






《Going deeper with Image Transformers》针对图像Transformer优化少的问题,研究构建和优化更深网络。提出LayerScale,在残差块输出乘对角线矩阵,改善训练动态以训练更深模型;设计类别注意力层,分离patch自注意与信息总结。所建CaiT模型在图像分类任务中表现出色。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

引入
- Transformer 最近已在大规模图像分类任务中获得了很高的分数,这逐渐动摇了卷积神经网络的长期霸主地位。
- 但是,到目前为止,对图像 Transformer 的优化还很少进行研究。
- 在这项工作中,作者为图像分类建立和优化了更深的 Transformer 网络。
- 特别是,我们研究了这种专用 Transformer 的架构和优化之间的相互作用。
相关资料
- 论文:Going deeper with Image Transformers
- 官方实现:facebookresearch/deit
主要改进
- 这篇论文基于 ViT 和 DeiT 进行研究,探索实现更深层的 Image Transformer 模型的训练,主要有以下两点改进:
- 使用 LayerScale 实现更深层的 Image Transformer 模型(Deeper image transformers with LayerScale)
- 特别设计的类别注意力层(Specializing layers for class attention)
使用 LayerScale 实现更深层的 Image Transformer 模型
原理介绍
- Vision Transformer 展示了一种特殊形式的残差结构:在将输入图像转换成一组向量之后,网络将自注意层(SA)与前馈网络(FFN)交替,如下所示:
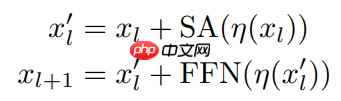 (公式 1)
(公式 1)
其中 η 代表 LayerNorm
- 但是这种结构无法很好的训练更深层的网络模型,在分析了不同的初始化、优化和体系结构设计之间的相互作用之后,作者提出了一种方法
- 与现有的方法相比,这种方法可以有效地提高更深层的 Image Transformer 模型的训练效果
- 形式上,在每个残差块的输出上添加一个可学习的对角矩阵,初始化接近于 0
- 在每个残差块之后添加这个简单的层提高了训练动态性,允许我们训练更深层的受益于深度的大容量 Image Transformer 模型
- 作者将这种方法称为 LayerScale (d),具体的结构对比示意图如下:
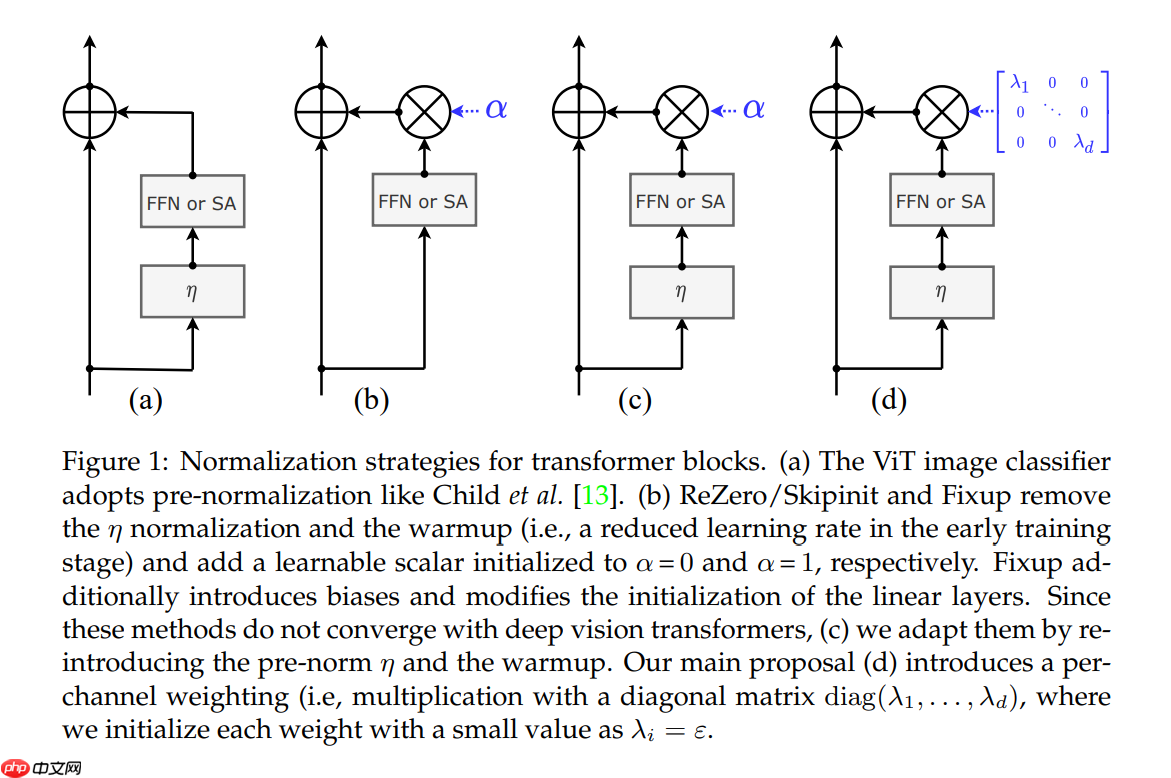
- 作者建议的 LayerScale 是由每个残差块产生的向量的每通道相乘,而不是单个标量,见上图(d)。
- 目标是将与同一输出通道相关联的权重的更新分组
- 形式上,LayerScale 是在每个残差块的输出上乘以对角线矩阵,换言之,作者修改了上述的公式 1:
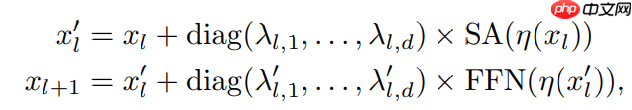
其中
和
为可学习参数

ε 为对角线值的初始化值,一般为一个较小的数,作者设置为 ε=0.1 当深度小于等于 18 时,ε=10−5 当深度小于等于 24 时,和 ε=10−6 当深度大于 24 时
η 代表 LayerNorm
代码实现
class LayerScale_Block(nn.Layer):
# with slight modifications to add layerScale
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, epsilon=1e-6,
Attention_block=Attention_talking_head, Mlp_block=Mlp, init_values=1e-4):
super().__init__()
self.norm1 = norm_layer(dim, epsilon=epsilon)
self.attn = Attention_block(
dim,
num_heads=num_heads,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
attn_drop=attn_drop,
proj_drop=drop
)
self.drop_path = DropPath(drop_path) if drop_path > 0. else Identity()
self.norm2 = norm_layer(dim, epsilon=epsilon)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp_block(
in_features=dim,
hidden_features=mlp_hidden_dim,
act_layer=act_layer,
drop=drop
) # 创建 LayerScale 的两个可学习参数
# 使用 init_values 初始化这两个参数
self.gamma_1 = add_parameter(self, init_values * paddle.ones((dim,)))
