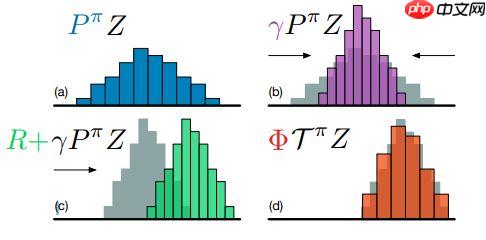
值分布强化学习是基于价值的强化学习算法,不同于传统方法仅建模累积回报期望值,它对整个分布Z(s,a)建模以保留分布信息。C51是其代表算法,将分布离散为51个支点,输出支点概率,通过投影贝尔曼更新处理分布范围问题,损失函数用KL散度,框架与DQN类似但输出和更新方式不同。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

值分布强化学习简介
首先需要声明的是,值分布强化学习(Distributional Reinforcement Learning)是一类基于价值的强化学习算法(value-based Reinforcement Learning)
经典的基于价值的强化学习方法使用期望值对累积回报进行建模,表示为价值函数 V(s) 或动作价值函数 Q(s,a)
而在这个建模过程中,完整的分布信息在很大程度上被丢失了
提出值分布强化学习就是想要解决分布信息丢失这个问题,对累积回报随机变量的整个分布 Z(s,a) 进行建模,而非只建模其期望
如果用公式表示:
Q(st,at)=EZ(st,at)=E[i=1∑∞γt+iR(st+i,at+i)]
值分布强化学习——C51算法
C51 简介
C51 算法来自 DeepMind 的 A Distributional Perspective on Reinforcement Learning 一文。在这篇文章中,作者首先说明传统 DQN 算法希望学习的 Q 是一个数值,其含义是未来奖励和的期望。而在值分布强化学习系列算法中,目标则由数值变为一个分布。在值分布强化学习中,目标也由数值 Q 变为随机变量 Z,这种改变可以使学到的内容是除了数值以外的更多信息,即整个分布。而模型返回的损失也转变为两个分布之间相似度的度量(metric)。

小结
C51算法与DQN相同点
- C51算法的框架依然是DQN算法
- 采样过程依然使用ϵ−greedy策略,这里贪婪是取期望贪婪
- 采用单独的目标网络
C51算法与DQN不同点
C51算法的卷积神经网络的输出不再是行为值函数,而是支点处的概率。
C51算法的损失函数不再是均方差和而是如上所述的KL散度
最后一个问题,该算法为什么叫C51呢?
这是因为在论文中,作者将随机变量的取值分成了51个支点类。
代码部分
导入依赖
from typing import Dict, List, Tupleimport gymfrom visualdl import LogWriterfrom tqdm import tqdm,trangeimport numpy as npimport paddleimport paddle.nn as nnimport paddle.nn.functional as Fimport paddle.optimizer as optimizer
需要用到的特殊算子
def index_add_(parent, axis, idx, child):
expend_dim = parent.shape[0]
idx_one_hot = F.one_hot(idx.cast("int64"), expend_dim)
child = paddle.expand_as(child.cast("float32").unsqueeze(-1), idx_one_hot)
output = parent + (idx_one_hot.cast("float32").multiply(child)).sum(axis).squeeze() return output
经验回放
class ReplayBuffer:
def __init__(self, obs_dim: int, size: int, batch_size: int = 32):
self.obs_buf = np.zeros([size, obs_dim], dtype=np.float32)
self.next_obs_buf = np.zeros([size, obs_dim], dtype=np.float32)
self.acts_buf = np.zeros([size], dtype=np.float32)
self.rews_buf = np.zeros([size], dtype=np.float32)
self.done_buf = np.zeros([size], dtype=np.float32)
self.max_size, self.batch_size = size, batch_size
self.ptr, self.size, = 0, 0
def store(
self,
obs: np.ndarray,
act: np.ndarray,
rew: float,
next_obs: np.ndarray,
done: bool, ):
self.obs_buf[self.ptr] = obs
self.next_obs_buf[self.ptr] = next_obs
self.acts_buf[self.ptr] = act
self.rews_buf[self.ptr] = rew
self.done_buf[self.ptr] = done
self.ptr = (self.ptr + 1) % self.max_size
self.size = min(self.size + 1, self.max_size) def sample_batch(self):
