






本文围绕基于THUCNews新闻标题的文本分类实验展开,介绍实验目的为掌握LSTM、Attention机制等知识,用飞桨构建相关模型。实验处理THUCNews数据集,经数据处理、模型构建等步骤,用双向LSTM结合Attention机制实现分类,还涉及训练评估、模型保存与推理等内容。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

基于THUCNews新闻标题的文本分类

1. 实验介绍
1.1 实验目的
- 理解并掌握经典的时序模型长短时记忆网络LSTM的基础知识
- 熟悉Attention机制、双向LSTM的原理
- 熟悉如何使用飞桨深度学习开源框架构建带有Attention的循环神经网络
1.2 实验内容
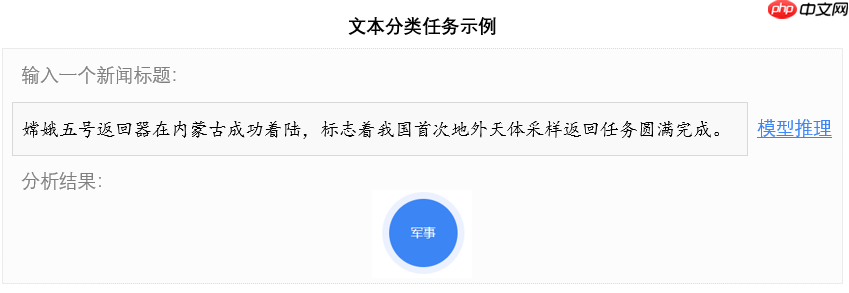
在深度学习领域,文本分类是指人们使用计算机技术将文本数据进行自动化归类的任务,是自然语言处理(NLP)的经典任务之一,应用示例如 图1 所示。
当前文本分类技术已经在互联网业务中广泛应用,如:在资讯领域,应用文本分类技术,可以自动对新闻资源进行主题划分(娱乐、社会、科学、历史、军事等),支持垂类资源建设,满足各类应用需求。通过对文章的主题分类计算,并结合用户画像,可以实现信息精准推荐,实现千人千面。
1.3 实验环境
本实验支持在实训平台或本地环境操作,建议您使用实训平台。
- 实训平台:如果您选择在实训平台上操作,实训平台集成了实验必须的相关环境,代码可在线运行,同时还提供了免费算力,即使实践复杂模型也无算力之忧。
- 本地环境:如果您选择在本地环境上操作,需要安装Python3.7、飞桨开源框架2.0及以上版本等实验必须的环境,具体要求及实现代码请参见《本地环境安装说明》。
1.4 实验设计
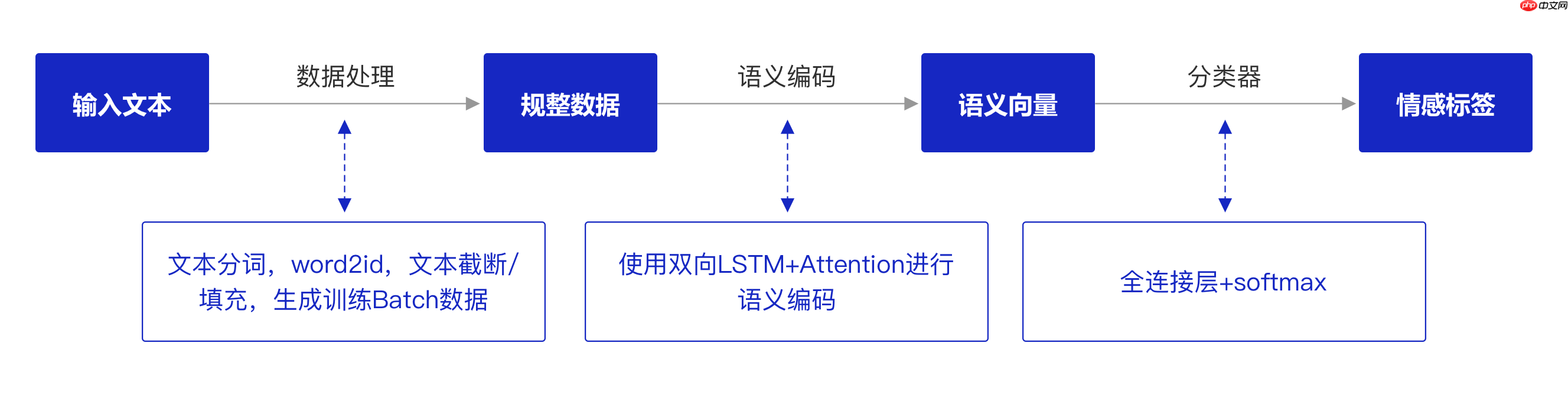
本实验的实现方案如 图2 所示, 模型输入是新闻标题的文本,模型输出是新闻类别。在模型构建时,需要先对输入的新闻文本进行数据处理,生成规整的文本序列数据,包括语句分词、将词转换为ID、过长文本截断、过短文本填充等;然后使用带有Attention机制的双向LSTM对文本序列进行编码,获得文本的语义向量表示;最后经过全连接层和softmax处理,得到文本属于各个新闻类别的概率。
2 实验详细实现
基于LSTM的文本分类实验流程如 图3 所示,包含如下6个步骤:
- 数据处理:根据模型接收的数据格式,完成相应的预处理操作,保证模型正常读取;
- 模型构建:设计文本分类模型,判断新闻类别;
- 训练配置:实例化模型,选择模型计算资源,指定模型迭代的优化算法;
- 训练与评估:执行多轮训练不断调整参数,以达到最优的效果;对训练好的模型进行评估测试,观察评估指标;
- 模型保存:将模型参数保存到指定位置,便于后续推理或继续训练使用;
- 模型推理:选取一段新闻标题文本数据,通过模型推理出新闻所属的类别。
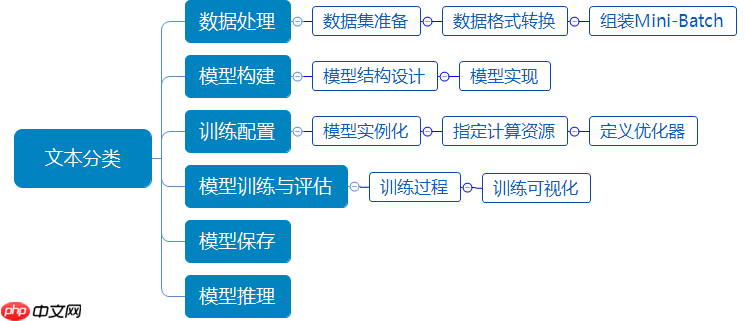
图3 文本分类的实验流程
说明:
不同的深度学习任务,使用深度学习框架的代码结构基本相似。大家掌握了一个任务的实现方法,便很容易在此基础上举一反三。使用深度学习框架可以屏蔽底层实现,用户只需关注模型的逻辑结构。同时,简化了计算,降低了深度学习入门门槛。
2.1 数据处理
2.1.1 数据集介绍
中文文本分类数据集THUCNews是根据新浪新闻RSS订阅频道2005~2011年间的历史数据筛选过滤生成,包含74万篇新闻文档,均为UTF-8纯文本格式。在原始新浪新闻分类体系的基础上,重新整合划分出14个候选分类类别:财经、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐。
THUCNews数据集较大,本实验使用的数据集是从原数据集中按照一定的比例提取的新闻标题数据,并进行了相应的格式处理。数据集包含如下四个文件:
- 训练集train.txt:包含约27.1w条训练样本,包括新闻标题内容、所属类别,如 图4 所示。

图4 train.txt文件示例
测试集test.txt:包含约6.7w条测试样本,格式与训练集相同。
单词词表dict.txt:在原始的THUCNews数据集上,使用jieba模型进行分词,统计词频倒序排序后,选取约Top 30w的词,如 图5 所示。

图5 单词词表dict.txt文件示例
- 标签词表labeldict.txt:THUCNews数据集共计14个新闻类别,将这些类别汇总在此表中,如 图6 所示,包含新闻类别,及其对应的标签ID。

图6 label_dict.txt文件示例
2.1.2 数据读取
读取 train.txt、 test.txt、dict.txt 和 label_dict.txt,实现代码如下。
# 导入paddle及相关包import paddleimport paddle.nn.functional as Fimport paddle.nn.initializer as Iimport reimport osimport jiebaimport randomimport tarfileimport requestsimport numpy as npfrom collections import Counterfrom collections import defaultdictdef load_dataset(path):
# 生成加载数据的地址
train_path = os.path.join(path, "train.txt")
test_path = os.path.join(path, "test.txt")
dict_path = os.path.join(path, "dict.txt")
label_path = os.path.join(path, "label_dict.txt") # 加载词典
with open(dict_path, "r", encoding="utf-8") as f:
words = [word.strip() for word in f.readlines()]
word_dict = dict(zip(words, range(len(words)))) # 加载标签词典
with open(label_path, "r", encoding="utf-8") as f:
lines = [line.strip().split() for line in f.readlines()]
lines = [(line[0], int(line[1])) for line in lines]
label_dict = dict(lines) def load_data(data_path):
data_set = [] with open(data_path, "r", encoding="utf-8") as f: for line in f.readlines():
label, text = line.strip().split("\t", maxsplit=1)
data_set.append((text, label)) return data_set
train_set = load_data(train_path)
test_set = load_data(test_path) return train_set, test_set, word_dict, label_dict
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int):
2.1.2 数据格式转换
模型无法直接处理文本数据,在自然语言处理中,常规的做法是先将文本进行分词,然后将每个词映射为词典中的ID,模型会根据这个ID找到该词的词向量。
1)采用结巴分词进行文本分词操作,使用方式很简单,只需要将文本序列传入结巴分词模型就能返回该文本的分词结果。
2)根据将序列中的每个单词分别映射为该词在词典中的ID,方便后续模型处理。
实现代码现如下。
# 将文本序列进行分词,然后词转换为字典IDdef convert_corpus_to_id(data_set, word_dict, label_dict):
tmp_data_set = [] for text, label in data_set:
text = [word_dict.get(word, word_dict["[oov]"]) for word in jieba.cut(text)]
tmp_data_set.append((text, label_dict[label])) return tmp_data_set
2.1.3 组装mini-batch
模型训练时,通常将数据分批传入,每批数据作为一个mini-batch,因此需要将数据按批次(mini-batch)划分。每个mini-batch数据包含两部分:文本数据和文本对应的新闻类别标签label。
这里涉及到一个问题,一个mini-batch数据中通常包含若干条文本,每条文本的长度又不一致,给模型训练带来困难。常见的一种做法是设定一个最大长度max_seq_len,对大于该长度的文本进行截断,小于该长度的文本使用 [pad] 进行填充,这样就能实现统一每个mini-batch的文本长度的目的。
实现代码如下。
# 构造训练数据,每次传入模型一个batch,一个batch里面有batch_size条样本def build_batch(data_set, batch_size, max_seq_len, shuffle=True, drop_last=True, pad_id=1):
batch_text = []
batch_label = [] if shuffle:
random.shuffle(data_set) for text, label in data_set: # 截断数据
text = text[:max_seq_len] # 填充数据到固定长度
if len(text) < max_seq_len:
text.extend([pad_id]*(max_seq_len-len(text))) assert len(text) == max_seq_len
batch_text.append(text)
batch_label.append([label]) if len(batch_text) == batch_size: yield np.array(batch_text).astype("int64"), np.array(batch_label).astype("int64")
batch_text.clear()
batch_label.clear() # 处理是否删掉最后一个不足batch_size 的batch数据
if (not drop_last) and len(batch_label) > 0: yield np.array(batch_text).astype("int64"), np.array(batch_label).astype("int64")
2.2 模型构建
2.2.1 模型设计
本实验使用双向长短期记忆网络(Bi-LSTM)和 Attention机制实现新闻标题的文本分类模型建模,如 图7 所示。
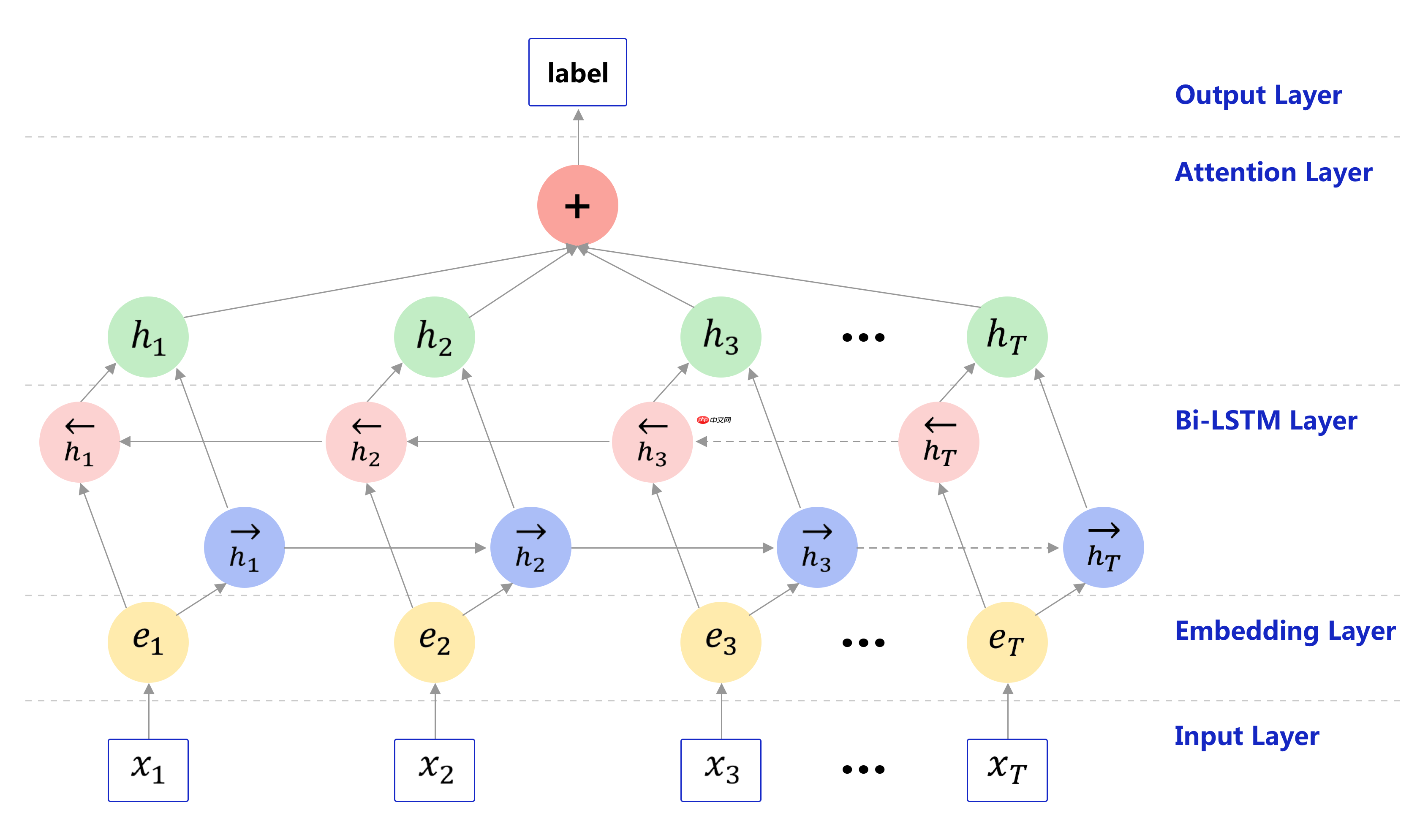
图7 文本分类网络示意图
- 对于给定的一个新闻文本,经过分词后,便可获得一串单词序列(x1……xT),每个单词均可映射为对应的词向量(e1……eT),将这些词向量,按照时间步骤依次传入Bi-LSTM中;
- Bi-LSTM接收到这些向量后,会在每个单词的位置输出一个前向向量 hi→ 和后向向量 hi←,然后将每个时间步骤对应的两个向量进行拼接,作为最终的输出向量 hi。由于hi融合了上下文信息,暂且称之为上下文向量;
- 在这些上下文向量中应用Attention机制,获得整个文本序列的语义向量;
- 将语义向量传入全连接层和softmax,就可以得到这个新闻标题的文本类别。
本实验的文本分类网络使用到了两个概念:Bi-LSTM和Attention机制,下面详细阐述下实现原理。
- Bi-LSTM(双向长短期记忆网络)
如 图7 所示,Bi-LSTM其实是按照时间步骤,将单词对应的词向量(e1……eT)从前向后传递一遍 hi→,再从后向前传递一遍 hi←,因此每个时间步骤对应着2个输出的隐状态向量。将这两个向量进行concat拼接,作为对应的输出hi。这样的前后向设计能够让每个时刻输出的向量既包含了左边序列的信息,又包含了右边序列的信息。与单向LSTM比较,可以获取更加全面的语义信息。
Bi-LSTM的设计逻辑和单向LSTM其实一致的,都是时序模型结构,只是增加了一个反向传递过程而已,每个时刻的输出是正反向隐状态拼接的向量。
- Attention机制