self.gamma_2 = add_parameter(self, init_values * paddle.ones((dim,))) def forward(self, x):
x = x + self.drop_path(self.gamma_1 * self.attn(self.norm1(x)))
x = x + self.drop_path(self.gamma_2 * self.mlp(self.norm2(x))) return x特别设计的类别注意力层
原理介绍
- 该设计旨在规避 ViT 体系结构的一个问题,学习的权重被要求优化两个矛盾的目标:
- 引导 patch 之间的自注意
- 总结信息对线性分类器有用
- 作者建议是按照 Encoder-Decoder 体系结构的思想,显式地分离这两个阶段
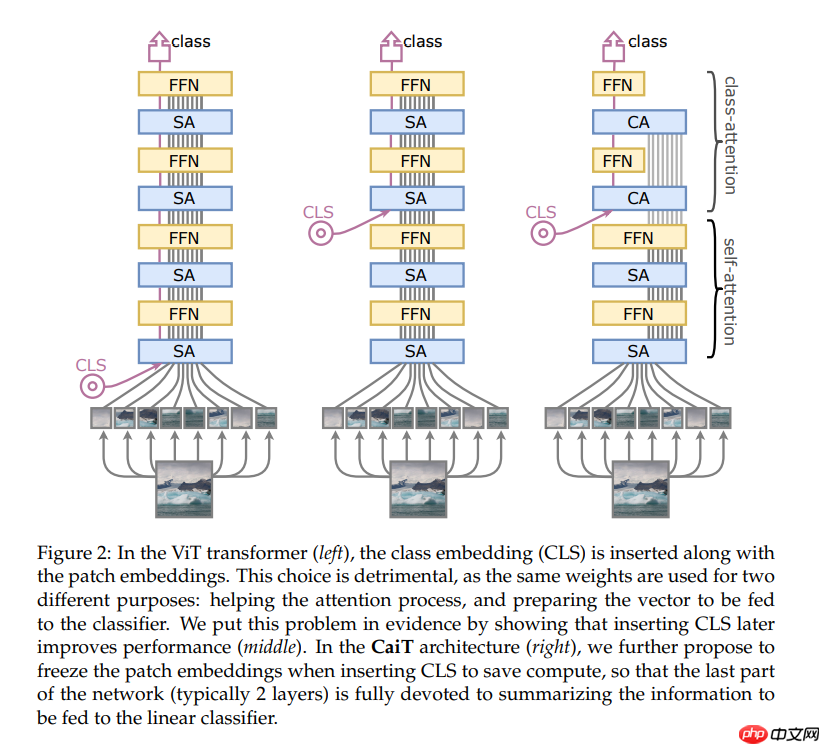
- 后置类别标记(Later class token):作者在 transformer 网络的中途添加 class token,这种选择消除了 transformer 第一层上的差异,因此完全用于在 patch 之间执行自注意
- 在结构上 CaiT 网络由两个不同的处理阶段组成,如下图所示:
- self-attention stage 与 ViT 的 transformer 相同,但没有类嵌入 (CLS)
- class-attention stage 是一组层,它将一组 patch 嵌入到一个类嵌入 CLS 中,后者随后被提供给一个线性分类器
代码实现
# Class Attention class Class_Attention(nn.Layer):
# with slight modifications to do CA
def __init__(self, dim, num_heads=8, qkv_bias=False,
qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.q = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.k = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.v = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop) def forward(self, x):
# 输入是 [cls token, x]
# 输出是计算 attention 之后的 cls token
# 在多层堆叠的时候后面的 x 一直是不变的
B, N, C = x.shape
# query 只取 cls token
q = self.q(x[:, 0]).unsqueeze(1).reshape(
(B, 1, self.num_heads, C // self.num_heads)
).transpose((0, 2, 1, 3))
k = self.k(x).reshape(
(B, N, self.num_heads, C // self.num_heads)
).transpose((0, 2, 1, 3))
q = q * self.scale
v = self.v(x).reshape(
(B, N, self.num_heads, C // self.num_heads)
).transpose((0, 2, 1, 3))
attn = q.matmul(k.transpose((0, 1, 3, 2)))
attn = nn.functional.softmax(attn, axis=-1)
attn = self.attn_drop(attn)
x_cls = (attn.matmul(v)).transpose((0, 2, 1, 3)).reshape((B, 1, C))
x_cls = self.proj(x_cls)
x_cls = self.proj_drop(x_cls) return x_cls# 结合 LayerScale 和 Class Attentionclass LayerScale_Block_CA(nn.Layer):
# with slight modifications to add CA and LayerScale
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, epsilon=1e-6,
Attention_block=Class_Attention, Mlp_block=Mlp, init_values=1e-4):
super().__init__()
self.norm1 = norm_layer(dim, epsilon=epsilon)
self.attn = Attention_block(
dim,
num_heads=num_heads,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
attn_drop=attn_drop,
proj_drop=drop
)
self.drop_path = DropPath(drop_path) if drop_path > 0. else Identity()
self.norm2 = norm_layer(dim, epsilon=epsilon)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp_block(
