本文介绍了PPO算法及其实践。PPO是对策略梯度的改进,通过重要性采样将在线学习转为离线学习,能重复利用数据提升效率,PPO2通过clip限制偏差。文中还给出了基于MountainCar-v0环境的PPO实现代码,包括网络结构、数据处理和更新流程,最后展示了训练过程与效果。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

PPO算法介绍
Proximal Policy Optimization,简称PPO,即近端策略优化,是对Policy Graident,即策略梯度的一种改进算法。PPO的核心精神在于,通过一种被称之为Importce Sampling的方法,将Policy Gradient中On-policy的训练过程转化为Off-policy,即从在线学习转化为离线学习,某种意义上与基于值迭代算法中的Experience Replay有异曲同工之处。通过这个改进,训练速度与效果在实验上相较于Policy Gradient具有明显提升。
环境配置
import argparseimport picklefrom collections import namedtuplefrom itertools import countimport timeimport os, timeimport numpy as npimport matplotlib.pyplot as pltimport gymimport paddleimport paddle.nn as nnimport paddle.nn.functional as Fimport paddle.optimizer as optimfrom paddle.distribution import Normal, Categoricalfrom paddle.io import RandomSampler, BatchSampler, Datasetfrom visualdl import LogWriter
MountainCar-v0介绍
- 汽车位于一维轨道上,位于两个“山”之间。 目标是驶向右边的山峰; 但是,汽车的引擎强度不足以单程通过。 因此,成功的唯一方法就是来回驱动以建立动力。
- 在每个时刻,智能体可以对小车施加3种动作中的一种:向左施力、不施力、向右施力。智能体施力和小车的水平位置会共同决定小车下一时刻的速度。
- 本项目'MountainCar-v0'环境开启了unwrapped模式,即只有到达右边的山峰才能结束一轮游戏,在开始的阶段可能模型要试探上万步才能完成任务,这可真是个稀疏回报的强化学习环境。
# Parametersenv_name = 'MountainCar-v0'gamma = 0.99render = Falseseed = 1log_interval = 10env = gym.make(env_name).unwrapped
num_state = env.observation_space.shape[0]
num_action = env.action_space.n
env.seed(seed)
Transition = namedtuple('Transition', ['state', 'action', 'action_prob', 'reward', 'next_state'])定义网络结构
Actor部分定义的是“演员”,Critic部分定义的是“评论家”。“评论家”网络观察输入并“打分”,“演员”网络接收输入并给出行动的概率。
class Actor(nn.Layer):
def __init__(self):
super(Actor, self).__init__()
self.fc1 = nn.Linear(num_state, 128)
self.action_head = nn.Linear(128, num_action) def forward(self, x):
x = F.relu(self.fc1(x))
action_prob = F.softmax(self.action_head(x), axis=1) return action_probclass Critic(nn.Layer):
def __init__(self):
super(Critic, self).__init__()
self.fc1 = nn.Linear(num_state, 128)
self.state_value = nn.Linear(128, 1) def forward(self, x):
x = F.relu(self.fc1(x))
value = self.state_value(x) return value前置知识——策略梯度方法( Policy Gradient)
- Policy Gradient是DRL中一大类方法,核心思想就是直接优化策略网络Policy Network: π(a∣s;θ) 来提升Reward的获取。
- 怎么直接优化policy呢? 采样很多样本,判断样本的好坏,如果样本好,就将对应的动作action概率增大,如果样本差,就将对应的动作action概率减少。
- Policy gradient方法是on policy的,因此要求每次使用on policy的数据进行训练,所谓on policy就是采样数据的策略和要评估及训练的策略是同一个策略。
