






Abstract(摘要)
众所周知,深度神经网络(dnns)是一种强大的模型,在困难的学习任务上取得了优异的性能。虽然dnns在大型标记训练集中工作得很好,但它们不能用于将序列映射到序列。在本文中,作者提出了一种通用的端到端序列学习方法seq2seq,即使用多层长短期记忆(lstm)将输入序列映射到一个固定维的向量,然后使用另一个深度lstm从向量解码至目标序列。最后,作者发现,在所有源句(但不是目标句)中反转单词的顺序显著提高了lstm的性能,因为这样做在源句和目标句之间引入了许多短期依赖关系,这使得优化问题更容易。
Introduction(介绍)
本文的seq2seq由encoder与decoder组成,首先将源语句输入至encoder编码为一个向量,我们称为上下文向量,它可以视为整个输入句子的抽象表示。然后,该向量由第二个LSTM解码,该LSTM通过一次生成一个单词来学习输出目标语句。下面给出一个文本翻译的栗子
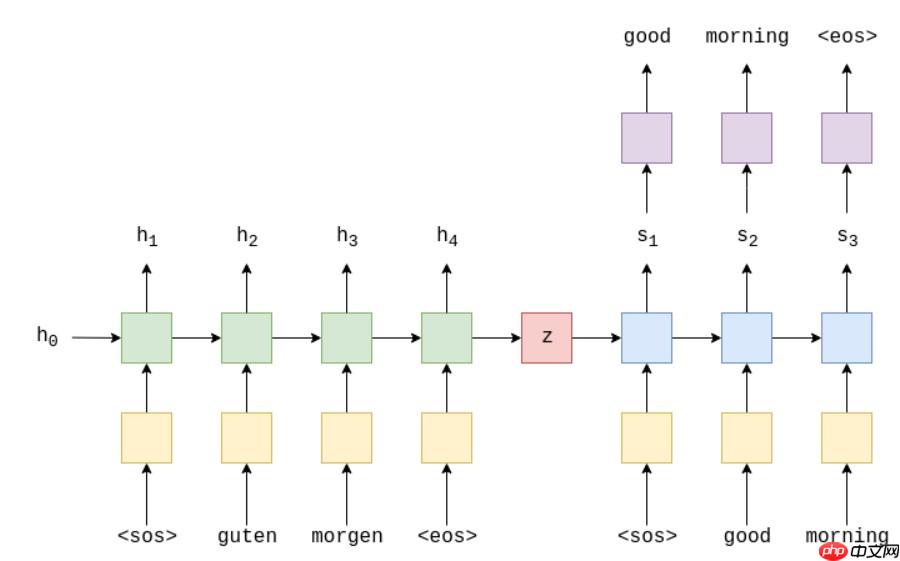
源语句被输入至embedding层(黄色),然后被输入编码器(绿色),我们还分别将序列的开始()和序列的结束()标记附加到句子的开始和结尾,sos为start of sentence,eos为end of sentence。在每一个时间步,我们输入给encoder当前的单词以及上一个时间步的隐藏状态h_t-1,encoder吐出新的h_t,这个tensor可以视为目前为止的句子的抽象表示。这个RNN可以表示为一个方程: ht=EncoderRNN(emb(xt),ht-1) 这里的RNN可以是LSTM或GRU或任何RNN的变体。在最后一个时间步,我们将h_T赋给z,作为decoder的输入。
在每个时间步,解码器RNN(蓝色)的输入是当前单词的嵌入,以及上一个时间步的隐藏状态,其中初始解码器隐藏状态就是上下文向量,即初始解码器隐藏状态是最终编码器隐藏状态。因此,方程为 s_t=DecoderRNN(emb(y_t,x_t-1) ,然后在每一个时间步,我们将s_t输入给线形层(紫色),得到y_t_hat,即 y_t_hat=f(s_t) ,而后用y_hat与y进行交叉熵计算,得到损失,并优化参数。
The Model(模型)
Encoder(编码器)
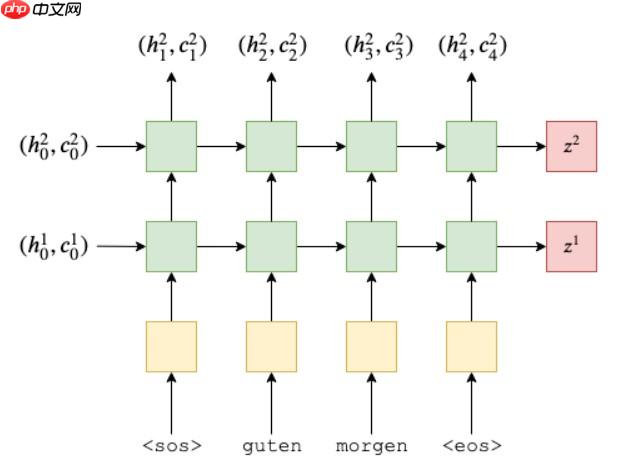
在前向计算中,我们传入源语句,并使用嵌入层将其转换为密集向量,然后应用dropout。 然后将这些嵌入传递到RNN。 当我们将整个序列传递给RNN时,它将为我们自动对整个序列进行隐藏状态的递归计算。请注意,我们没有将初始的隐藏状态或单元状态传递给RNN。 这是因为,如paddle文档中所述,如果没有任何隐藏/单元状态传递给RNN,它将自动创建初始隐藏/单元状态作为全零的张量。

Decoder(解码器)
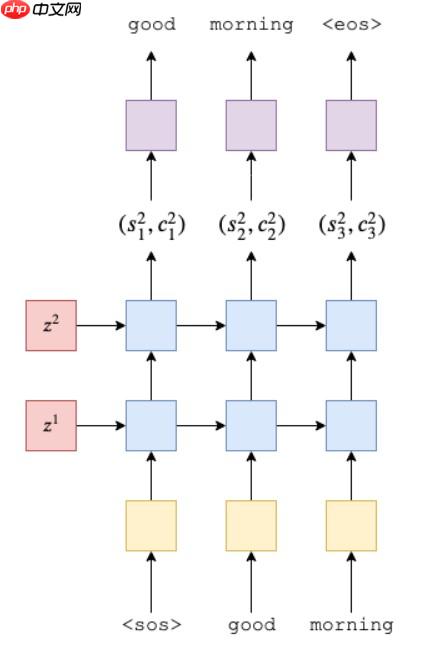
解码器执行解码的单个步骤,即,每个时间步输出单个token。 第一层将从上一时间步中接收到一个隐藏的单元格状态,并将其与当前嵌入的token一起通过LSTM馈送,以产生一个新的隐藏的单元格状态。 后续层将使用下一层的隐藏状态,以及其图层中先前的隐藏状态和单元格状态。
Decoder的参数与encoder类似,但要注意它们的hid_dim要相同,否则矩阵无法运算。
seq2seq(序列到序列)
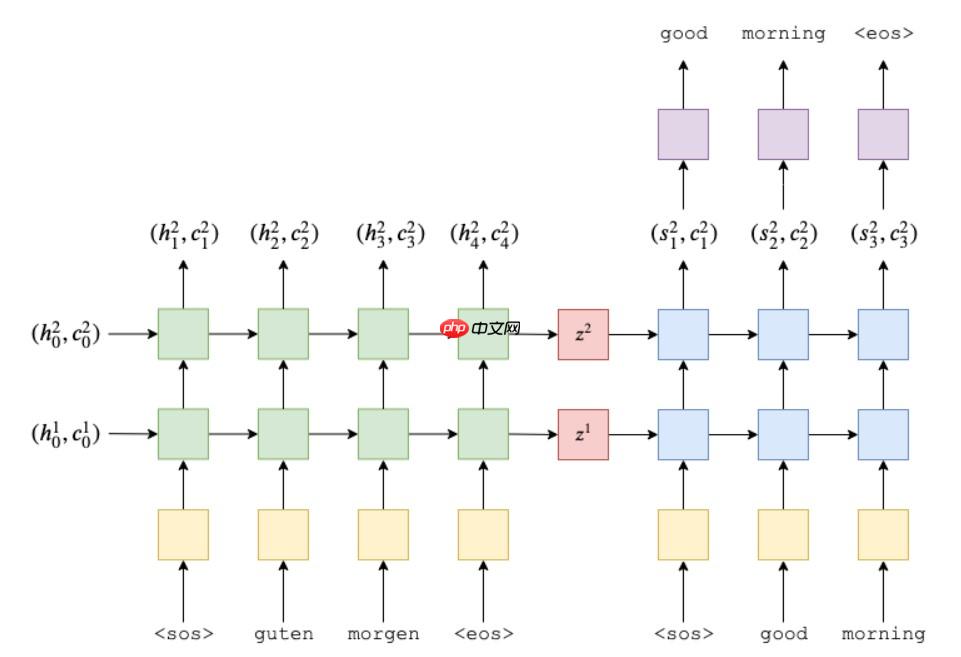

Implement(实作)
读取数据集与数据预处理
import numpy as npimport re#将无效字符去掉with open("data/data86810/human_chat.txt","r",encoding="utf-8") as f:
data=f.read().replace("Human 1"," ").replace("Human 2"," ").replace("."," ").replace("*"," ").replace("@"," ").replace("^"," ").replace("&"," ").replace("!"," ").replace("#"," ").replace("$"," ").replace("?"," ").replace(";"," ").replace(":"," ").replace(","," ").replace('"',' ').replace("%"," ").replace("/"," ").replace("@"," ").replace("("," ").replace(")"," ").replace("'"," ").lower()
