






本文介绍了基于paddle模型库在intel ai box边缘设备上部署简易ai“朗读机”的项目。该设备可识别实体书或a4纸文字,按空格键即可发声并截图。部署涉及paddleocr、paddlespeech等,提供了从paddlehub和paddlespeech调用语音合成模型的两种方式,后者支持更多预训练模型及自定义优化,设备类似预装windows系统的pc。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

0 背景介绍
现下,随着各种流行APP的出现,“听书”已经成为一种新的读书方式。不过,相比起电子书软件,要从实体书本中“听书”,就存在不少困难。
比如,电子书软件天然就有准确的文本输入,只需要解决语音合成问题——当然,这看似简单的一步,其实一点也不简单,比如要做好分词、断句,语音合成模型需要在海量数据集上训练等等。
相比之下,从实体书里“听书”,难度则又加了几层——如何做精准的OCR识别?如何把断行的合成语音重整?如何实现点读?实时性如何保证?
接下来这个新系列,我们将开始探索如何基于Paddle模型库实现一个用户体验良好的“点读机”。
还是遵循从易到难的原则,现在,就让我们先开发一个最简单的AI“朗读机”。
1 项目效果展示
在本项目中,我们基于PaddleOCR + PaddleSpeech(PaddleHub)+ OpenVINO,在Intel AI BOX边缘设备上部署了一个简易的AI“朗读机”。不管是实体书还是A4纸,只要送到它面前,只需根据识别效果调整好摆放位置,当用户按下空格键时,就能发出语音,并截下对应时刻的识别图片。
1.1 AI“朗读机”实时展示效果

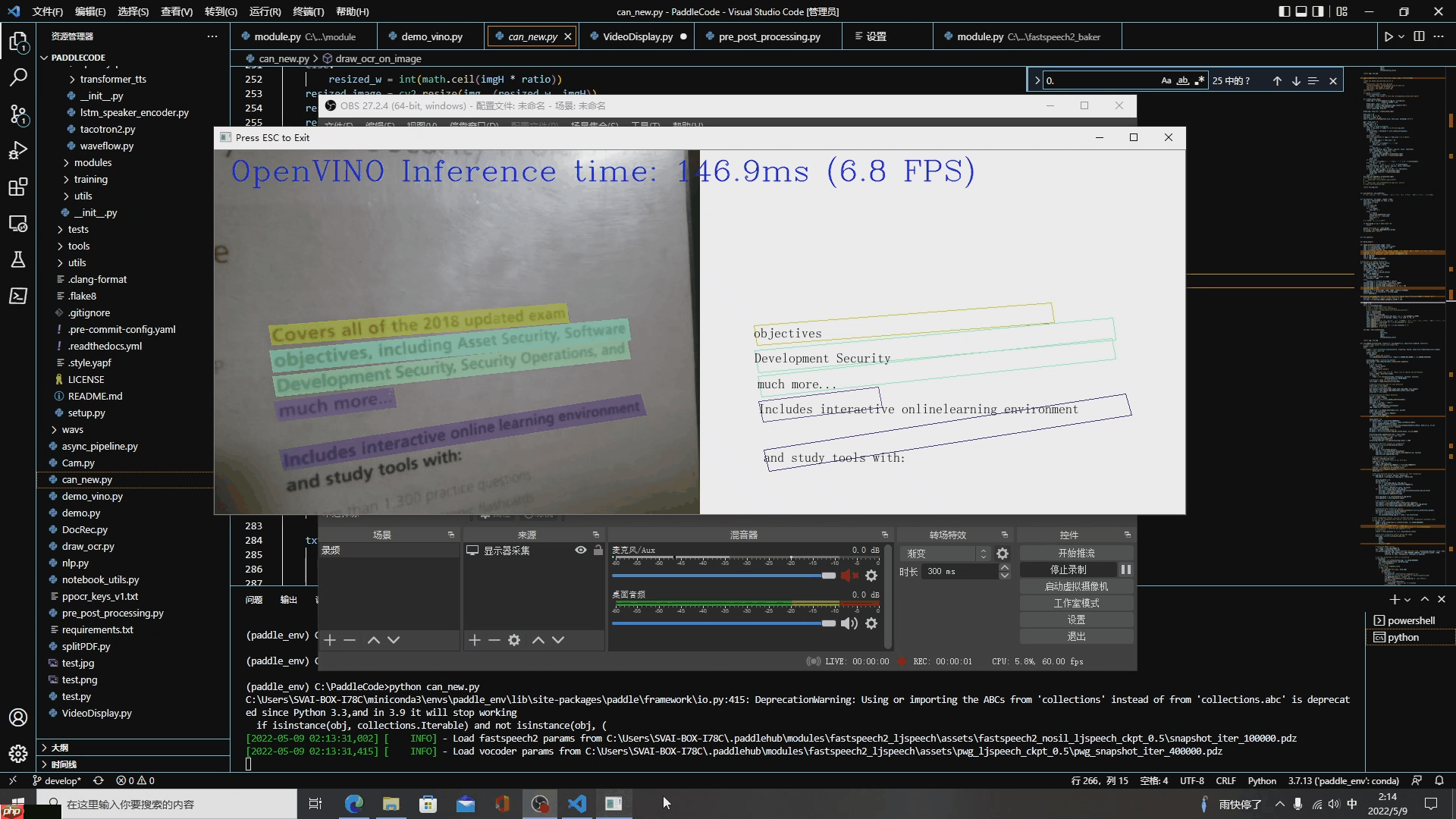
1.2 AI“朗读机”运行效果展示
In [1]
from IPython.display import Video
In [2]
Video('2022-05-09 02-16-02.mkv')<IPython.core.display.Video object>
In [3]
Video('2022-05-09 02-13-59.mkv')<IPython.core.display.Video object>
1.3 Intel AI BOX和摄像识别设备安装图