应用Attention机制,能够帮助模型快速获取到一个文本序列的核心单词,举个例子:
今年苹果是真的不好,连个充电器都不给送了!
当你看前半句话的时候,很可能会认为今年苹果质量不行,个头小又不甜;但当你看到后半句话出现了“充电器“的时候,再结合前半句的”苹果“,那就很容易识别,这是一条科技新闻。在这句话中,”苹果“和”充电器“是两个非常关键的单词,当使用Attention机制的时候,能够让模型更加关注这个两个词,从而获得更准确的分类结果。
将这句话进行分词,如 图8 所示,分成了11个词,记为T,T=11。

图8 分词结果
假如使用 hi 表示第ⅈ个词对应的向量;hs 表示每个向量的长度;H=[h2;h2;...hT]表示一个向量矩阵,它包含了所有的向量,那么它的shape就是 [T,hs]。其中每行代表一个向量。如:第0行的向量 [0,hs] 是单词“今天”的向量;第3行的向量 [1,hs] 是单词“真的”的向量,依次类推。 利用如下公式计算每个单词对应的权重,即模型对每个单词的关注程度,并算出最终文本串对应的语义向量。
A=softmax(Vtanh(WHT))
C=AH

参数含义如下:
- H: [T,hs],表示一共有T个向量,每个向量hs维;
- HT: [hs,T], H的矩阵转置,可以认为一共有T列,每列代表一个向量,每个向量有hs行;
- W: [hs,hs],一个可学习、可训练的参数矩阵;
- V: [1,hs],一个可学习、可训练的参数向量。
将这些矩阵或向量进行计算,将上述公式拆解为如下5步。
1)WHT: [hs,hs] × [hs,T] = [hs,T]
对原始向量H进行线性变换。
2)tanh(WHT): [hs,T]
tanh是激活函数,将WHT的结果映射到值域[-1, 1]之间,它不会改变矩阵的shape,结果依然是每列代表一个向量,每个向量有hs行。
3)Vtanh(WHT): [1,hs] × [hs,T] = [1,T]
向量V与每个单词对应的向量进行点积运算,从而得到模型对每个向量需要的关注程度。如:向量V与第0列向量(单词“今天”对应的向量)进行点积运算,可以得到一个标量数据,假设这个数字是1.3,它代表了模型聚焦在单词“今天”的分数(模型对这个单词的关注程度)。上面那句话的长度 是T=11,因此会获得11个分数。
4)A=softmax(Vtanh(WHT)): [1,T]
上一步计算出了每个向量的分数,但数据没有归一化,经过softmax将数值映射到[0,1]之间,并且各个数值的加和为1,每个数值即为模型在这个文本序列中需要关注到对应单词向量的权重。假设归一化后,上面句子的每个单词对应权重如 图9 所示。之后进行加权求和,计算出原始这串文本的最终语义向量。

图9 权重分布
5)C=AH: [1,T] × [T,hs] = [1,hs],
每个单词的权重和对应的向量相乘,然后将所有的结果相加。如:用0.1乘以“今年”的向量, 0.3乘以“苹果”的向量,0.01乘以“是”的向量等,然后将乘积结果相加,得到上面那句话的语义向量。
说明:
通过注意力机制计算出了每个单词对应的权重,权重大的单词被重点关注,权重小的单词少点关注,想法是不是很朴素,实现是不是很简单呢!
