






本文介绍用paddlex参与palm病理性近视预测常规赛的方法。先处理数据,解压、重命名并划分训练集与测试集,再配置paddlex环境、数据增强和数据集,用mobilenetv3_small_ssld模型训练,最后批量预测生成符合要求的csv结果文件,可获较好成绩。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

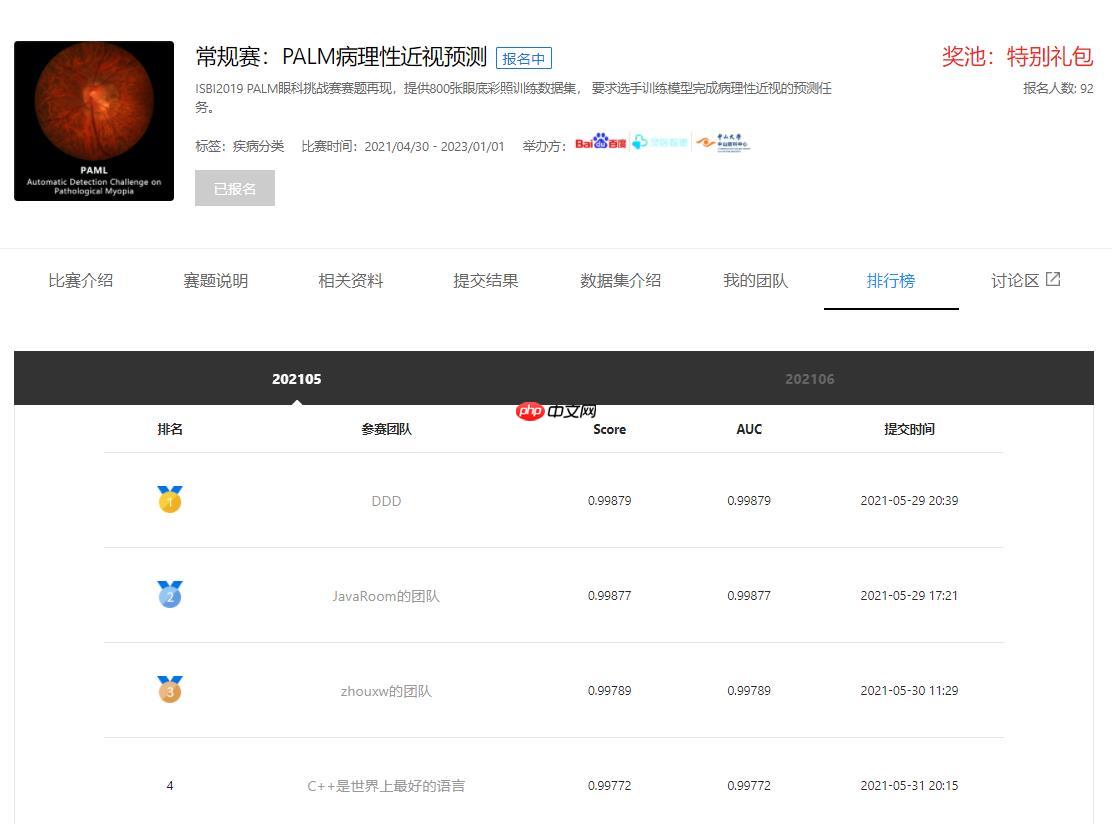
PaddleX超简单之--【常规赛:PALM病理性近视预测】
比赛地址: https://aistudio.baidu.com/aistudio/competition/detail/85
本文采用Paddlex傻瓜式操作,一键获得常规赛第二名,仅供大家参考!
一、赛题介绍
1. 赛题简介
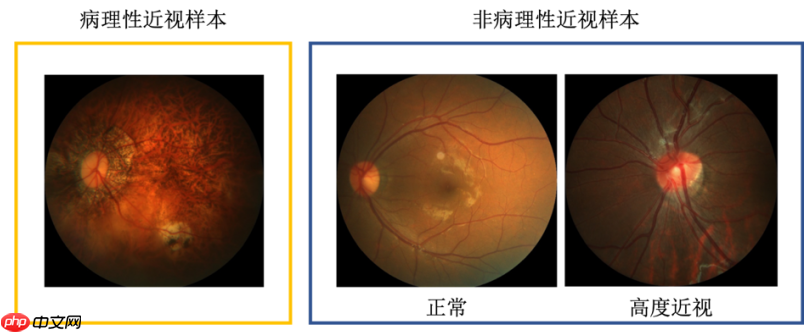
PALM病理性近视预测常规赛的重点是研究和发展与病理性近视诊断相关的算法。该常规赛的目标是评估和比较在一个常见的视网膜眼底图像数据集上检测病理性近视的自动算法。具体任务是将提供的图像分为病理性近视眼底彩照和非病理性近视眼底彩照,其中,非病理性近视眼底彩照包括正常眼底和高度近视眼底彩照。
2.数据简介
PALM病理性近视预测常规赛由中山大学中山眼科中心提供800张带病理性近视分类标注的眼底彩照供选手训练模型,另提供400张带标注数据供平台进行模型测试。
3. 数据说明
本次常规赛提供的病理性近视分类金标准是从临床报告中获取,不仅基于眼底彩照,还结合了OCT、视野检查等结果。