PPO算法
1.importance sampling 的使用
policy gradient为on-policy,sample一次更新完actor之后,actor就变了,不能使用原来的数据了,必须重新与Env互动收集新数据,这导致训练需要大量互动,降低效率。
而PPO算法不仅可以将一次采样的数据分minibatch训练神经网络迭代多次,而且能够重复利用数据,也就是sample reuse。
由于训练中使用了off policy的数据(只有第一个更新是on policy,后面都是off policy),数据分布不同了,所以PPO使用了importance sampling来调整
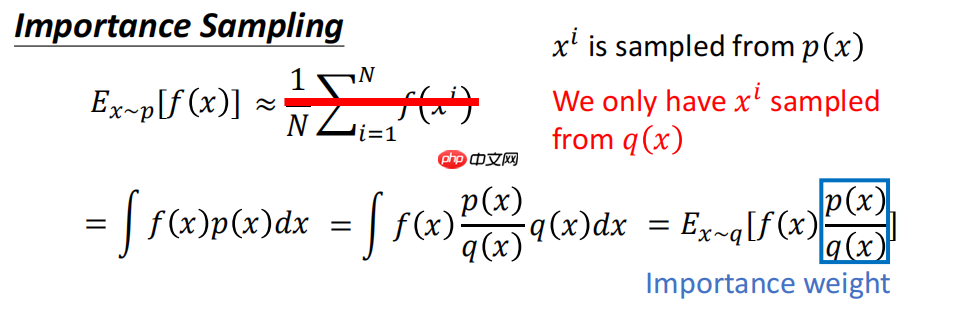
研究了使用重要性采样实现on policy 到off policy的转换,我们知道期望值几乎是差不多的,计算了方差的公式,最后发现第二项对于方差的影响是很小的,但是第一项对于方差的影响还是有的。于是我们晓得,当使用重要性采样的时候,要保证只有p(x)和q(x)的区别不大,才会使得方差的区别很小。


2.PPO2的核心思想
PPO2的核心思想很简单,对于ratio 也就是当前policy和旧policy的偏差做clip,如果ratio偏差超过一定的范围就做clip,clip后梯度也限制在一定的范围内,神经网络更新参数也不会太离谱。这样,在实现上,无论更新多少步都没有关系,有clip给我们挡着,不担心训练偏了。
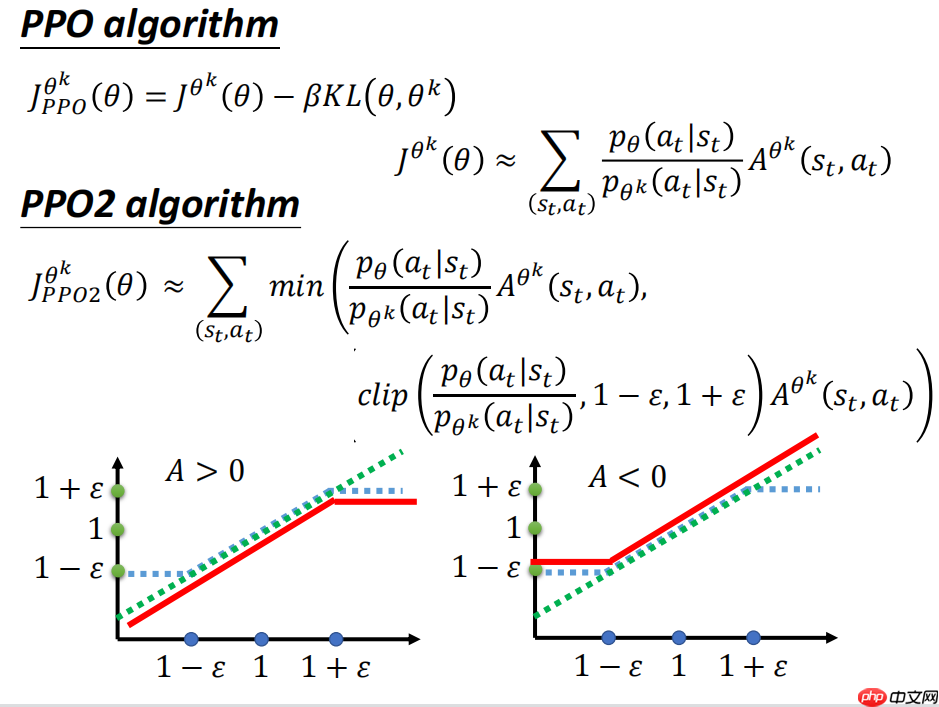
3.本项目代码简析
- 本项目采用 namedtuple('Transition', ['state', 'action', 'action_prob', 'reward', 'next_state'])的方式收集数据集
- 构造了一个 class RandomDataset(Dataset)的类,便于后续使用for index in BatchSampler(sampler=RandomSampler(RandomDataset(len(self.buffer))), batch_size=self.batch_size, drop_last=False)的方式来采样收集的数据,并循环迭代了self.ppo_update_time次,这样就实现了一次采样的数据分minibatch训练神经网络迭代多次。
- 用action_prob = paddle.concat([action_prob[i][int(paddle.index_select(action,index)[i])] for i in range(len(action_prob))]).reshape([-1,1]) 来选择动作概率。
- 用paddle.clip(ratio, 1 - self.clip_param, 1 + self.clip_param) * advantage来截断advantage
- 演员网络的损失为 action_loss = -paddle.min(surr,1).mean() ,评论家网络的损失为value_loss = F.mse_loss(Gt_index, V)
# init with datasetclass RandomDataset(Dataset):
def __init__(self, num_samples):
self.num_samples = num_samples def __getitem__(self, idx):
pass
def __len__(self):
return self.num_samplesclass PPO():
clip_param = 0.2
max_grad_norm = 0.5
ppo_update_time = 10
buffer_capacity = 8000
batch_size = 64
## 初始化参数
def __init__(self):
super(PPO, self).__init__()
self.actor_net = Actor()
self.critic_net = Critic()
self.buffer = []
self.counter = 0
self.training_step = 0
self.writer = LogWriter('./exp')
clip = nn.ClipGradByNorm(self.max_grad_norm)
self.actor_optimizer = optim.Adam(parameters = self.actor_net.parameters(),learning_rate= 1e-3, grad_clip=clip)
self.critic_net_optimizer = optim.Adam(parameters = self.critic_net.parameters(), learning_rate=3e-3,grad_clip=clip) if not os.path.exists('./param'):
os.makedirs('./param/net_param')
os.makedirs('./param/img') # 选择动作