data=list(data.split("\n"))#print(len(data))lst=[]#分割出单词,连成序列for obj in data:
sen=list(obj.split(" "))
lst.append(sen)#print(len(lst))#将字符连接起来,制作字典string=" ".join(data)#将特殊字符添入string1="pad sos eos"#合并字符串string=string+string1#string=string.replace(''," ")#使用正则分割,防止有多个空格words=re.split(" +",string)#使用集合,防止单词重复words=list(set(words))print(len(words))#获取字典dic=dict([(word,i) for i,word in enumerate(words)])#存储对话序列index_data=[]#每句话的长度,短句添加"pad",长句切至10sen_len=10for i,sen in enumerate(lst): #token映射至index,并防止出现空字符
sen=[dic[word] for word in sen if word!=''] #在开头添加"sos"
sen.insert(0,dic["sos"]) while len(sen)<sen_len-1: #填充"pad",防止长度不够
sen.append(dic["pad"]) #切取sen_len-1个词
sen=sen[:sen_len-1] #末尾添加"eos"
sen.append(dic["eos"]) #将ask与answer分割
if i%2==0:
one=[]
one.append(sen) else:
one.append(sen)
index_data.append(one)#print(len(index_data))index_data=np.array(index_data)print(index_data.shape)print(index_data[0])#挑一个看看效果ask,ans=index_data[3]#将index序列转化为字符串ask_str=[words[i] for i in ask]
ans_str=[words[i] for i in ans]print(ask_str)print(ans_str)#print(dic)
定义数据读取器
import paddlefrom paddle.io import Dataset,DataLoaderimport paddle.nn as nnimport random#batch大小batch_size=128class Mydataset(Dataset):
def __init__(self,index_data,dic):
super(Mydataset, self).__init__()
self.index_data=index_data
self.dic=dic def __getitem__(self,index):
ask_data,ans_data=self.index_data[index] #ask部分倒序,引入更多短期依赖关系
ask_data,ans_data=ask_data[:][::-1],ans_data return ask_data,ans_data def __len__(self):
return self.index_data.shape[0]#实例化读取器dataset=Mydataset(index_data,dic)#封装为迭代器dataloader=DataLoader(dataset,batch_size=batch_size,shuffle=True,drop_last=True)#看看效果for _,__ in dataloader(): #print(_,__)
break
定义Encoder
class Encoder(nn.Layer):
def __init__(self,vocab_size,emb_dim,hid_dim,drop_out,n_layers):
#vocab_size:输入张量的维度,即字典的大小
#emb_dim:嵌入层的维度
#hid_dim:隐藏状态与单元状态的维度
#n_layers:RNN的层数
#dropout:丢弃的概率,防止过拟合
super(Encoder, self).__init__()
self.hid_dim=hid_dim
self.n_layers=n_layers
self.emb=nn.Embedding(vocab_size,emb_dim) #[batch_size,vocab_size,hid_dim]
self.lstm=nn.LSTM(emb_dim,hid_dim,n_layers)