in_features=dim,
hidden_features=mlp_hidden_dim,
act_layer=act_layer,
drop=drop
)
self.gamma_1 = add_parameter(self, init_values * paddle.ones((dim,)))
self.gamma_2 = add_parameter(self, init_values * paddle.ones((dim,))) def forward(self, x, x_cls):
# 拼接 cls token 和 输入
u = paddle.concat((x_cls, x), axis=1)
# Class Attention + FFN
x_cls = x_cls + self.drop_path(self.gamma_1 * self.attn(self.norm1(u)))
x_cls = x_cls + self.drop_path(self.gamma_2 * self.mlp(self.norm2(x_cls))) return x_cls模型搭建
- 上面介绍了 CaiT 模型的一些重要的改进点
- 接下来就完整地搭建一下模型
模型组网
In [ ]
import paddleimport paddle.nn as nnfrom common import add_parameterfrom common import trunc_normal_, zeros_, ones_from common import DropPath, Identity, Mlp, PatchEmbedclass Class_Attention(nn.Layer):
# with slight modifications to do CA
def __init__(self, dim, num_heads=8, qkv_bias=False,
qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.q = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.k = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.v = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop) def forward(self, x):
B, N, C = x.shape
q = self.q(x[:, 0]).unsqueeze(1).reshape(
(B, 1, self.num_heads, C // self.num_heads)
).transpose((0, 2, 1, 3))
k = self.k(x).reshape(
(B, N, self.num_heads, C // self.num_heads)
).transpose((0, 2, 1, 3))
q = q * self.scale
v = self.v(x).reshape(
(B, N, self.num_heads, C // self.num_heads)
).transpose((0, 2, 1, 3))
attn = q.matmul(k.transpose((0, 1, 3, 2)))
attn = nn.functional.softmax(attn, axis=-1)
attn = self.attn_drop(attn)
x_cls = (attn.matmul(v)).transpose((0, 2, 1, 3)).reshape((B, 1, C))
x_cls = self.proj(x_cls)
x_cls = self.proj_drop(x_cls) return x_clsclass LayerScale_Block_CA(nn.Layer):
# with slight modifications to add CA and LayerScale
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, epsilon=1e-6,
Attention_block=Class_Attention, Mlp_block=Mlp, init_values=1e-4):
super().__init__()
self.norm1 = norm_layer(dim, epsilon=epsilon)
self.attn = Attention_block(
dim,
num_heads=num_heads,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
attn_drop=attn_drop,
proj_drop=drop
)
self.drop_path = DropPath(drop_path) if drop_path > 0. else Identity()
self.norm2 = norm_layer(dim, epsilon=epsilon)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp_block(
in_features=dim,
hidden_features=mlp_hidden_dim,