def select_action(self, state):
state = paddle.to_tensor(state,dtype="float32").unsqueeze(0) with paddle.no_grad():
action_prob = self.actor_net(state)
dist = Categorical(action_prob)
action = dist.sample([1]).squeeze(0)
action = action.cpu().numpy()[0] return action, action_prob[:, int(action)].numpy()[0] # 评估值
def get_value(self, state):
state = paddle.to_tensor(state) with paddle.no_grad():
value = self.critic_net(state) return value.numpy() def save_param(self):
paddle.save(self.actor_net.state_dict(), './param/net_param/actor_net' + str(time.time())[:10] +'.param')
paddle.save(self.critic_net.state_dict(), './param/net_param/critic_net' + str(time.time())[:10] +'.param') def store_transition(self, transition):
self.buffer.append(transition)
self.counter += 1
def update(self, i_ep):
state = paddle.to_tensor([t.state for t in self.buffer], dtype="float32")
action = paddle.to_tensor([t.action for t in self.buffer], dtype="int64").reshape([-1, 1])
reward = [t.reward for t in self.buffer] # update: don't need next_state
old_action_prob = paddle.to_tensor([t.action_prob for t in self.buffer], dtype="float32").reshape([-1, 1])
R = 0
Gt = [] for r in reward[::-1]:
R = r + gamma * R
Gt.insert(0, R)
Gt = paddle.to_tensor(Gt, dtype="float32") # print("The agent is updateing....")
for i in range(self.ppo_update_time): for index in BatchSampler(sampler=RandomSampler(RandomDataset(len(self.buffer))), batch_size=self.batch_size, drop_last=False): if self.training_step % 1000 == 0: print('I_ep {} ,train {} times'.format(i_ep, self.training_step))
self.save_param()
index = paddle.to_tensor(index)
Gt_index = paddle.index_select(x=Gt, index=index).reshape([-1, 1])
# V = self.critic_net(state[index])
V = self.critic_net(paddle.index_select(state,index))
delta = Gt_index - V
advantage = delta.detach() # epoch iteration, PPO core!!!
action_prob = self.actor_net(paddle.index_select(state,index)) # new policy
action_prob = paddle.concat([action_prob[i][int(paddle.index_select(action,index)[i])] for i in range(len(action_prob))]).reshape([-1,1])
ratio = (action_prob / paddle.index_select(old_action_prob,index))
surr1 = ratio * advantage
surr2 = paddle.clip(ratio, 1 - self.clip_param, 1 + self.clip_param) * advantage # update actor network