idxs = np.random.choice(self.size, size=self.batch_size, replace=False) return dict(obs=self.obs_buf[idxs],
next_obs=self.next_obs_buf[idxs],
acts=self.acts_buf[idxs],
rews=self.rews_buf[idxs],
done=self.done_buf[idxs]) def __len__(self):
return self.size
定义网络结构
虽然我们的DQN可以学到游戏的整个分布,但在 CartPole-v0 这一环境中,我们还是选取期望作为决策的依据
与传统的 DQN 相比,我们的 C51 会在更新方式上有所不同。
class C51DQN(nn.Layer):
def __init__(
self,
in_dim: int,
out_dim: int,
atom_size: int,
support ):
# 初始化
super(C51DQN, self).__init__()
self.support = support
self.out_dim = out_dim
self.atom_size = atom_size
self.layers = nn.Sequential(
nn.Linear(in_dim, 128),
nn.ReLU(),
nn.Linear(128, 128),
nn.ReLU(),
nn.Linear(128, out_dim * atom_size)
) def forward(self, x):
dist = self.dist(x)
q = paddle.sum(dist * self.support, axis=2) return q
def dist(self, x):
q_atoms = self.layers(x).reshape([-1, self.out_dim, self.atom_size])
dist = F.softmax(q_atoms, axis=-1)
dist = dist.clip(min=float(1e-3)) # 避免 nan
return dist
Agent 中涉及到的参数设定
Attribute:env: gym 环境memory: 经验回放池的容量batch_size: 训练批次epsilon: 随机探索参数epsilonepsilon_decay: 随机探索参数epsilon衰减的步长max_epsilon: 随机探索参数epsilon上限min_epsilon: 随机探索参数epsilon下限target_update: 目标网络更新频率gamma: 衰减因子dqn: 训练模型dqn_target: 目标模型optimizer: 优化器transition: 转移向量,包含状态值state, 动作值action, 奖励reward, 次态next_state, (判断是否)结束回合donev_min: 离散支集的上限v_max: 离散支集的下限atom_size: 支点数量support: 支集模板(用于计算分布的向量模板)
class C51Agent:
def __init__(
self,
env: gym.Env,
memory_size: int,
batch_size: int,
target_update: int,
epsilon_decay: float,
max_epsilon: float = 1.0,
min_epsilon: float = 0.1,
gamma: float = 0.99, # C51 算法的参数
v_min: float = 0.0,
v_max: float = 200.0,
atom_size: int = 51,
log_dir: str = "./log"
):
obs_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
self.env = env
self.memory = ReplayBuffer(obs_dim, memory_size, batch_size)
self.batch_size = batch_size
self.epsilon = max_epsilon
self.epsilon_decay = epsilon_decay
self.max_epsilon = max_epsilon
self.min_epsilon = min_epsilon
self.target_update = target_update
self.gamma = gamma
self.v_min = v_min
self.v_max = v_max
self.atom_size = atom_size
self.support = paddle.linspace(
self.v_min, self.v_max, self.atom_size
) # 定义网络
self.dqn = C51DQN(
obs_dim, action_dim, atom_size, self.support
)
self.dqn_target = C51DQN(
obs_dim, action_dim, atom_size, self.support
)
self.dqn_target.load_dict(self.dqn.state_dict())
self.dqn_target.eval()
self.optimizer = optimizer.Adam(parameters=self.dqn.parameters())
self.transition = []
self.is_test = False
self.log_dir = log_dir
self.log_writer = LogWriter(logdir = self.log_dir, comment= "Categorical DQN") def select_action(self, state: np.ndarray):
if self.epsilon > np.random.random():
selected_action = self.env.action_space.sample() else:
selected_action = self.dqn(
paddle.to_tensor(state,dtype="float32"),
).argmax()
selected_action = selected_action.detach().numpy()
if not self.is_test:
self.transition = [state, selected_action]
return selected_action def step(self, action: np.ndarray):
next_state, reward, done, _ = self.env.step(int(action)) if not self.is_test:
self.transition += [reward, next_state, done]
self.memory.store(*self.transition)
return next_state, reward, done def update_model(self):
samples = self.memory.sample_batch()
loss = self._compute_dqn_loss(samples)
self.optimizer.clear_grad()
loss.backward()
self.optimizer.step()
loss_show = loss return loss_show.numpy().item()
def train(self, num_frames: int, plotting_interval: int = 200):
self.is_test = False
state = self.env.reset()
update_cnt = 0
epsilons = []
losses = []
scores = []
score = 0
epsilon = 0
for frame_idx in trange(1, num_frames + 1):
action = self.select_action(state)
next_state, reward, done = self.step(action)
state = next_state
score += reward # 回合结束
if done:
epsilon += 1
state = self.env.reset()
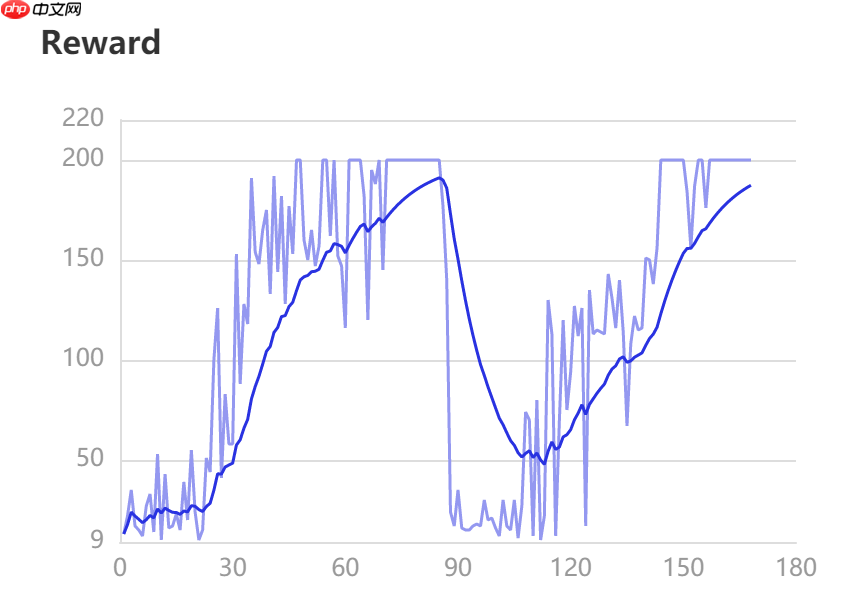
self.log_writer.add_scalar("Reward", value=paddle.to_tensor(score), step=epsilon)
scores.append(score)
score = 0
if len(self.memory) >= self.batch_size:
loss = self.update_model()
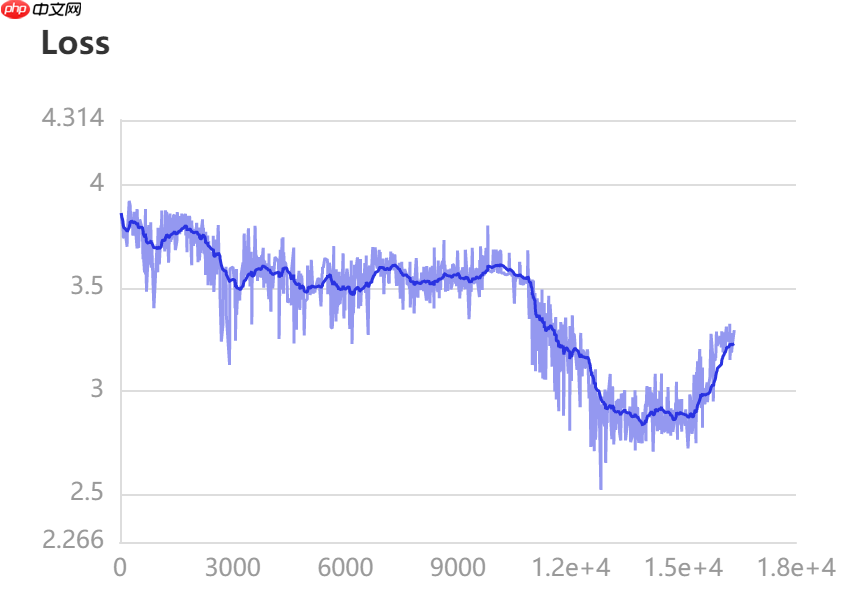
self.log_writer.add_scalar("Loss", value=paddle.to_tensor(loss), step=frame_idx)
losses.append(loss)
update_cnt += 1
self.epsilon = max(
self.min_epsilon, self.epsilon - (
self.max_epsilon - self.min_epsilon
) * self.epsilon_decay
)
epsilons.append(self.epsilon) if update_cnt % self.target_update == 0:
self._target_hard_update()
self.env.close()
def test(self):
self.is_test = True
state = self.env.reset()
done = False
score = 0
frames = [] while not done:
frames.append(self.env.render(mode="rgb_array"))
action = self.select_action(state)
next_state, reward, done = self.step(int(action))
state = next_state
score += reward
print("score: ", score)
self.env.close()
return frames def _compute_dqn_loss(self, samples: Dict[str, np.ndarray]):
# 计算损失
state = paddle.to_tensor(samples["obs"],dtype="float32")
next_state = paddle.to_tensor(samples["next_obs"],dtype="float32")
action = paddle.to_tensor(samples["acts"],dtype="int64")
reward = paddle.to_tensor(samples["rews"].reshape([-1, 1]),dtype="float32")
done = paddle.to_tensor(samples["done"].reshape([-1, 1]),dtype="float32")
delta_z = float(self.v_max - self.v_min) / (self.atom_size - 1) with paddle.no_grad():
next_action = self.dqn_target(next_state).argmax(1)
next_dist = self.dqn_target.dist(next_state)
next_dist = next_dist[:self.batch_size,]
_next_dist = paddle.gather(next_dist, next_action, axis=1)
eyes = np.eye(_next_dist.shape[0], _next_dist.shape[1]).astype("float32")
eyes = np.repeat(eyes, _next_dist.shape[-1]).reshape(-1,_next_dist.shape[1],_next_dist.shape[-1])
eyes = paddle.to_tensor(eyes)
next_dist = _next_dist.multiply(eyes).sum(1)
t_z = reward + (1 - done) * self.gamma * self.support
t_z = t_z.clip(min=self.v_min, max=self.v_max)
b = (t_z - self.v_min) / delta_z
l = b.floor().cast("int64")
u = b.ceil().cast("int64")
offset = (
paddle.linspace( 0, (self.batch_size - 1) * self.atom_size, self.batch_size
).cast("int64")
.unsqueeze(1)
.expand([self.batch_size, self.atom_size])
)
proj_dist = paddle.zeros(next_dist.shape)
proj_dist = index_add_(
proj_dist.reshape([-1]), 0,
(l + offset).reshape([-1]),
(next_dist * (u.cast("float32") - b)).reshape([-1])
)
proj_dist = index_add_(
proj_dist.reshape([-1]), 0,
(u + offset).reshape([-1]),
(next_dist * (b - l.cast("float32"))).reshape([-1])
)
proj_dist = proj_dist.reshape(next_dist.shape)
dist = self.dqn.dist(state)
_dist = paddle.gather(dist[:self.batch_size,], action, axis=1)
eyes = np.eye(_dist.shape[0], _dist.shape[1]).astype("float32")
eyes = np.repeat(eyes, _dist.shape[-1]).reshape(-1,_dist.shape[1],_dist.shape[-1])
eyes = paddle.to_tensor(eyes)
dist_batch = _dist.multiply(eyes).sum(1)
log_p = paddle.log(dist_batch)
loss = -(proj_dist * log_p).sum(1).mean() return loss def _target_hard_update(self):
# 更新目标模型参数
self.dqn_target.load_dict(self.dqn.state_dict())
定义环境
env_id = "CartPole-v0"env = gym.make(env_id)
设定随机种子
seed = 777np.random.seed(seed) paddle.seed(seed) env.seed(seed)
[777]
超参数设定与训练
num_frames = 20000memory_size = 1000batch_size = 32target_update = 200epsilon_decay = 1 / 2000# 训练agent = C51Agent(env, memory_size, batch_size, target_update, epsilon_decay) agent.train(num_frames)
0%| | 32/20000 [00:00<01:38, 202.97it/s]
训练结果展示(使用VisualDL查看log文件夹)