act_layer=act_layer,
drop=drop
)
self.gamma_1 = add_parameter(self, init_values * paddle.ones((dim,)))
self.gamma_2 = add_parameter(self, init_values * paddle.ones((dim,))) def forward(self, x, x_cls):
u = paddle.concat((x_cls, x), axis=1)
x_cls = x_cls + self.drop_path(self.gamma_1 * self.attn(self.norm1(u)))
x_cls = x_cls + self.drop_path(self.gamma_2 * self.mlp(self.norm2(x_cls))) return x_clsclass Attention_talking_head(nn.Layer):
# with slight modifications to add Talking Heads Attention (https://arxiv.org/pdf/2003.02436v1.pdf)
def __init__(self, dim, num_heads=8, qkv_bias=False,
qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias_attr=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_l = nn.Linear(num_heads, num_heads)
self.proj_w = nn.Linear(num_heads, num_heads)
self.proj_drop = nn.Dropout(proj_drop) def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(
(B, N, 3, self.num_heads, C // self.num_heads)
).transpose((2, 0, 3, 1, 4))
q, k, v = qkv[0] * self.scale, qkv[1], qkv[2]
attn = (q.matmul(k.transpose((0, 1, 3, 2))))
attn = self.proj_l(attn.transpose((0, 2, 3, 1))).transpose((0, 3, 1, 2))
attn = nn.functional.softmax(attn, axis=-1)
attn = self.proj_w(attn.transpose((0, 2, 3, 1))).transpose((0, 3, 1, 2))
attn = self.attn_drop(attn)
x = (attn.matmul(v)).transpose((0, 2, 1, 3)).reshape((B, N, C))
x = self.proj(x)
x = self.proj_drop(x) return xclass LayerScale_Block(nn.Layer):
# with slight modifications to add layerScale
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, epsilon=1e-6,
Attention_block=Attention_talking_head, Mlp_block=Mlp, init_values=1e-4):
super().__init__()
self.norm1 = norm_layer(dim, epsilon=epsilon)
self.attn = Attention_block(
dim,
num_heads=num_heads,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
attn_drop=attn_drop,
proj_drop=drop
)
self.drop_path = DropPath(drop_path) if drop_path > 0. else Identity()
self.norm2 = norm_layer(dim, epsilon=epsilon)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp_block(
in_features=dim,
hidden_features=mlp_hidden_dim,
act_layer=act_layer,
drop=drop
)
self.gamma_1 = add_parameter(self, init_values * paddle.ones((dim,)))
self.gamma_2 = add_parameter(self, init_values * paddle.ones((dim,))) def forward(self, x):
x = x + self.drop_path(self.gamma_1 * self.attn(self.norm1(x)))
x = x + self.drop_path(self.gamma_2 * self.mlp(self.norm2(x))) return xclass CaiT(nn.Layer):
# with slight modifications to adapt to our cait models
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768, depth=12,
num_heads=12, mlp_ratio=4, qkv_bias=True, qk_scale=None, drop_rate=0.,
attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm, epsilon=1e-6,
block_layers=LayerScale_Block, block_layers_token=LayerScale_Block_CA,
Patch_layer=PatchEmbed, act_layer=nn.GELU, Attention_block=Attention_talking_head,
Mlp_block=Mlp, init_scale=1e-4, Attention_block_token_only=Class_Attention,
Mlp_block_token_only=Mlp, depth_token_only=2, mlp_ratio_clstk=4.0, class_dim=1000):
super().__init__()
self.class_dim = class_dim
self.num_features = self.embed_dim = embed_dim
self.patch_embed = Patch_layer(
img_size=img_size,
patch_size=patch_size,
in_chans=in_chans,
embed_dim=embed_dim
)
num_patches = self.patch_embed.num_patches
self.cls_token = add_parameter(self, paddle.zeros((1, 1, embed_dim)))
self.pos_embed = add_parameter(self, paddle.zeros((1, num_patches, embed_dim)))
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = [drop_path_rate for i in range(depth)]
self.blocks = nn.LayerList([
block_layers(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer, epsilon=epsilon,
act_layer=act_layer, Attention_block=Attention_block, Mlp_block=Mlp_block, init_values=init_scale
) for i in range(depth)
])
self.blocks_token_only = nn.LayerList([
block_layers_token(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio_clstk, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=0.0, attn_drop=0.0, drop_path=0.0, norm_layer=norm_layer, epsilon=epsilon, act_layer=act_layer,
Attention_block=Attention_block_token_only, Mlp_block=Mlp_block_token_only, init_values=init_scale
) for i in range(depth_token_only)
])
self.norm = norm_layer(embed_dim, epsilon=epsilon) # Classifier head
if class_dim > 0:
self.head = nn.Linear(embed_dim, class_dim)
trunc_normal_(self.pos_embed)
trunc_normal_(self.cls_token)
self.apply(self._init_weights) def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight) if isinstance(m, nn.Linear) and m.bias is not None:
zeros_(m.bias) elif isinstance(m, nn.LayerNorm):
zeros_(m.bias)
ones_(m.weight) def forward_features(self, x):
B = x.shape[0]
x = self.patch_embed(x)
cls_tokens = self.cls_token.expand((B, -1, -1))
x = x + self.pos_embed