surr = paddle.concat([surr1,surr2],1)
action_loss = -paddle.min(surr,1).mean() # MAX->MIN desent
self.writer.add_scalar('loss/action_loss', action_loss, self.training_step)
self.actor_optimizer.clear_grad()
action_loss.backward()
self.actor_optimizer.step() # update critic network
value_loss = F.mse_loss(Gt_index, V)
self.writer.add_scalar('loss/value_loss', value_loss, self.training_step)
self.critic_net_optimizer.clear_grad()
value_loss.backward()
self.critic_net_optimizer.step()
self.training_step += 1
del self.buffer[:] # clear experiencedef main():
agent = PPO() for i_epoch in range(1000):
state = env.reset() if render: env.render() for t in count():
action, action_prob = agent.select_action(state)
next_state, reward, done, _ = env.step(action)
trans = Transition(state, action, action_prob, reward, next_state) if render: env.render()
agent.store_transition(trans)
state = next_state if done : if len(agent.buffer) >= agent.batch_size: agent.update(i_epoch)
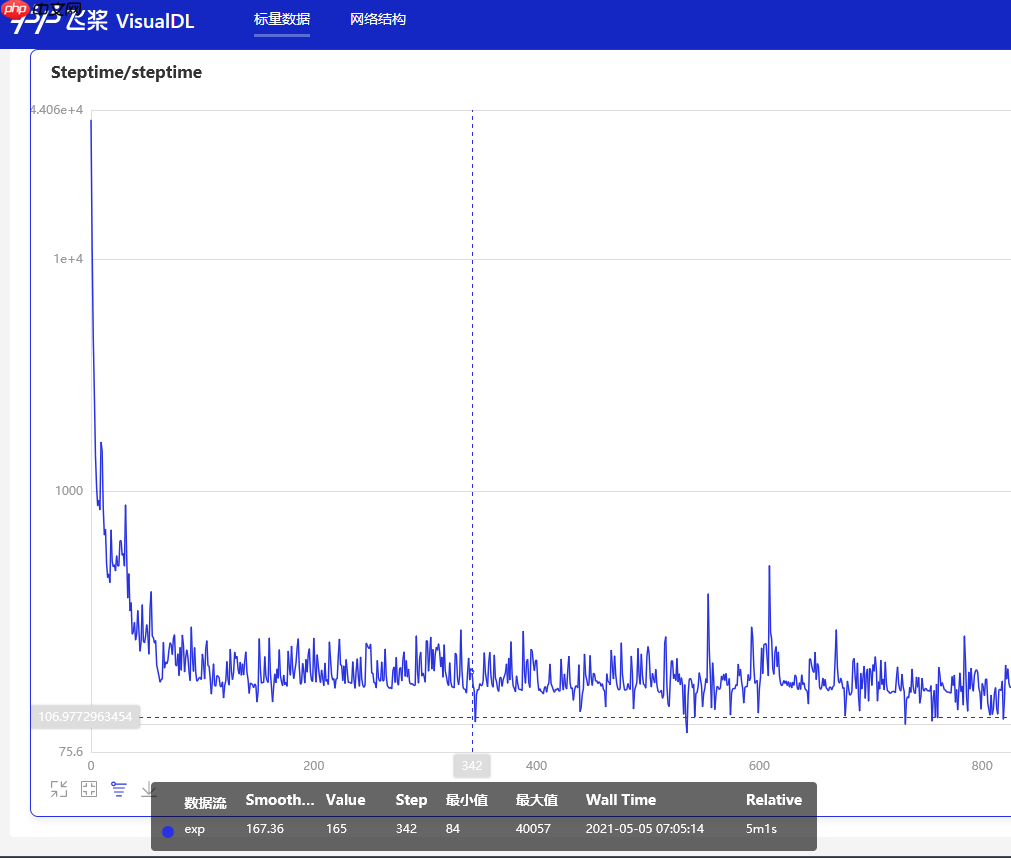
agent.writer.add_scalar('Steptime/steptime', t, i_epoch) # print("Number of steps to achieve the goal:{} , Steptime:{}".format(t,i_epoch))
breakif __name__ == '__main__':
main() print("end")I_ep 0 ,train 0 times I_ep 0 ,train 1000 times I_ep 0 ,train 2000 times I_ep 0 ,train 3000 times I_ep 0 ,train 4000 times I_ep 0 ,train 5000 times I_ep 1 ,train 6000 times I_ep 5 ,train 7000 times I_ep 11 ,train 8000 times I_ep 19 ,train 9000 times I_ep 34 ,train 10000 times I_ep 60 ,train 11000 times I_ep 89 ,train 12000 times I_ep 120 ,train 13000 times I_ep 150 ,train 14000 times I_ep 182 ,train 15000 times I_ep 211 ,train 16000 times I_ep 242 ,train 17000 times I_ep 273 ,train 18000 times I_ep 303 ,train 19000 times I_ep 333 ,train 20000 times I_ep 364 ,train 21000 times I_ep 398 ,train 22000 times I_ep 431 ,train 23000 times I_ep 461 ,train 24000 times I_ep 494 ,train 25000 times I_ep 529 ,train 26000 times I_ep 565 ,train 27000 times I_ep 596 ,train 28000 times I_ep 631 ,train 29000 times I_ep 659 ,train 30000 times I_ep 694 ,train 31000 times I_ep 728 ,train 32000 times I_ep 763 ,train 33000 times I_ep 797 ,train 34000 times I_ep 833 ,train 35000 times I_ep 872 ,train 36000 times I_ep 910 ,train 37000 times I_ep 945 ,train 38000 times I_ep 983 ,train 39000 times end
训练效果演示: