






该文介绍百度架构师课程内置的文本相似度计算比赛方案,用ERNIE预训练模型,将文本匹配转为分类任务,拼接query和title为输入。使用54614条训练集、7802条验证集、15604条测试集,经数据处理、模型训练,首 epoch 验证集准确率超90%,无需调参,可作基线,最后输出结果为result.csv。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

文本相似度计算比赛-使用预训练模型,直接上90%
比赛是百度架构师手把手带你零基础实践深度学习课程内置的比赛,似乎已经停止判分了.
训练集:54614条
验证集:7802条
测试集:15604条
本文改自『NLP经典项目集』02:使用预训练模型ERNIE优化情感分析
没有任何调参,所以作为预训练模型的baseline完全没问题
1. 任务介绍
1.1 任务内容
文本语义匹配是自然语言处理中一个重要的基础问题,NLP领域的很多任务都可以抽象为文本匹配任务。例如,信息检索可以归结为查询项和文档的匹配,问答系统可以归结为问题和候选答案的匹配,对话系统可以归结为对话和回复的匹配。语义匹配在搜索优化、推荐系统、快速检索排序、智能客服上都有广泛的应用。如何提升文本匹配的准确度,是自然语言处理领域的一个重要挑战。
- 信息检索:在信息检索领域的很多应用中,都需要根据原文本来检索与其相似的其他文本,使用场景非常普遍。
- 新闻推荐:通过用户刚刚浏览过的新闻标题,自动检索出其他的相似新闻,个性化地为用户做推荐,从而增强用户粘性,提升产品体验。
- 智能客服:用户输入一个问题后,自动为用户检索出相似的问题和答案,节约人工客服的成本,提高效率。
1.2 什么是文本匹配?
让我们来看一个简单的例子,比较各候选句子哪句和原句语义更相近
原句:“车头如何放置车牌”
- 比较句1:“前牌照怎么装”
- 比较句2:“如何办理北京车牌”
- 比较句3:“后牌照怎么装”
(1)比较句1与原句,虽然句式和语序等存在较大差异,但是所表述的含义几乎相同
(2)比较句2与原句,虽然存在“如何” 、“车牌”等共现词,但是所表述的含义完全不同
(3)比较句3与原句,二者讨论的都是如何放置车牌的问题,只不过一个是前牌照,另一个是后牌照。二者间存在一定的语义相关性。
所以语义相关性,句1大于句3,句3大于句2.这就是语义匹配。

1.3 使用预训练序列分类模型
本任务本是匹配工作,两个距离相似则是1,不相似则是0.这其实也可以看做一个分类任务,两个句子是相似的,则类别为1,两个句子不相似的,则类别为0.
本文使用的是一个文本分类的例子『NLP经典项目集』02:使用预训练模型ERNIE优化情感分析
通读全文后会发现,我们的主要任务其实变成了如何构建这样一句话,这里使用最简单的做法,直接将两个句子拼接
即,query和title直接拼接。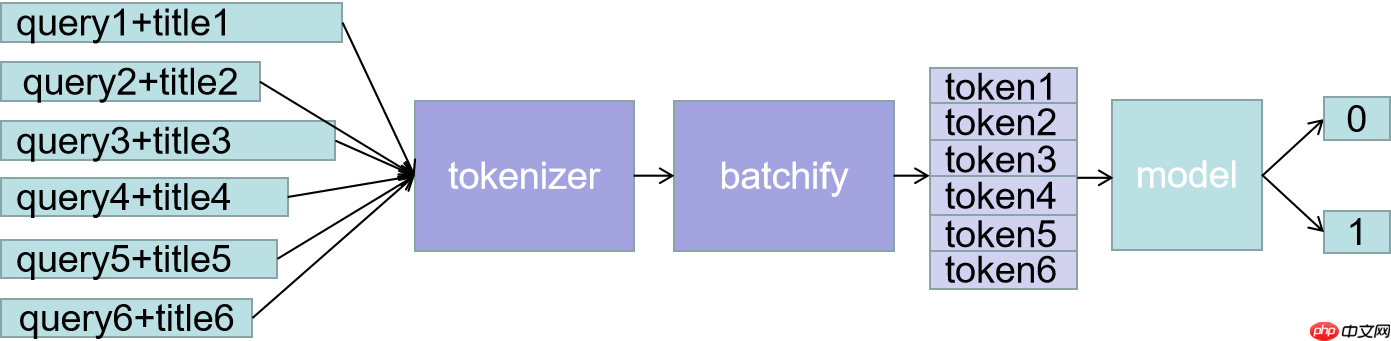
加载第三方库,paddle和paddlenlp相关的库
import mathimport numpy as npimport osimport collectionsfrom functools import partialimport randomimport timeimport inspectimport importlibfrom tqdm import tqdmimport paddleimport paddle.nn as nnimport paddle.nn.functional as Ffrom paddle.io import IterableDatasetfrom paddle.utils.download import get_path_from_url
本实验需要依赖与paddlenlp,aistudio上的paddlenlp版本过低,所以需要首先升级paddlenlp
!pip install paddlenlp --upgrade
导入paddlenlp相关的包
import paddlenlp as ppnlpfrom paddlenlp.data import JiebaTokenizer, Pad, Stack, Tuple, Vocab# from utils import convert_examplefrom paddlenlp.datasets import MapDatasetfrom paddle.dataset.common import md5filefrom paddlenlp.datasets import DatasetBuilder
2. 定义模型和tokenizer
2.1 定义模型预训练
经过前面的分析,我们将两个句子拼成了一句话,然后转变成分类任务,所以这里使用序列分类模型.这里其实主要用的是model,那个ernie_model是为了帮助理解展示用的.
MODEL_NAME = "ernie-1.0"ernie_model = ppnlp.transformers.ErnieModel.from_pretrained(MODEL_NAME) model = ppnlp.transformers.ErnieForSequenceClassification.from_pretrained(MODEL_NAME, num_classes=2)
[2021-05-18 10:21:29,970] [ INFO] - Downloading https://paddlenlp.bj.bcebos.com/models/transformers/ernie/ernie_v1_chn_base.pdparams and saved to /home/aistudio/.paddlenlp/models/ernie-1.0
[2021-05-18 10:21:29,973] [ INFO] - Downloading ernie_v1_chn_base.pdparams from https://paddlenlp.bj.bcebos.com/models/transformers/ernie/ernie_v1_chn_base.pdparams
100%|██████████| 392507/392507 [00:09<00:00, 43038.06it/s]
[2021-05-18 10:21:45,369] [ INFO] - Weights from pretrained model not used in ErnieModel: ['cls.predictions.layer_norm.weight', 'cls.predictions.decoder_bias', 'cls.predictions.transform.bias', 'cls.predictions.transform.weight', 'cls.predictions.layer_norm.bias']
[2021-05-18 10:21:45,675] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/ernie-1.0/ernie_v1_chn_base.pdparams
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1297: UserWarning: Skip loading for classifier.weight. classifier.weight is not found in the provided dict.
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1297: UserWarning: Skip loading for classifier.bias. classifier.bias is not found in the provided dict.
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
2.2 定义一个模型对应的tokenizer
tokenizer = ppnlp.transformers.ErnieTokenizer.from_pretrained(MODEL_NAME)
[2021-05-18 10:21:47,430] [ INFO] - Downloading vocab.txt from https://paddlenlp.bj.bcebos.com/models/transformers/ernie/vocab.txt 100%|██████████| 90/90 [00:00<00:00, 4144.52it/s]
按照官方例子,测试一下我们的句子吧
tokens = tokenizer._tokenize("万家乐燃气热水器怎么样")print("Tokens: {}".format(tokens))# token映射为对应token idtokens_ids = tokenizer.convert_tokens_to_ids(tokens)print("Tokens id: {}".format(tokens_ids))# 拼接上预训练模型对应的特殊token ,如[CLS]、[SEP]tokens_ids = tokenizer.build_inputs_with_special_tokens(tokens_ids)print("Tokens id: {}".format(tokens_ids))# 转化成paddle框架数据格式tokens_pd = paddle.to_tensor([tokens_ids])print("Tokens : {}".format(tokens_pd))# 此时即可输入ERNIE模型中得到相应输出sequence_output, pooled_output = ernie_model(tokens_pd)print("Token wise output: {}, Pooled output: {}".format(sequence_output.shape, pooled_output.shape))
Tokens: ['万', '家', '乐', '燃', '气', '热', '水', '器', '怎', '么', '样']
Tokens id: [211, 50, 354, 1404, 266, 506, 101, 361, 936, 356, 314]
Tokens id: [1, 211, 50, 354, 1404, 266, 506, 101, 361, 936, 356, 314, 2]
Tokens : Tensor(shape=[1, 13], dtype=int64, place=CUDAPlace(0), stop_gradient=True,
[[1 , 211, 50 , 354, 1404, 266, 506, 101, 361, 936, 356, 314, 2 ]])
Token wise output: [1, 13, 768], Pooled output: [1, 768]
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/tensor/creation.py:143: DeprecationWarning: `np.object` is a deprecated alias for the builtin `object`. To silence this warning, use `object` by itself. Doing this will not modify any behavior and is safe. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations if data.dtype == np.object:
encoded_text = tokenizer(text="万家乐燃气热水器怎么样", max_seq_len=20)for key, value in encoded_text.items(): print("{}:\n\t{}".format(key, value))# 转化成paddle框架数据格式input_ids = paddle.to_tensor([encoded_text['input_ids']])print("input_ids : {}".format(input_ids))
segment_ids = paddle.to_tensor([encoded_text['token_type_ids']])print("token_type_ids : {}".format(segment_ids))# 此时即可输入ERNIE模型中得到相应输出sequence_output, pooled_output = ernie_model(input_ids, segment_ids)print("Token wise output: {}, Pooled output: {}".format(sequence_output.shape, pooled_output.shape))
input_ids:
[1, 211, 50, 354, 1404, 266, 506, 101, 361, 936, 356, 314, 2]
token_type_ids:
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
input_ids : Tensor(shape=[1, 13], dtype=int64, place=CUDAPlace(0), stop_gradient=True,
[[1 , 211, 50 , 354, 1404, 266, 506, 101, 361, 936, 356, 314, 2 ]])
token_type_ids : Tensor(shape=[1, 13], dtype=int64, place=CUDAPlace(0), stop_gradient=True,
[[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