2.2.2 模型实现
为方便代码阅读,将Attention单独作为一个类层去实现, 输入是双向LSTM各个时刻的输出,输出是语义向量,实现代码如下。
class AttentionLayer(paddle.nn.Layer):
def __init__(self, hidden_size, init_scale=0.1):
super(AttentionLayer, self).__init__()
self.w = paddle.create_parameter(shape=[hidden_size, hidden_size], dtype="float32")
self.v = paddle.create_parameter(shape=[1, hidden_size], dtype="float32") def forward(self, inputs):
# inputs: [batch_size, seq_len, hidden_size]
last_layers_hiddens = inputs # transposed inputs: [batch_size, hidden_size, seq_len]
inputs = paddle.transpose(inputs, perm=[0, 2, 1]) # inputs: [batch_size, hidden_size, seq_len]
inputs = paddle.tanh(paddle.matmul(self.w, inputs)) # attn_weights: [batch_size, 1, seq_len]
attn_weights = paddle.matmul(self.v, inputs) # softmax数值归一化
attn_weights = F.softmax(attn_weights, axis=-1) # 通过attention后的向量值, attn_vectors: [batch_size, 1, hidden_size]
attn_vectors = paddle.matmul(attn_weights, last_layers_hiddens) # attn_vectors: [batch_size, hidden_size]
attn_vectors = paddle.squeeze(attn_vectors, axis=1) return attn_vectors
下面实现整体的模型结构,包括双向LSTM和已经定义的Attention。模型输入是数据处理后的文本,模型输出是文本对应的新闻类别,实现代码如下。
class Classifier(paddle.nn.Layer):
def __init__(self, hidden_size, embedding_size, vocab_size, n_classes=14, n_layers=1, direction="bidirectional",
dropout_rate=0., init_scale=0.05):
super(Classifier, self).__init__() # 表示LSTM单元的隐藏神经元数量,它也将用来表示hidden和cell向量状态的维度
self.hidden_size = hidden_size # 表示词向量的维度
self.embedding_size = embedding_size # 表示神经元的dropout概率
self.dropout_rate = dropout_rate # 表示词典的的单词数量
self.vocab_size = vocab_size # 表示文本分类的类别数量
self.n_classes = n_classes # 表示LSTM的层数
self.n_layers = n_layers # 用来设置参数初始化范围
self.init_scale = init_scale # 定义embedding层
self.embedding = paddle.nn.Embedding(num_embeddings=self.vocab_size, embedding_dim=self.embedding_size,
weight_attr=paddle.ParamAttr(
initializer=I.Uniform(low=-self.init_scale, high=self.init_scale)))
# 定义LSTM,它将用来编码网络
self.lstm = paddle.nn.LSTM(input_size=self.embedding_size, hidden_size=self.hidden_size,
num_layers=self.n_layers, direction=direction,
dropout=self.dropout_rate) # 对词向量进行dropout
self.dropout_emb = paddle.nn.Dropout(p=self.dropout_rate, mode="upscale_in_train") # 定义Attention层
self.attention = AttentionLayer(hidden_size=hidden_size*2 if direction == "bidirectional" else hidden_size) # 定义分类层,用于将语义向量映射到相应的类别
self.cls_fc = paddle.nn.Linear(in_features=self.hidden_size*2 if direction == "bidirectional" else hidden_size,
out_features=self.n_classes) def forward(self, inputs):
# 获取训练的batch_size
batch_size = inputs.shape[0] # 获取词向量并且进行dropout
embedded_input = self.embedding(inputs) if self.dropout_rate > 0.:
embedded_input = self.dropout_emb(embedded_input) # 使用LSTM进行语义编码
last_layers_hiddens, (last_step_hiddens, last_step_cells) = self.lstm(embedded_input) # 进行Attention, attn_weights: [batch_size, seq_len]
attn_vectors = self.attention(last_layers_hiddens) # 通过attention后的向量值, attn_vector: [batch_size, 1, hidden_size]
# attn_vector = paddle.matmul(attn_weights, last_layers_hiddens)
# attn_vector: [batch_size, hidden_size]
# attn_vector = paddle.squeeze(attn_vector, axis=1)
# 将其通过分类线性层,获得初步的类别数值
logits = self.cls_fc(attn_vectors) return logits
2.3 训练配置
定义模型训练时用到的组件和资源,包括定义模型的实例化对象,指定模型训练迭代的优化算法等。本实验将使用paddle.optimizer.Adam() 优化器进行模型迭代优化,训练配置的实现代码如下。
# 加载数据集root_path = "./dataset/"train_set, test_set, word_dict, label_dict = load_dataset(root_path)
train_set = convert_corpus_to_id(train_set, word_dict, label_dict)
test_set = convert_corpus_to_id(test_set, word_dict, label_dict)
id2label = dict([(item[1], item[0]) for item in label_dict.items()])# 参数设置n_epochs = 3vocab_size = len(word_dict.keys())print(vocab_size)
batch_size = 128hidden_size = 128embedding_size = 128n_classes = 14max_seq_len = 32n_layers = 1dropout_rate = 0.2learning_rate = 0.0001direction = "bidirectional"# 检测是否可以使用GPU,如果可以优先使用GPUuse_gpu = True if paddle.get_device().startswith("gpu") else Falseif use_gpu:
paddle.set_device('gpu:0')# 实例化模型classifier = Classifier(hidden_size, embedding_size, vocab_size, n_classes=n_classes, n_layers=n_layers,
direction=direction, dropout_rate=dropout_rate)# 指定优化器optimizer = paddle.optimizer.Adam(learning_rate=learning_rate, beta1=0.9, beta2=0.99,
parameters=classifier.parameters())
Building prefix dict from the default dictionary ... 2022-02-11 19:11:05,089 - DEBUG - Building prefix dict from the default dictionary ... Dumping model to file cache /tmp/jieba.cache 2022-02-11 19:11:05,876 - DEBUG - Dumping model to file cache /tmp/jieba.cache Loading model cost 0.856 seconds. 2022-02-11 19:11:05,947 - DEBUG - Loading model cost 0.856 seconds. Prefix dict has been built successfully. 2022-02-11 19:11:05,948 - DEBUG - Prefix dict has been built successfully.
说明:
每种优化算法均有更多的参数设置,详情可查阅飞桨的官方API文档。理论最合理的未必在具体案例中最有效,所以模型调参是很有必要的,最优的模型配置往往是在一定“理论”和“经验”的指导下实验出来的。
2.4.1 训练与评估过程
在训练过程可以分为四步:获取数据、传入模型进行前向计算、反向传播和参数更新,每次迭代都是在循环执行这四个步骤。此外,在训练过程中,每训练完一轮进行一次模型评估,查看模型训练的效果。
具体地,THUCNews数据集共有14个新闻类别,模型将统计每个类别的新闻以及全部新闻的精准率precision、召回率recall和F1值,作为本实验的评估指标。以财经类别为例,假设测试集样本中所有的财经新闻数量为 T,所有预测为财经的新闻数量为 P,其中预测正确的财经新闻数量为 C,则可按照如下公式计算财经新闻的准确率、召回率和F1值。
precision=PC
recall=TC
F1=precision+recall2∗precision∗recall
模型训练和评估实现代码如下所示。
from utils.metric import Metric# 模型评估代码def evaluate(model):
model.eval()
metric = Metric(id2label) for batch_texts, batch_labels in build_batch(test_set, batch_size, max_seq_len, shuffle=False, pad_id=word_dict["[pad]"]): # 将数据转换为Tensor类型
batch_texts = paddle.to_tensor(batch_texts)
batch_labels = paddle.to_tensor(batch_labels) # 执行模型的前向计算
logits = model(batch_texts) # 使用softmax进行归一化
probs = F.softmax(logits)
probs = paddle.argmax(probs, axis=1).numpy()
batch_labels = batch_labels.squeeze().numpy()
metric.update(real_labels=batch_labels, pred_labels=probs)
result = metric.get_result()
metric.format_print(result)# 模型训练代码# 记录训练过程中的中间变量loss_records = []def train(model):
global_step = 0
for epoch in range(n_epochs):
model.train() for step, (batch_texts, batch_labels) in enumerate(build_batch(train_set, batch_size, max_seq_len, shuffle=True, pad_id=word_dict["[pad]"])): # 将数据转换为Tensor类型
batch_texts = paddle.to_tensor(batch_texts)
batch_labels = paddle.to_tensor(batch_labels) # 执行模型的前向计算
logits = model(batch_texts) # 计算损失
losses = F.cross_entropy(input=logits, label=batch_labels, soft_label=False)
loss = paddle.mean(losses)
loss.backward()
optimizer.step()
optimizer.clear_gradients() if step % 200 == 0:
loss_records.append((global_step, loss.numpy()[0])) print(f"Epoch: {epoch+1}/{n_epochs} - Step: {step} - Loss: {loss.numpy()[0]}")
global_step += 1
# 模型评估
evaluate(model)# 训练模型train(classifier)
2.4.2 训练可视化
训练过程中,每隔200 steps记录一下Loss,以观察模型训练效果,代码实现如下。
import matplotlib.pyplot as plt# 开始画图,横轴是训练step,纵轴是损失loss_records = np.array(loss_records)
steps, losses = loss_records[:, 0], loss_records[:, 1]
plt.plot(steps, losses, "-o")
plt.xlabel("step")
plt.ylabel("loss")
plt.savefig("./loss.png")
plt.show()
上图展示了Loss的变化情况,其中纵轴代表Loss值,横轴代表训练的step。整体来看,Loss随着训练的步骤的增加而不断下降,最终达到平稳,这说明本次实验中模型的训练是有效的。
2.5 模型保存
将训练完成后的模型和优化器参数保存到磁盘,用于模型推理或继续训练。实现代码如下所示,通过使用 paddle.save API 实现模型参数和优化器参数的保存。
# 模型保存的名称model_name = "classifier"# 保存模型paddle.save(classifier.state_dict(), "{}.pdparams".format(model_name))
paddle.save(optimizer.state_dict(), "{}.optparams".format(model_name))
2.6 模型推理
任意输入一个新闻标题文本,如:“习主席对职业教育工作作出重要指示”,通过模型推理验证模型训练效果,实现代码如下。
# 模型预测代码def infer(model, text):
model.eval() # 数据处理
tokens = [word_dict.get(word, word_dict["[oov]"]) for word in jieba.cut(text)] # 构造输入模型的数据
tokens = paddle.to_tensor(tokens, dtype="int64").unsqueeze(0) # 计算发射分数
logits = model(tokens)
probs = F.softmax(logits) # 解析出分数最大的标签
max_label_id = paddle.argmax(logits, axis=1).numpy()[0]
pred_label = id2label[max_label_id] print("Label: ", pred_label)
title = "习主席对职业教育工作作出重要指示"infer(classifier, title)




























