次内进行采样,RocketQA使用了跨批次的负采样策略。实验证明,适当增大batch size可以较好的提高模型的性能。除此之外,考虑到在实际应用中,实际召回的错误样本多数为人为因素导致的,如漏标、错标等情况,为尽可能降低假负例对模型效果的影响,RocketQA使用cross model对文本进行打分,借此来筛去部分不符合要求的标注数据。同时,RocketQA也使用交互模型来得到更多相关的弱监督数据帮助其训练。
一、数据集简介
本项目使用2022语言与智能技术竞赛:段落检索比赛的数据集来实现模型索引库的建立。
数据集官网介绍:
“近年来,得益于带有高质量人工标注的大规模段落检索数据集的出现,基于稠密向量的表示学习方法在段落检索领域取得了重大进展。 然而,由于缺乏相应的大规模中文检索数据集,在中文场景下应用稠密检索模型的相关研究受到了极大的限制。为了推动中文段落检索技术的发展,我们利用真实场景下的用户搜索日志,建立了首个大规模高质量中文段落检索数据集:DuReader_retrieval,并采用多路集成召回标注及训练、测试集语义去重等策略,提升了开发集和测试集的标注质量,保证评估的效果。DuReader_retrieval中的样本均来自于实际的应用场景,考察点丰富多样,覆盖了真实应用场景下诸多难以解决的问题。”
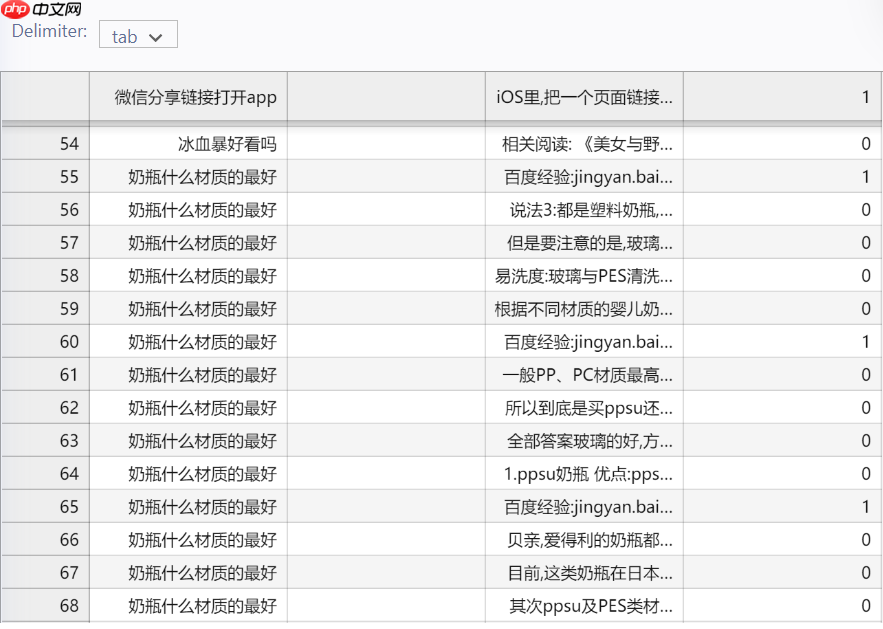
数据样例:
定义数据集加载方式
为保证内存的合理使用,这里使用迭代器的方法来返回数据。
def read_file(file_name):
lines = 0
with open(file_name) as f: for ln,line in enumerate(f):
one,two,three,four = line.strip().split('\t')
doc = Document(
text = three
)
lines = lines + 1
yield doc二、Executor建立
JINA提供了一整套搭建搜索系统的开源工具,其主要产品为DocumentArray,Executor和Flow。DocumentArray为基础数据结构,Executor负责对DocumentArray进行处理,Flow则提供整个工作流程。
!pip install rocketqa !pip install jina
import rocketqafrom docarray import Document,DocumentArrayfrom jina import Executor,requests,Flowimport osfrom multiprocessing import set_start_method as _set_start_methodimport numpy as npimport sysfrom pathlib import Pathimport time
文本问答的主要流程为:召回(retriever),重排(reranker)和阅读理解(reader)。在召回阶段,本项目使用RocketQA(dual model)将问题映射为一向量,之后近似最近邻搜索系统会在已有的索引库中搜索与之距离最近的向量,并返回top-k;在重排阶段,本项目使用RocketQA(cross model)对召回向量进行打分,最后根据排序返回最终得分前三的文本。
2.1 RocketqaDeExecutor
本项目使用RocketqaDe模型来实现第一阶段。在index建立索引库时,Executor将输入的content文本编码为语义向量,并将其嵌入Document中;在search搜索时,Executor将输入的待查询问题编码为语义向量。
class RocketqaDeExecutor(Executor):
def __init__(self,model_name="zh_dureader_de",use_Cuda=True,device_Id=0,batch_Size=32,*args,**kwargs):
super().__init__(*args, **kwargs)
self.model = rocketqa.load_model(model=model_name,use_cuda=True,device_id=device_Id,batch_size=batch_Size) @requests(on="/index")
def encode_passage(self,docs:DocumentArray,**kwargs):
embeddings = self.model.encode_para(para=docs.texts)
docs.embeddings = [embedding for embedding in embeddings] #docs.embeddings = embeddings
@requests(on="/search")
def encode_query(self,docs,**kwargs):
print("retriever is working......")
start = time.time() for doc in docs:
generator_temp = self.model.encode_query(query=[doc.text]) for temp in generator_temp:
doc.embedding = temp
end = time.time() print("retrieve time: ",end-start,"s")2.2 rocketqaCeExecutor
本项目使用RocketqaCe模型来实现第二阶段的打分重拍。在search阶段,该Executor将前一步处理后得到嵌入词向量与问题向量一起处理,得到每条召回结果的分数,并根据分数具体排名。在index阶段,该Executor不参与工作。
class RocketqaCeExecutor(Executor):
def __init__(self,model_Name="zh_dureader_ce",use_Cuda=True,device_Id=0,batch_Size=32,*args,**kwargs):
super().__init__(*args,**kwargs)
self.model = rocketqa.load_model(model=model_Name,use_cuda=True,device_id=device_Id,batch_size=batch_Size) @requests(on="/search")
def rerank(self,docs,**kwargs):
print("reranker is working......") print("召回结果排序中......")
start = time.time() for doc in docs:
str_list = [] for m in doc.matches:
str_list.append(m.text)
doc.matches = []
scores = []
score_generator = self.model.matching(query=[doc.text]*len(str_list),para=str_list) for g in score_generator:
scores.append(g)
scores = np.array(scores).argsort()
doc.matches.append(Document(text=str_list[scores[-1]]))
doc.matches.append(Document(text=str_list[scores[-2]]))
doc.matches.append(Document(text=str_list[scores[-3]]))
end = time.time() print("rerank time:",end-start,"s")三、Indexer建立
Indexer在index建立索引阶段将得到的嵌入语义向量存入docs中,之后,在search搜索阶段,将问题向量与索引库中的向量对比,最终得到top-k召回结果。
class Indexer(Executor):
_docs = DocumentArray()
@requests(on='/index')
def foo(self, docs: DocumentArray, **kwargs):
print("it is ok")
self._docs.extend(docs)
@requests(on='/search')
def bar(self, docs: DocumentArray, **kwargs):
print("all is well")
docs.match(self._docs, metric='euclidean', limit=20)四、workflow建立
将上述三个Executor组建成一个Flow便可实现整体项目的搭建。
test_flow = (
Flow()
.add(
name = "test",
uses=RocketqaDeExecutor
)
.add(
uses="jinahub://SimpleIndexer/v0.15", install_requirements=True, name="indexer"
)
.add(
uses=RocketqaCeExecutor,
name="rerank"
)
)五、main启动函数
即使在使用GPU的情况下,每次建立索引也会消耗大量时间。本项目使用以下函数来实现在运行时单独执行建立索引库和搜索阶段。
def main(order):
if order == 'index': if Path('./workspace').exists(): print('./workspace exists, please deleted it if you want to reindexi') return 0
data_path = sys.argv[2] if data_path is None: print("No data_path!")
index(data_path) elif order == 'query':
query()def index(path):
with test_flow:
test_flow.index(inputs=read_file(path), show_progress=True)def query():
with test_flow: while(True):
query = input("请输入查询选项:") if query == "exit": break
query = Document(text=query)
docs = test_flow.search(inputs=query)
matches = docs[0].matches print("搜索答案为:")
ids = 1
for match in matches: print("推荐答案排行,NO.",ids) print(match.text)
ids = ids + 1

!python wow.py temp_data/cross.train.demo.tsv#运行该指令来执行建库操作
!python wow.py query#运行该指令来执行索引操作




























