






本文围绕模型压缩中的聚类量化展开,先概述模型量化是通过简化参数比特位存储实现压缩。重点介绍Deep Compression的聚类量化思路,包括参数聚类等步骤,还给出用K-Means算法实现聚类量化的代码,搭建网络训练并展示量化前后权重分布及效果,体现聚类量化的作用。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

模型压缩之聚类量化
- 上午刚整完模型压缩之剪枝(MLP)(cv领域)就闲的无聊,那干脆再整个量化吧
0 量化概述
- 模型量化(quantization)通常是指这样一种模型压缩的方法:通过对模型的参数进行比特位存储上的简化而实现对模型在存储空间上的压缩。比如,将浮点格式存在的模型参数用int8进行简化,甚至进行[-1,1]这种最极端的简化等等
1 聚类量化 (量化方式的一种)
- 首先看一篇比较经典且常规的量化思路,来自于ICLR2016的best paper,Deep Compression。这篇论文将剪枝、量化、编码三者进行结合,而此处我们仅仅关注量化这一点。
- 如下图(聚4个类)所示将连续的权重离散化,实现量化,结合项目结果图看
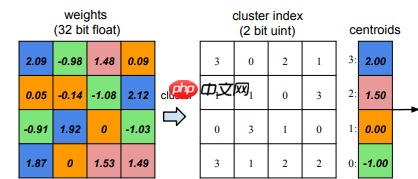
聚类量化实现步骤
- 1.进行参数聚类(这种聚类比较特殊,是在一维空间上进行的,能够发现这种分布的不均匀性,也是一种能力)。
- 2.建立位置和类别的映射表。
- 3.将每个类别的数替换为一个数。
- 4.训练模型。

2 项目结果
- 本项目实现如何对模型进行量化处理
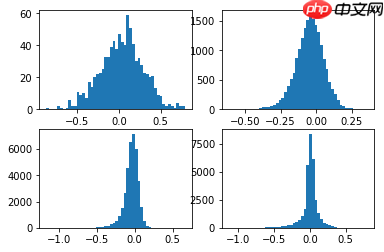
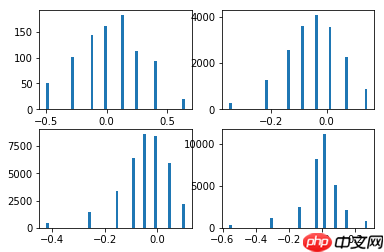
- 如下图,量化前后的结果展示,将将连续的权重离散化,通过K-Means聚类算法(聚8个类)离散化
3 前馈知识
- 需要了解K-Means聚类算法
- 此结为聚类量化的核心思想
In [1]
import paddlefrom sklearn.cluster import KMeans
In [33]
# 通过k_means实现对矩阵元素的分类,返回分类后的矩阵和聚类中心def k_means_cpu(weight, n_clusters, init='k-means++', max_iter=50):
# flatten the weight for computing k-means
org_shape = weight.shape
weight = paddle.to_tensor(weight)
weight = paddle.reshape(weight, [-1, 1]) # single feature
if n_clusters > weight.size:
n_clusters = weight.size
k_means = KMeans(n_clusters=n_clusters, init=init, n_init=1, max_iter=max_iter)
k_means.fit(weight)
centroids = k_means.cluster_centers_
labels = k_means.labels_
labels = labels.reshape(org_shape) return paddle.reshape(paddle.to_tensor(centroids), [-1, 1]), paddle.to_tensor(labels, "int32")# 将聚类中心的数值,替换掉分类后矩阵中的类别def reconstruct_weight_from_k_means_result(centroids, labels):
weight = paddle.zeros_like(labels, "float32") for i, c in enumerate(centroids.numpy().squeeze()):
weight[labels == i] = c.item() return weightIn [3]
# 随机初始个权重w = paddle.rand([4, 5])print(w)
W0127 19:32:47.801596 141 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.0, Runtime API Version: 10.1 W0127 19:32:47.808570 141 device_context.cc:465] device: 0, cuDNN Version: 7.6.