2 部署设备简介

参考链接:搭载第 11 代智能英特尔® 酷睿™ U 系列 CPU 和 Hailo-8™ M.2 AI 加速模块的 ASB210-953-AI 边缘 AI 计算系统

Intel AI BOX我们完全可以把它当一台主机用。同时,因为它预装了Windows系统,所以可以认为,就是大多数人常用的PC设备。

当然,正因为它预装的是Windows系统,在部署操作中,我们将只能使用PaddleSpeech的基本语音合成功能。
PaddleSpeech 有三种安装方法。根据安装的难易程度,这三种方法可以分为 简单, 中等 和 困难.
方式 功能 支持系统 简单 (1) 使用 PaddleSpeech 的命令行功能. (2) 在 Aistudio上体验 PaddleSpeech. Linux, Mac(不支持M1芯片),Windows 中等 支持 PaddleSpeech 主要功能,比如使用已有 examples 中的模型和使用 PaddleSpeech 来训练自己的模型. Linux 困难 支持 PaddleSpeech 的各项功能,包含结合kaldi使用 join ctc decoder 方式解码,训练语言模型,使用强制对齐等。并且你更能成为一名开发者! Ubuntu
3 部署流程
3.1 从PaddleHub调用语音合成模型
这部分内容其实在上一个项目【PaddlePaddle+OpenVINO】打造一个会发声的电表检测识别器中已经很详细地介绍了,这里总结几个需要做的重点过程,并与PaddleSpeech的安装进行对比:
- 先安装Parakeet
- 其实现在PaddleSpeech暂时也只是把Parakeet合并了过去,我们要用到的中英文语音合成的预训练模型,也都是之前Parakeet训练的;而PaddleSpeech与PaddleHub的区别,只是在于PaddleSpeech的安装过程基本可以做到用户“无感”
- 准备nltk_data文件
- 相比之下,PaddleSpeech在这块的巨大进步在于,nltk_data的准备也做到了用户“无感”,会直接去拉取百度的镜像文件安装,特别贴心!
- 设置截图和语音合成按键
- 对于纸质版的文字材料,OCR识别的准确率还是不太好控制的,所以,如果一上来直接识别,效果肯定不好。因此可以考虑通过按键、按钮控制,让用户选择效果比较稳定的识别帧,截图传入语音合成pipeline开始发音
- 另一方面,这也是从用户体验出发的考虑,否则整个流程会非常卡顿
- 使用playsound播放连续音频
- 通常我们用的PaddleOCR,还是只支持单行识别,我们的处理方式,要么是在送入语音合成前做换行恢复的处理,要么就用连续音频播放解决该问题。个人建议后者的方式,前者在词法和版面分析上,将有大量操作,如果不是发音精度要求特别高的场景,开发性价比不高。
在本项目中,相关的部署代码已放在PaddleCode.zip文件中,读者下载并完成安装后,可以运行python can_new.py命令启动AI“朗读机”。
3.2 从PaddleSpeech调用语音合成模型
本项目提供另一种使用PaddleSpeech输出合成语音的方式,关键代码如下:
from paddlespeech.cli import TTSExecutor # 传入TTSExecutor() run_paddle_ocr(source=0, flip=False, use_popup=True, tts=TTSExecutor())
通过在run_paddle_ocr()函数中,调用Python API的方式,合成语音文件。
wav_file = tts_executor( text=txts[i], output='wavs/' + str(i) + '.wav', am='fastspeech2_csmsc', am_config=None, am_ckpt=None, am_stat=None, spk_id=0, phones_dict=None, tones_dict=None, speaker_dict=None, voc='pwgan_csmsc', voc_config=None, voc_ckpt=None, voc_stat=None, lang='zh', device=paddle.get_device())
这种做法的好处在于,可以选择更多的预训练模型。我们可以查看TTSExecutor()的源代码:
class TTSExecutor(BaseExecutor): def __init__(self): super().__init__() self.parser = argparse.ArgumentParser( prog='paddlespeech.tts', add_help=True) self.parser.add_argument( '--input', type=str, default=None, help='Input text to generate.') # acoustic model self.parser.add_argument( '--am', type=str, default='fastspeech2_csmsc', choices=[ 'speedyspeech_csmsc', 'fastspeech2_csmsc', 'fastspeech2_ljspeech', 'fastspeech2_aishell3', 'fastspeech2_vctk', 'tacotron2_csmsc', 'tacotron2_ljspeech', ], help='Choose acoustic model type of tts