self.drop=nn.Dropout(drop_out) def forward(self,x):
#src:[batch_size,sen_len]
x=self.drop(self.emb(x)) #x:[batch_size,sen_len,emb_dim]
y,(h,c)=self.lstm(x) #y:[batch size,sen_len,hid dim*n_directions]
#h:[n layers*n_directions,batch_size,hid_dim]
#c:[n layers*n_directions,batch size,hid_dim]
return h,c
vocab_size=len(dic)
emb_dim=128hid_dim=256drop_out=0.7n_layers=2#实例化encoderencoder=Encoder(vocab_size,emb_dim,hid_dim,drop_out,n_layers)
x=paddle.randint(0,1000,[batch_size,sen_len])
h,c=encoder(x)#看看形状print(h.shape,c.shape)
定义Decoder
class Decoder(nn.Layer):
def __init__(self,vocab_size,emb_dim,hid_dim,drop_out,n_layers):
super(Decoder, self).__init__()
self.vocab_size=vocab_size
self.emb_dim=emb_dim
self.hid_dim=hid_dim
self.emb=nn.Embedding(vocab_size,emb_dim)
self.lstm=nn.LSTM(emb_dim,hid_dim,n_layers)
self.drop=nn.Dropout(drop_out)
self.fc=nn.Linear(hid_dim,vocab_size) def forward(self,x,hidden,cell):
#x = [batch_size]
#hidden = [n_layers*n_directions, batch_size, hid_dim]
#cell = [n_layers*n_directions, batch_size, hid_dim]
#扩维
x=paddle.unsqueeze(x,axis=1) #x=[batch_size,1]
x=self.drop(self.emb(x)) #x=[batch_size,emb_dim]
output,(h,c)=self.lstm(x,(hidden,cell)) #output = [batch_size,1, hid_dim * n_directions]
#hidden = [n_layers * n_directions, batch_size, hid_dim]
#cell = [n_layers * n_directions, batch_size, hid_dim]
prediction=self.fc(output.squeeze(1)) #prediction=[batch_size,vocab_size]
return prediction,h,c
decoder=Decoder(vocab_size,emb_dim,hid_dim,drop_out,n_layers)
x=paddle.randint(0,1000,[batch_size])
y,h,c=decoder(x,h,c)print(y.shape)
定义Seq2Seq
import randomclass seq2seq(nn.Layer):
def __init__(self,encoder,decoder):
super(seq2seq, self).__init__()
nn.initializer.set_global_initializer(nn.initializer.XavierNormal(),nn.initializer.Constant(0.))
self.encoder=encoder
self.decoder=decoder def forward(self,source,target,teacher_forcing_ratio=0.5):
#src = [batch_size,src_len]
#trg = [batch_size,trg_len]
#teacher_forcing_ratio is probability to use teacher forcing
target_len=target.shape[1]
batch_size=target.shape[0]
