







稠密向量检索模型在实际应用中面临的巨大内存占用问题一直是其落地的一大障碍。实际上,dpr生成的768维稠密向量中可能存在大量冗余信息,我们可以通过某种压缩方法以少量的精度损失换取内存占用的大幅下降。
本文分享了一篇来自EMNLP 2021的论文,探讨了三种简单有效的压缩方法:
- 无监督PCA降维
- 有监督微调降维
- 乘积量化
实验结果表明,简单的PCA降维具有很高的性价比,能够以少于3%的top-100准确度损失换取48倍的压缩比,以少于4%的top-100准确度损失换取96倍的压缩比。

Simple and Effective Unsupervised Redundancy Elimination to Compress Dense Vectors for Passage Retrieval
Introduction
近两年来,以DPR为代表的稠密向量检索模型在开放域问答等领域得到了广泛应用。虽然DPR能够提供更准确的检索结果,但其生成的向量索引内存占用非常大。
例如,当我们对维基百科建立索引时,基于倒排索引的BM25仅占用2.4GB的内存,而DPR生成的768维稠密向量则需要占用61GB的内存,这比BM25足足多出了24倍,而这多出的24倍的内存仅换取了平均2.5%的指标提升(Top-100 Accuracy)。
可以推测,DPR生成的768维稠密向量可能太大了,存在大量冗余。我们可以通过少量的精度损失换取内存占用的大幅下降。针对这个问题,本文探索了三种简单有效的稠密向量压缩方法,包括主成分分析(Principal Component Analysis, PCA)、乘积量化(Product Quantization, PQ)和有监督降维(Supervised Dimensionality Reduction)。
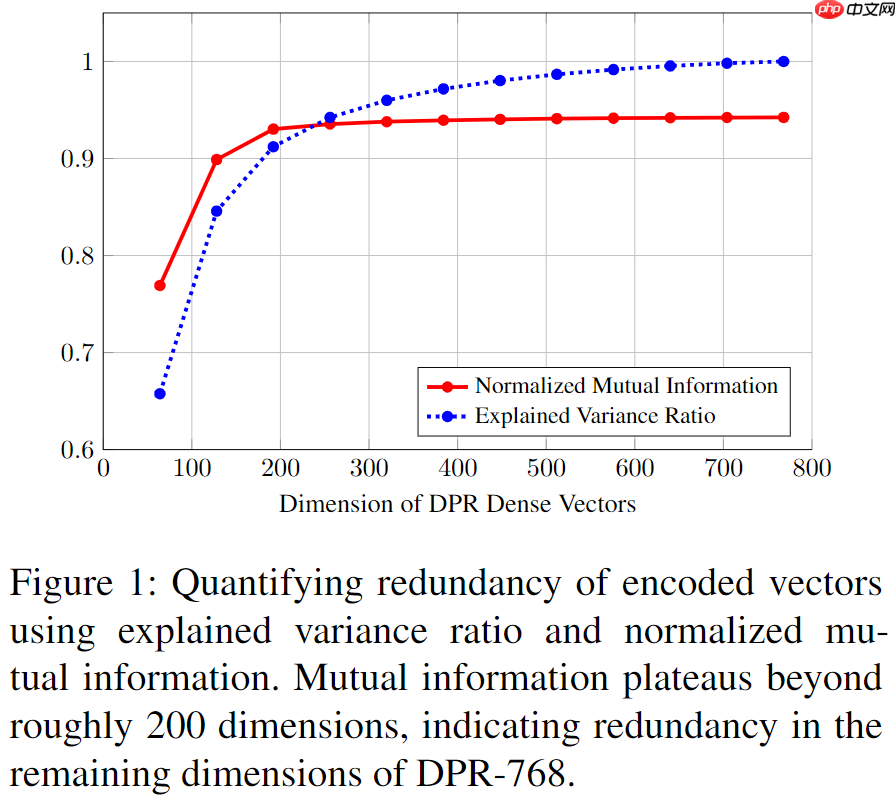
Quantifying Redundancy
首先,我们确认DPR稠密向量是否存在冗余,作者给出了两个常用指标:PCA的「解释方差比」(explained variance ratio)和v_q 与v_d 的「互信息」(mutual information)。
PCA利用特征分解将一组可能存在相关性的向量变换到线性无关的特征向量构成的坐标系下,并保留方差较大的方向,丢弃方差较小的方向,而解释方差比则是度量PCA降维效果的指标:
[ \frac{\sum{i=1}^{m} \sigma{i}^{2}}{\sum{i=1}^{n} \sigma{i}^{2}} ] 其中(\sigma_i^2)是从大到小第i个特征值对应的方差,n和m分别表示PCA降维前和降维后的维度。该比值说明了保留前m个特征向量能保留原始稠密向量方差的比例。
另一种衡量向量冗余度的方法是计算v_q和v_d的互信息,互信息可以根据公式(\mathcal{I}(Q ; D)=H(Q)-H(Q \mid D))得到:
[ \begin{aligned} &\mathcal{I}(Q ; D) \ &\approx\frac{1}{N} \sum{i=1}^{N} \mathbb{E}{p\left(D \mid Q=q{i}\right)}\left[\ln p\left(D \mid Q=q{i}\right)\right] \ &\quad -\mathbb{E}{p(D)}\left[\ln \frac{1}{N} \sum{i=1}^{N} p\left(D \mid Q=q{i}\right)\right] \end{aligned} ] 其中(p\left(D \mid Q=q{i}\right))可以利用DPR的优化目标近似计算:
[ \begin{aligned} &\mathcal{L}\left(q, d^{+}, d{1}^{-}, d{2}^{-}, \cdots, d{m}^{-}\right) \ &=-\log p\left(D=d^{+} \mid Q=q\right) \ &=-\log \frac{\exp \left(v{q}^{\top} v{d^{+}}\right)}{\exp \left(v{q}^{\top} v{d^{+}}\right)+\displaystyle\sum{i=1}^{m} \exp \left(v{q}^{\top} v{d_{i}^{-}}\right)} \end{aligned} ] 互信息的上界是(\ln N),为了和PCA对比,我们可以对互信息做标准化(\mathcal{I}(Q ; D) / \ln N)。
经过不同程度的PCA降维,解释方差比和标准互信息随向量维度的变化趋势如下图所示。我们可以发现,200维左右是一个甜区,「将768维的向量降维到200维,降维后的向量能够保留90%的方差和99%的互信息,而进一步降维会导致信息量的急速下降。」
Dense Vector Compression
接下来,我们尝试三种简单的方法来压缩稠密向量:
「Supervised Approach:」我们可以在双塔编码器的顶部分别增加两个线性层W_q和Wp来降维,在训练时可以冻结下层参数,仅微调线性层,同时我们还可以增加一个正交规范化损失(\left|W{p} W{q}^{\top}-I\right|{2})鼓励W_q和W_p互相正交,这能使得降维后的点积相似度和降维前的scale是一致的。「Unsupervised Approach:」我们可以将d_q和d_p混在一起,然后对这一向量集拟合一个线性PCA变换,在推理阶段,使用拟合到的PCA变换对DPR生成的向量进行降维。「Product Quantization:」我们还可以使用乘积量化来进一步压缩向量大小,其基本原理是将d维的向量分解成s个子向量,每个子向量采用k-means量化,并使用t比特存储。比如,一个768维的向量占用了768\times 32比特,通过将其分解为192个8比特的子向量,该向量的大小便压缩到了192\times 8比特,即原始大小的1/16,平均来说,每个维度所占用的比特数从32降低到了2。

Experiment & Results
作者在NQ、TriviaQA、WQ、CuratedTREC、SQuAD上测试了DPR的top-k准确率(前k个召回结果中至少有一个正确的比例),实验细节可参见原文。
Dimensionality Reduction
我们首先对比有监督降维和无监督降维的表现,其中PCA-*和Linear-*分别是无监督PCA降维和有监督微调降维(仅微调线性层)的结果,而DPR-*表示不冻结下层参数,与线性层联合微调的结果。可以发现,在向量维度较大的时候(256、128),无监督PCA的表现更好,当向量维度较小的时候(64),有监督微调的表现会更好,然而这时候模型性能下降得也非常明显,因此总体来说无监督PCA更有实用价值。
虽然理论上Linear-*可以学习到PCA-*拟合的线性映射,但想要让参数收敛到一个好的解并不简单。另外,冻结下层参数(Linear-*)比不冻结(DPR-*)的结果都要好,这同样是训练不充分所导致的。综上,在大多数情况下,我们仅需要做简单的线性PCA变换,就能获取很不错的压缩比了。

Product Quantization
乘积量化是一种非常有效的压缩方法,作者在上述实验结果的基础上进一步加入了乘积量化,实验结果如下表所示,其中PQ-2表示经过量化之后每个维度所占用的比特数为2。从下表可以看出,PQ-1压缩过于激进了,虽然其压缩比是PQ-2的两倍,但指标下降却不止两倍,这是很不划算的。
综上,我们认为PCA降维加乘积量化是最好的压缩方式。如果我们将指标下降幅度限制在平均4%以内,我们可以使用PCA-128+PQ2将稠密向量压缩96倍,将维基百科的向量索引的内存占用从61GB降低到642MB,同时将推理时间从7570ms降低到416ms。

Hybrid Search
大量研究已表明结合稀疏向量检索(BM25)和稠密向量检索能够提升性能,其中最简单有效的方法是对分数做线性加权求和:
[ \text{score}{\text{dense}} + \alpha \cdot \text{score}{\text{sparse}} ] 这里我们简单地设定(\alpha=1),即稠密检索和稀疏检索等权。
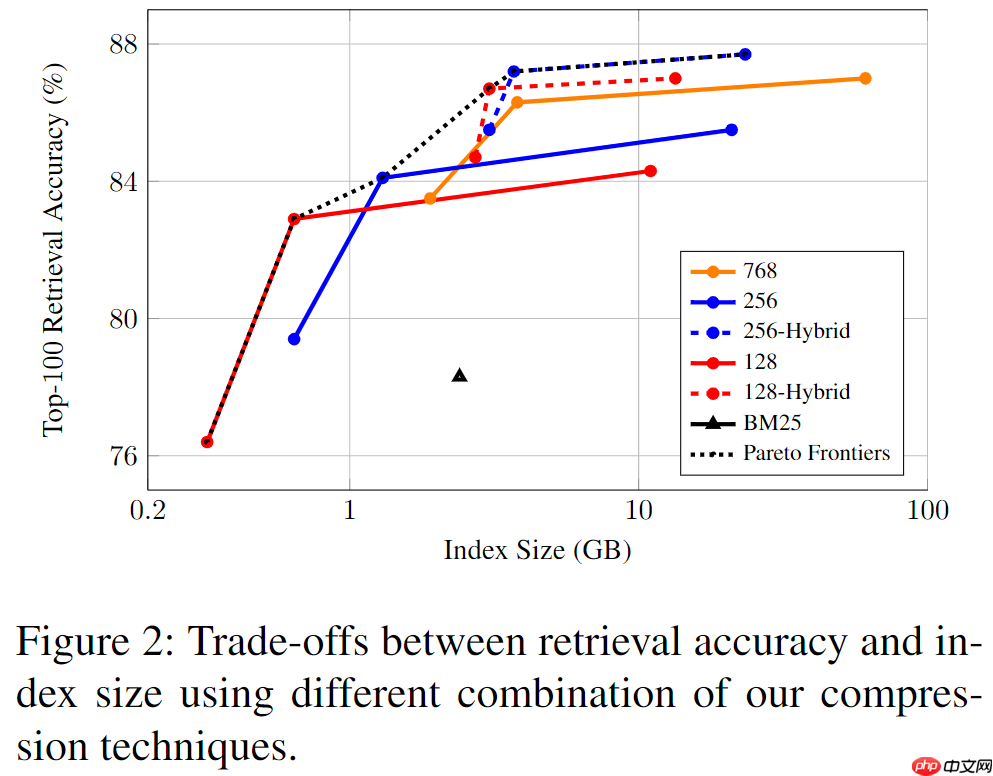
加入混合检索可以进一步提升性能,下图展示了不同压缩方法的检索准确率和索引大小的关系,其中每条曲线从左到右依次为PQ1、PQ2和w/o PQ,图中的黑色虚线为帕累托边界,原始的768维DPR向量并没有落在帕累托边界上,表明其的确有改进的空间。具体来说,「PCA-256+PQ2+Hybrid Search的压缩策略将61GB的索引大小降低到了3.7GB,其Top-100准确率甚至比原始DPR更好(+0.2%)。」
Discussion
限制稠密向量检索模型落地的一大瓶颈就是推理时延和内存消耗的问题。这篇论文通过实验证明了简单的主成分分析加上乘积量化,在辅以稀疏向量检索,就能在保证准确度的前提下大幅减少内存占用,提升检索速度,颇具实用价值。




