Tensor(shape=[4, 5], dtype=float32, place=CUDAPlace(0), stop_gradient=True,
[[0.76845109, 0.90174955, 0.35342011, 0.94143867, 0.18771467],
[0.17440563, 0.73438221, 0.36310545, 0.46279457, 0.55644131],
[0.97877306, 0.35445851, 0.06692132, 0.35885036, 0.06532700],
[0.39970225, 0.02711770, 0.99831027, 0.43467325, 0.11231221]])In [69]
# 返回聚类中心centroids,和类别矩阵labelscentroids, labels = k_means_cpu(w, 2)print(centroids)print(labels)
Tensor(shape=[2, 1], dtype=float64, place=CUDAPlace(0), stop_gradient=True,
[[0.25852331],
[0.83993517]])
Tensor(shape=[4, 5], dtype=int32, place=CUDAPlace(0), stop_gradient=True,
[[1, 1, 0, 1, 0],
[0, 1, 0, 0, 1],
[1, 0, 0, 0, 0],
[0, 0, 1, 0, 0]])In [5]
# reconstruct_weight_from_k_means_result返回聚类后的权重# 将此代码块结果跟上随机初始矩阵、分类矩阵进行比对,发现权重都被聚类中心值替换w_q = reconstruct_weight_from_k_means_result(centroids, labels)print(w_q)
Tensor(shape=[4, 5], dtype=float32, place=CUDAPlace(0), stop_gradient=True,
[[0.88718414, 0.88718414, 0.27980316, 0.88718414, 0.27980316],
[0.27980316, 0.88718414, 0.27980316, 0.27980316, 0.27980316],
[0.88718414, 0.27980316, 0.27980316, 0.27980316, 0.27980316],
[0.27980316, 0.27980316, 0.88718414, 0.27980316, 0.27980316]])/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/tensor.py:624: UserWarning: paddle.assign doesn't support float64 input now due to current platform protobuf data limitation, we convert it to float32 "paddle.assign doesn't support float64 input now due "
代码实现
In [6]
import paddleimport paddle.nn as nnimport paddle.nn.functional as Ffrom paddle.vision import datasets, transformsimport paddle.utilsimport numpy as npimport mathfrom copy import deepcopyfrom matplotlib import pyplot as pltfrom paddle.io import Datasetfrom paddle.io import DataLoaderfrom sklearn.cluster import KMeans
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/__init__.py:107: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from collections import MutableMapping /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/rcsetup.py:20: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from collections import Iterable, Mapping /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/colors.py:53: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from collections import Sized
In [40]
# 搭建基础线性层class QuantLinear(nn.Linear):
def __init__(self, in_features, out_features, bias=True):
super(QuantLinear, self).__init__(in_features, out_features, bias)
self.weight_labels = None
self.bias_labels = None
self.num_cent = None
self.quant_flag = False
self.quant_bias = False
def kmeans_quant(self, bias=False, quantize_bit=4):
self.num_cent = 2 ** quantize_bit
w = self.weight
centroids, self.weight_labels = k_means_cpu(w.cpu().numpy(), self.num_cent)
w_q = reconstruct_weight_from_k_means_result(centroids, self.weight_labels)
self.weight.set_value(w_q)
if bias:
b = self.bias
centroids, self.bias_labels = k_means_cpu(b.cpu().numpy(), self.num_cent)
b_q = reconstruct_weight_from_k_means_result(centroids, self.bias_labels)
self.bias.data = b_q.float()
self.quant_flag = True
self.quant_bias = bias
def kmeans_update(self):
if not self.quant_flag: return
new_weight_data = paddle.zeros_like(self.weight_labels, "float32") for i in range(self.num_cent):
mask_cl = (self.weight_labels == i).float()
new_weight_data += (self.weight.data * mask_cl).sum() / mask_cl.sum() * mask_cl
self.weight.data = new_weight_data
if self.quant_bias:
new_bias_data = paddle.zeros_like(self.bias_labels, "float32") for i in range(self.num_cent):
mask_cl = (self.bias_labels == i).float()
new_bias_data += (self.bias.data * mask_cl).sum() / mask_cl.sum() * mask_cl
self.bias.data = new_bias_dataIn [39]
# 搭建基础卷积层class QuantConv2d(nn.Conv2D):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1,
groups=1, padding_mode='zeros', weight_attr=None, bias_attr=None, data_format='NCHW'):
super(QuantConv2d, self).__init__(in_channels, out_channels,
kernel_size, stride, padding, dilation, groups, padding_mode, weight_attr, bias_attr, data_format)
self.weight_labels = None
self.bias_labels = None
self.num_cent = None
self.quant_flag = False
self.quant_bias = False
def kmeans_quant(self, bias=False, quantize_bit=4):
self.num_cent = 2 ** quantize_bit
w = self.weight
centroids, self.weight_labels = k_means_cpu(w.cpu().numpy(), self.num_cent)
w_q = reconstruct_weight_from_k_means_result(centroids, self.weight_labels)
self.weight.set_value(w_q)
if bias:
b = self.bias
centroids, self.bias_labels = k_means_cpu(b.cpu().numpy(), self.num_cent)
b_q = reconstruct_weight_from_k_means_result(centroids, self.bias_labels)
self.bias.data = b_q.float()
self.quant_flag = True
self.quant_bias = bias
def kmeans_update(self):
if not self.quant_flag: return
new_weight_data = paddle.zeros_like(self.weight_labels, "float32") for i in range(self.num_cent):
mask_cl = (self.weight_labels == i).float()
new_weight_data += (self.weight.data * mask_cl).sum() / mask_cl.sum() * mask_cl
self.weight.data = new_weight_data
if self.quant_bias:
new_bias_data = paddle.zeros_like(self.bias_labels) for i in range(self.num_cent):
mask_cl = (self.bias_labels == i).float()
new_bias_data += (self.bias.data * mask_cl).sum() / mask_cl.sum() * mask_cl
self.bias.data = new_bias_dataIn [10]
# 搭建网络class ConvNet(nn.Layer):
def __init__(self):
super(ConvNet, self).__init__()
self.conv1 = QuantConv2d(3, 32, kernel_size=3, padding=1, stride=1)
self.relu1 = nn.ReLU()
self.maxpool1 = nn.MaxPool2D(2)
self.conv2 = QuantConv2d(32, 64, kernel_size=3, padding=1, stride=1)
self.relu2 = nn.ReLU()
self.maxpool2 = nn.MaxPool2D(2)
self.conv3 = QuantConv2d(64, 64, kernel_size=3, padding=1, stride=1)
self.relu3 = nn.ReLU()
self.linear1 = QuantLinear(7*7*64, 10)
def forward(self, x):
out = self.maxpool1(self.relu1(self.conv1(x)))
out = self.maxpool2(self.relu2(self.conv2(out)))
out = self.relu3(self.conv3(out))
out = paddle.reshape(out, [out.shape[0], -1])
out = self.linear1(out) return out def kmeans_quant(self, bias=False, quantize_bit=4):
# Should be a less manual way to quantize
# Leave it for the future
self.conv1.kmeans_quant(bias, quantize_bit)
self.conv2.kmeans_quant(bias, quantize_bit)
self.conv3.kmeans_quant(bias, quantize_bit)
self.linear1.kmeans_quant(bias, quantize_bit)
def kmeans_update(self):
self.conv1.kmeans_update()
self.conv2.kmeans_update()
self.conv3.kmeans_update()
self.linear1.kmeans_update()In [11]
# 打印输出网络结构convNet_Net = ConvNet() paddle.summary(convNet_Net,(1, 3, 28, 28))
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
QuantConv2d-1 [[1, 3, 28, 28]] [1, 32, 28, 28] 896
ReLU-1 [[1, 32, 28, 28]] [1, 32, 28, 28] 0
MaxPool2D-1 [[1, 32, 28, 28]] [1, 32, 14, 14] 0
QuantConv2d-2 [[1, 32, 14, 14]] [1, 64, 14, 14] 18,496
ReLU-2 [[1, 64, 14, 14]] [1, 64, 14, 14] 0
MaxPool2D-2 [[1, 64, 14, 14]] [1, 64, 7, 7] 0
QuantConv2d-3 [[1, 64, 7, 7]] [1, 64, 7, 7] 36,928
ReLU-3 [[1, 64, 7, 7]] [1, 64, 7, 7] 0
QuantLinear-1 [[1, 3136]] [1, 10] 31,370
===========================================================================
Total params: 87,690
Trainable params: 87,690
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.01
Forward/backward pass size (MB): 0.69
Params size (MB): 0.33
Estimated Total Size (MB): 1.04
---------------------------------------------------------------------------{'total_params': 87690, 'trainable_params': 87690}In [12]
# 图像转tensor操作,也可以加一些数据增强的方式,例如旋转、模糊等等# 数据增强的方式要加在Compose([ ])中def get_transforms(mode='train'):
if mode == 'train':
data_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010])]) else:
data_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010])]) return data_transforms# 获取官方MNIST数据集def get_dataset(name='MNIST', mode='train'):
if name == 'MNIST':
dataset = datasets.MNIST(mode=mode, transform=get_transforms(mode)) return dataset# 定义数据加载到模型形式def get_dataloader(dataset, batch_size=128, mode='train'):
dataloader = DataLoader(dataset, batch_size=batch_size, num_workers=2, shuffle=(mode == 'train')) return dataloaderIn [13]
# 初始化函数,用于模型初始化class AverageMeter():
""" Meter for monitoring losses"""