task.') self.parser.add_argument( '--am_config', type=str, default=None, help='Config of acoustic model. Use deault config when it is None.') self.parser.add_argument( '--am_ckpt', type=str, default=None, help='Checkpoint file of acoustic model.') self.parser.add_argument( "--am_stat", type=str, default=None, help="mean and standard deviation used to normalize spectrogram when training acoustic model." ) self.parser.add_argument( "--phones_dict", type=str, default=None, help="phone vocabulary file.") self.parser.add_argument( "--tones_dict", type=str, default=None, help="tone vocabulary file.") self.parser.add_argument( "--speaker_dict", type=str, default=None, help="speaker id map file.") self.parser.add_argument( '--spk_id', type=int, default=0, help='spk id for multi speaker acoustic model') # vocoder self.parser.add_argument( '--voc', type=str, default='pwgan_csmsc', choices=[ 'pwgan_csmsc', 'pwgan_ljspeech', 'pwgan_aishell3', 'pwgan_vctk', 'mb_melgan_csmsc', 'style_melgan_csmsc', 'hifigan_csmsc', 'hifigan_ljspeech', 'hifigan_aishell3', 'hifigan_vctk', 'wavernn_csmsc', ], help='Choose vocoder type of tts task.') self.parser.add_argument( '--voc_config', type=str, default=None, help='Config of voc. Use deault config when it is None.') self.parser.add_argument( '--voc_ckpt', type=str, default=None, help='Checkpoint file of voc.') self.parser.add_argument( "--voc_stat", type=str, default=None, help="mean and standard deviation used to normalize spectrogram when training voc." ) # other self.parser.add_argument( '--lang', type=str, default='zh', help='Choose model language. zh or en') self.parser.add_argument( '--device', type=str, default=paddle.get_device(), help='Choose device to execute model inference.') self.parser.add_argument( '--output', type=str, default='output.wav', help='output file name') self.parser.add_argument( '-d', '--job_dump_result', action='store_true', help='Save job result into file.') self.parser.add_argument( '-v', '--verbose', action='store_true', help='Increase logger verbosity of current task.')
PaddleSpeech 提供的可以被命令行和 python API 使用的预训练模型列表如下:
-
声学模型
模型 语言 speedyspeech_csmsc zh fastspeech2_csmsc zh fastspeech2_aishell3 zh fastspeech2_ljspeech en fastspeech2_vctk en -
声码器
模型 语言 pwgan_csmsc zh pwgan_aishell3 zh pwgan_ljspeech en pwgan_vctk en mb_melgan_csmsc zh
但是,从TTSExecutor()的源代码中我们也可以发现,其实它还支持我们配置基于自定义数据集,finetune的语音合成模型,这就为后续的模型性能优化提供了更多可能。




