outputs=paddle.zeros([target_len,batch_size,decoder.vocab_size]) #outputs=[tar_len,batch_size,vocab_size]
hidden,cell=self.encoder(source) #x为第一个词"sos"
x=target[:,0] #loop (tar_len-1)次
for t in range(1,target_len):
output,hidden,cell=self.decoder(x,hidden,cell) #保存token的张量
outputs[t]=output #判断是否动用teacher_forcing
flag=random.random()<teacher_forcing_ratio #目标token
top1=paddle.argmax(output,axis=1) #x为下一个输入token
x=target[:,t] if flag else top1 return outputs
x=paddle.randint(0,1000,[20,sen_len])
y=paddle.randint(0,1000,[20,sen_len])
model=seq2seq(encoder,decoder)
predict=model(x,y)print(predict.shape)
定义初始化函数
#截断梯度@paddle.no_grad()def init_weights(m):
for name, param in m.named_parameters(): #均匀分布初始化
param.data=paddle.uniform(min=-0.2,max=0.2,shape=param.shape)#模型初始化model.apply(init_weights)
定义测试函数
def check(str_lst):
index_set=set(str_lst) #筛掉重复的单词
lst=list(index_set) #重复次数
zeros=[0 for index in lst] #组合为字典
index_dic=dict(zip(lst,zeros))
index_list=[] #找出重复的index地方
for i in range(len(str_lst)):
index=str_lst[i] if index in index_set:
index_dic[index]+=1
if index_dic[index]>1:
index_list.append(i) #删除重复处
str_lst=np.delete(str_lst,index_list)
str_lst=paddle.to_tensor(str_lst,dtype="int64") return str_lst
arr=np.array([1,2,3,4,1,1,2,2])print(check(arr))
#测试函数def evaluate(model,ask_sen=ask):
ask_sen=paddle.to_tensor(ask_sen).unsqueeze(axis=0) #tar设为全零张量
tar=paddle.zeros([1,sen_len]) #第一个token设为"sos"
tar[0,0]=dic["sos"]
tar=tar.astype("int64") #获取answer
ans=model(ask_sen,tar,0) #压扁batch_size层
ans=ans.squeeze(axis=1) #获取概率最大的token
ans=ans.argmax(axis=1)
ans=check(ans.numpy()) #获取字符串
ans_str=[words[i] for i in ans] #连接字符串
string=" ".join(ans_str) return stringprint(evaluate(model,ask))
开启训练
learning_rate=2e-4epoch_num=1000#梯度裁剪,防止LSTM梯度爆炸clip_grad=nn.ClipGradByNorm(1)#设定loss,并忽略"pad"这个tokenloss=nn.CrossEntropyLoss(ignore_index=dic["pad"])#实例化优化器optimize=paddle.optimizer.Momentum(learning_rate,parameters=model.parameters(),grad_clip=clip_grad)
model.train()for epoch in range(epoch_num): for i,(user_data,assist_data) in enumerate(dataloader()): #清除梯度
optimize.clear_grad() #获取预测张量