def __init__(self):
self.avg = 0
self.sum = 0
self.cnt = 0
self.reset() def reset(self):
"""reset all values to zeros"""
self.avg = 0
self.sum = 0
self.cnt = 0
def update(self, val, n=1):
"""update avg by val and n, where val is the avg of n values"""
self.sum += val * n
self.cnt += n
self.avg = self.sum / self.cntIn [15]
# 网络训练def train_one_epoch(model, dataloader, criterion, optimizer, epoch, total_epoch, report_freq=20):
print(f'----- Training Epoch [{epoch}/{total_epoch}]:')
loss_meter = AverageMeter()
acc_meter = AverageMeter()
model.train() for batch_idx, data in enumerate(dataloader):
image = data[0]
label = data[1]
out = model(image)
loss = criterion(out, label)
loss.backward()
optimizer.step()
optimizer.clear_grad()
pred = nn.functional.softmax(out, axis=1)
acc1 = paddle.metric.accuracy(pred, label)
batch_size = image.shape[0]
loss_meter.update(loss.cpu().numpy()[0], batch_size)
acc_meter.update(acc1.cpu().numpy()[0], batch_size) if batch_idx > 0 and batch_idx % report_freq == 0: print(f'----- Batch[{batch_idx}/{len(dataloader)}], Loss: {loss_meter.avg:.5}, Acc@1: {acc_meter.avg:.4}') print(f'----- Epoch[{epoch}/{total_epoch}], Loss: {loss_meter.avg:.5}, Acc@1: {acc_meter.avg:.4}')In [25]
# 网络预测def validate(model, dataloader, criterion, report_freq=10):
print('----- Validation')
loss_meter = AverageMeter()
acc_meter = AverageMeter()
model.eval() for batch_idx, data in enumerate(dataloader):
image = data[0]
label = data[1]
out = model(image)
loss = criterion(out, label)
pred = paddle.nn.functional.softmax(out, axis=1)
acc1 = paddle.metric.accuracy(pred, label)
batch_size = image.shape[0]
loss_meter.update(loss.cpu().numpy()[0], batch_size)
acc_meter.update(acc1.cpu().numpy()[0], batch_size) if batch_idx > 0 and batch_idx % report_freq == 0: print(f'----- Batch [{batch_idx}/{len(dataloader)}], Loss: {loss_meter.avg:.5}, Acc@1: {acc_meter.avg:.4}') print(f'----- Validation Loss: {loss_meter.avg:.5}, Acc@1: {acc_meter.avg:.4}')In [64]
def main():
total_epoch = 1
batch_size = 256
model = ConvNet()
train_dataset = get_dataset(mode='train')
train_dataloader = get_dataloader(train_dataset, batch_size, mode='train')
val_dataset = get_dataset(mode='test')
val_dataloader = get_dataloader(val_dataset, batch_size, mode='test')
criterion = nn.CrossEntropyLoss()
scheduler = paddle.optimizer.lr.CosineAnnealingDecay(0.02, total_epoch)
optimizer = paddle.optimizer.Momentum(learning_rate=scheduler,
parameters=model.parameters(),
momentum=0.9,
weight_decay=5e-4)
eval_mode = False
if eval_mode:
state_dict = paddle.load('./ConvNet_ep200.pdparams')
model.set_state_dict(state_dict)
validate(model, val_dataloader, criterion) return
save_freq = 50
test_freq = 10
for epoch in range(1, total_epoch+1):
train_one_epoch(model, train_dataloader, criterion, optimizer, epoch, total_epoch)
scheduler.step() if epoch % test_freq == 0 or epoch == total_epoch:
validate(model, val_dataloader, criterion) if epoch % save_freq == 0 or epoch == total_epoch:
paddle.save(model.state_dict(), f'./ConvNet_ep{epoch}.pdparams')
paddle.save(optimizer.state_dict(), f'./ConvNet_ep{epoch}.pdopts')
quant_model = deepcopy(model) print('=='*10) print('2 bits quantization')
quant_model.kmeans_quant(bias=False, quantize_bit=4)
validate(quant_model, val_dataloader, criterion) return model, quant_modelIn [65]
# 返回值是量化前后网络模型# main()中quantize_bit控制聚类个数,聚类为quantize_bit*2个# 聚类数越多,量化后的模型越接近训练模型,但参数相应增加,所以根据实际情况取舍model, quant_model = main()
In [60]
from matplotlib import pyplot as plt
In [61]
# 定义模型权重展示函数def plot_weights(model):
modules = [module for module in model.sublayers()]
num_sub_plot = 0
for i, layer in enumerate(modules): if hasattr(layer, 'weight'):
plt.subplot(221+num_sub_plot)
w = layer.weight
w_one_dim = w.cpu().numpy().flatten()
plt.hist(w_one_dim, bins=50)
num_sub_plot += 1
plt.show()In [66]
# 量化前的权重plot_weights(model)
<Figure size 432x288 with 4 Axes>
In [67]
# 量化后的权重plot_weights(quant_model)
<Figure size 432x288 with 4 Axes>




