Token wise output: [1, 13, 768], Pooled output: [1, 768]
3. 数据读取
3.1 load_dataset函数
本实验共计需要读取四份数据: 训练集 train.tsv、验证集 dev.tsv、测试集 test.tsv 和 词汇表 vocab.txt。加载数据的代码如下: 这里是课程提供的,不需要修改
class BAIDUData2(DatasetBuilder):
SPLITS = { # 'train':os.path.join('data', 'baidu_train.tsv'),
# 'dev': os.path.join('data', 'baidu_dev.tsv'),
'train': 'baidu_train.tsv', 'dev': 'baidu_dev.tsv',
} def _get_data(self, mode, **kwargs):
filename = self.SPLITS[mode] return filename def _read(self, filename):
"""读取数据"""
with open(filename, 'r', encoding='utf-8') as f:
head = None
for line in f:
data = line.strip().split("\t") if not head:
head = data else:
query, title, label = data yield {"query": query, "title": title, "label": label} def get_labels(self):
return ["0", "1"]
def load_dataset(name=None,
data_files=None,
splits=None,
lazy=None,
**kwargs):
reader_cls = BAIDUData2 print(reader_cls) if not name:
reader_instance = reader_cls(lazy=lazy, **kwargs) else:
reader_instance = reader_cls(lazy=lazy, name=name, **kwargs)
datasets = reader_instance.read_datasets(data_files=data_files, splits=splits) return datasets
# Loads dataset.train_ds, dev_ds = load_dataset(splits=["train", "dev"])
<class '__main__.BAIDUData2'>
3.2 前处理:拼接句子
主要针对我们的任务,修改convert_example函数,在这个里面,将query和title拼接,并转成token,convert_example这个在utils.py中123行
from functools import partialfrom paddlenlp.data import Stack, Tuple, Padfrom utils import convert_example, create_dataloader
batch_size = 32max_seq_length = 128trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length)
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # segment
Stack(dtype="int64") # label): [data for data in fn(samples)]
train_data_loader = create_dataloader(
train_ds,
mode='train',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
dev_data_loader = create_dataloader(
dev_ds,
mode='dev',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
4. 定义一些超参,loss,优化器等
from paddlenlp.transformers import LinearDecayWithWarmup# 训练过程中的最大学习率learning_rate = 5e-5 # 训练轮次epochs = 4# 学习率预热比例warmup_proportion = 0.1# 权重衰减系数,类似模型正则项策略,避免模型过拟合weight_decay = 0.01num_training_steps = len(train_data_loader) * epochs
lr_scheduler = LinearDecayWithWarmup(learning_rate, num_training_steps, warmup_proportion)
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in [
p.name for n, p in model.named_parameters() if not any(nd in n for nd in ["bias", "norm"])
])
criterion = paddle.nn.loss.CrossEntropyLoss()
metric = paddle.metric.Accuracy()
5. 开始训练,可以看到第一个epoch在eval上就上90%了
import paddle.nn.functional as Ffrom utils import evaluate
global_step = 0for epoch in range(1, epochs + 1): for step, batch in enumerate(train_data_loader, start=1):
input_ids, segment_ids, labels = batch
logits = model(input_ids, segment_ids)
loss = criterion(logits, labels)
probs = F.softmax(logits, axis=1)
correct = metric.compute(probs, labels)
metric.update(correct)
acc = metric.accumulate()
global_step += 1
if global_step % 10 == 0 : print("global step %d, epoch: %d, batch: %d, loss: %.5f, acc: %.5f" % (global_step, epoch, step, loss, acc))
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
evaluate(model, criterion, metric, dev_data_loader)
保存模型
model.save_pretrained('checkpoint2')
tokenizer.save_pretrained('checkpoint2')
6.测试结果,输出csv
from utils import predictimport pandas as pd
label_map = {0:'0', 1:'1'}def preprocess_prediction_data(data):
examples = [] for query, title in data:
examples.append({"query": query, "title": title}) #print(len(examples),': ',query,"---", title)
return examples
test_file = 'test_forstu.tsv'data = pd.read_csv(test_file, sep='\t')#print(data.shape)data1 = list(data.values)
examples = preprocess_prediction_data(data1)
results = predict(
model, examples, tokenizer, label_map, batch_size=batch_size)for idx, text in enumerate(examples): print('Data: {} \t Label: {}'.format(text, results[idx]))
data2 = []for i in range(len(data1)):
data2.extend(results[i])
data['label'] = data2print(data.shape)
data.to_csv('result.csv',sep='\t')
最后提交结果就生成的result.csv文件就可以啦.




