predict=model(user_data,assist_data,0) #将predict展开,并去掉第一个词
predict=paddle.reshape(predict[1:],[-1,vocab_size]) #将assist_data展开,并去掉第一个词
assist_data=paddle.reshape(assist_data[:,1:],[-1]) #原predict=[0,y_hat1,y_hat2...]
#原assist_data=["sos",y1,y2...]
#因此要将第一个词去掉
predict=paddle.to_tensor(predict,dtype="float32")
str_predict=predict.argmax(axis=1)
str_del=check(str_predict.numpy()) #print("predict:",str_predict)
#print("del:",str_del)
num=str_predict.shape[0]-str_del.shape[0]
assist_data=paddle.to_tensor(assist_data,dtype="int64") #获取损失值
avg_loss=loss(predict,assist_data) #print(avg_loss.numpy(),num)
avg_loss+=num #反向传播求梯度
avg_loss.backward() #优化参数
optimize.minimize(avg_loss) #清除梯度
optimize.clear_grad() if i%10==0: print("epoch:%d,i:%d,loss:%f"%(epoch,i,avg_loss.numpy())) print(evaluate(model,index_data[random.randint(0,500)][0])) if epoch%10==0: #保存模型参数
paddle.save(model.state_dict(),"work/seq2seq.pdparams")
载入参数
encoder=Encoder(vocab_size,emb_dim,hid_dim,drop_out,n_layers)
decoder=Decoder(vocab_size,emb_dim,hid_dim,drop_out,n_layers)
model=seq2seq(encoder,decoder)
state_dict=paddle.load("work/seq2seq.pdparams")
model.load_dict(state_dict)
结果展示
def transform(index_tensor):
string=[words[i] for i in index_tensor] return " ".join(string)
print("human 1:",transform(index_data[0][0]))print("human 2",evaluate(model,index_data[0][0]))print("human 1",transform(index_data[100][0]))print("human 2",evaluate(model,index_data[100][0]))print("human 1",transform(index_data[200][0]))print("human 2",evaluate(model,index_data[200][0]))
human 1: sos hi pad pad pad pad pad pad pad eos human 2 forgot chopping storm yet helloooooo know difficult human 1 sos lol ok pad pad pad pad pad pad eos human 2 common minimalist humid listen bad used scare human 1 sos nice do you refer to work or anything eos human 2 owner copying rarely beyonce japanese laughter managed come
- emmmm,第一个说你好,AI的回应里面好歹也有一个hello,也算贴合主题。
- 第二个说lol。。。是英雄联盟?意思是英雄联盟很OK,AI回答常见的极简主义听上去很辣鸡。。。AI在评价lol很辣鸡?
- 第三个说你指的是工作还是其它的。AI回应说自己的拷贝很少,连日本人都笑了。大概是想说自己的代码拷贝很少,蛮好的
总的来看,AI的回应还算切合主题,结果还行。




