x = self.pos_drop(x) for i, blk in enumerate(self.blocks):
x = blk(x) for i, blk in enumerate(self.blocks_token_only):
cls_tokens = blk(x, cls_tokens)
x = paddle.concat((cls_tokens, x), axis=1)
x = self.norm(x) return x[:, 0] def forward(self, x):
x = self.forward_features(x) if self.class_dim > 0:
x = self.head(x) return x/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int):
预设模型
In [ ]
def cait_xxs_24(pretrained=False, **kwargs):
model = CaiT(
img_size=224, embed_dim=192, depth=24,
num_heads=4, init_scale=1e-5, **kwargs) if pretrained:
params = paddle.load('data/data82724/CaiT_XXS24_224.pdparams')
model.set_dict(params) return modeldef cait_xxs_36(pretrained=False, **kwargs):
model = CaiT(
img_size=224, embed_dim=192, depth=36,
num_heads=4, init_scale=1e-5, **kwargs) if pretrained:
params = paddle.load('data/data82724/CaiT_XXS36_224.pdparams')
model.set_dict(params)
return modeldef cait_s_24(pretrained=False, **kwargs):
model = CaiT(
img_size=224, embed_dim=384, depth=24,
num_heads=8, init_scale=1e-5, **kwargs) if pretrained:
params = paddle.load('data/data82724/CaiT_S24_224.pdparams')
model.set_dict(params)
return modeldef cait_xxs_24_384(pretrained=False, **kwargs):
model = CaiT(
img_size=384, embed_dim=192, depth=24,
num_heads=4, init_scale=1e-5, **kwargs) if pretrained:
params = paddle.load('data/data82724/CaiT_XXS24_384.pdparams')
model.set_dict(params)
return modeldef cait_xxs_36_384(pretrained=False, **kwargs):
model = CaiT(
img_size=384, embed_dim=192, depth=36,
num_heads=4, init_scale=1e-5, **kwargs) if pretrained:
params = paddle.load('data/data82724/CaiT_XXS36_384.pdparams')
model.set_dict(params)
return modeldef cait_xs_24_384(pretrained=False, **kwargs):
model = CaiT(
img_size=384, embed_dim=288, depth=24,
num_heads=6, init_scale=1e-5, **kwargs) if pretrained:
params = paddle.load('data/data82724/CaiT_XS24_384.pdparams')
model.set_dict(params)
return modeldef cait_s_24_384(pretrained=False, **kwargs):
model = CaiT(
img_size=384, embed_dim=384, depth=24,
num_heads=8, init_scale=1e-5, **kwargs) if pretrained:
params = paddle.load('data/data82724/CaiT_S24_384.pdparams')
model.set_dict(params)
return modeldef cait_s_36_384(pretrained=False, **kwargs):
model = CaiT(
img_size=384, embed_dim=384, depth=36,
num_heads=8, init_scale=1e-6, **kwargs) if pretrained:
params = paddle.load('data/data82724/CaiT_S36_384.pdparams')
model.set_dict(params)
return modeldef cait_m_36_384(pretrained=False, **kwargs):
model = CaiT(
img_size=384, embed_dim=768, depth=36,
num_heads=16, init_scale=1e-6, **kwargs) if pretrained:
params = paddle.load('data/data82724/CaiT_M36_384.pdparams')
model.set_dict(params)
return modeldef cait_m_48_448(pretrained=False, **kwargs):
model = CaiT(
img_size=448, embed_dim=768, depth=48,
num_heads=16, init_scale=1e-6, **kwargs) if pretrained:
params = paddle.load('data/data82724/CaiT_M48_448.pdparams')
model.set_dict(params)
return model模型测试
In [ ]
model = cait_xxs_24(True) random_input = paddle.randn((1, 3, 224, 224)) out = model(random_input)print(out.shape) model.eval() out = model(random_input)print(out.shape)
[1, 1000] [1, 1000]
精度验证
- 官方的论文标称精度如下:
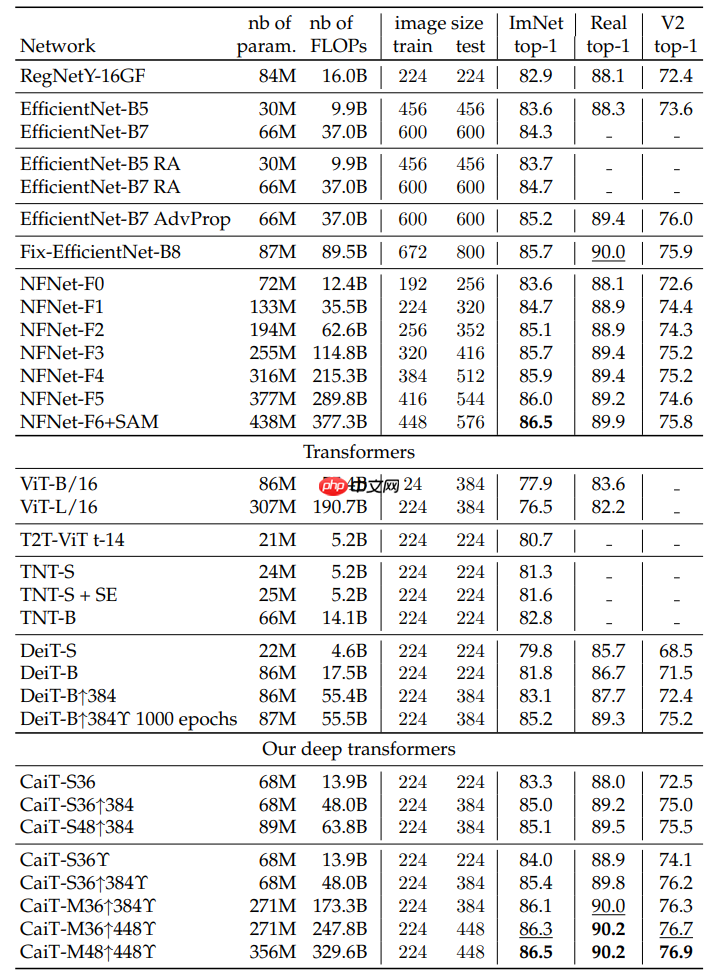
解压数据集
In [ ]
!mkdir ~/data/ILSVRC2012 !tar -xf ~/data/data68594/ILSVRC2012_img_val.tar -C ~/data/ILSVRC2012
模型验证
In [11]
import osimport cv2import numpy as npimport paddleimport paddle.vision.transforms as Tfrom PIL import Image# 构建数据集class ILSVRC2012(paddle.io.Dataset):
def __init__(self, root, label_list, transform, backend='pil'):
self.transform = transform
self.root = root
self.label_list = label_list
self.backend = backend
self.load_datas() def load_datas(self):
self.imgs = []
self.labels = [] with open(self.label_list, 'r') as f: for line in f:
img, label = line[:-1].split(' ')
self.imgs.append(os.path.join(self.root, img))
self.labels.append(int(label)) def __getitem__(self, idx):
label = self.labels[idx]
image = self.imgs[idx] if self.backend=='cv2':
image = cv2.imread(image) else:
image = Image.open(image).convert('RGB')
image = self.transform(image) return image.astype('float32'), np.array(label).astype('int64') def __len__(self):
return len(self.imgs)
val_transforms = T.Compose([
T.Resize(448, interpolation='bicubic'),
T.CenterCrop(448),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])# 配置模型model = cait_m_48_448(pretrained=True)
model = paddle.Model(model)
model.prepare(metrics=paddle.metric.Accuracy(topk=(1, 5)))# 配置数据集val_dataset = ILSVRC2012('data/ILSVRC2012', transform=val_transforms, label_list='data/data68594/val_list.txt', backend='pil')# 模型验证acc = model.evaluate(val_dataset, batch_size=64, num_workers=0, verbose=1)print(acc){'acc_top1': 0.86492, 'acc_top5': 0.97752}



