4. 训练数据集
文件名称:Train Train文件夹里有一个fundus_image文件夹和一个Classification.xlsx文件。fundus_image文件夹中数据均为眼底彩照,分辨率为1444×1444,或2124124×2056。命名形如N0001.jpg、H0001.jpg、P0001.jpg和V0001.jpg。Classification.xlsx文件中为各眼底图像是否属于病理性近视,属于为1,不属于为0。
5.测试数据集
文件名称:PALM-Testing400-Images 文件夹里包含400张眼底彩照,命名形如T0001.jpg。
6.提交内容及格式
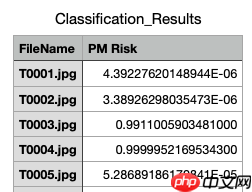
分类结果应在一个名为“Classification_Results.csv”的CSV文件中提供,第一列对应测试眼底图像的文件名(包括扩展名“.jpg”),对应title为FileName;第二列包含诊断为PM的患者图像的分类预测概率(值从0.0到1.0),对应title为PM Risk。示例如下:
二、数据处理
1.数据初步处理
- 解压缩
- 重命名文件夹
- 删除临时文件夹
!unzip -qao data/data85133/常规赛:PALM病理性近视预测.zip
!mv '常规赛:PALM病理性近视预测' dataset
!rm __MACOSX/ -rf
2.划分训练集和测试集
# 划分训练集和测试集import pandas as pdimport random
train_excel_file = 'dataset/Train/Classification.xlsx'pd_list=pd.read_excel(train_excel_file)
pd_list_lenght=len(pd_list)# 乱序pd_list=pd_list.sample(frac=1)
offset=int(pd_list_lenght*0.9)
trian_list=pd_list[:offset]
eval_list=pd_list[offset:]
trian_list.to_csv("train_list.txt", index=None, header=None, sep=' ')
eval_list.to_csv("eval_list.txt", index=None, header=None, sep=' ')
三、PaddleX配置
1.paddlex安装
! pip install paddlex -i https://mirror.baidu.com/pypi/simple
2.GPU设置、包引入
# 设置使用0号GPU卡(如无GPU,执行此代码后仍然会使用CPU训练模型)import matplotlib
matplotlib.use('Agg')
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'import paddlex as pdx
3.数据增强配置
from paddlex.cls import transforms
train_transforms = transforms.Compose([
transforms.RandomCrop(crop_size=1440),
transforms.RandomHorizontalFlip(),
transforms.Normalize()
])
eval_transforms = transforms.Compose([
transforms.ResizeByShort(short_size=1444),
transforms.CenterCrop(crop_size=1440),
transforms.Normalize()
])
4.数据集配置
train_dataset = pdx.datasets.ImageNet(
data_dir='dataset/Train/fundus_image',
file_list='train_list.txt',
label_list='labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.ImageNet(
data_dir='dataset/Train/fundus_image',
file_list='eval_list.txt',
label_list='labels.txt',
transforms=eval_transforms)
2021-05-29 23:30:44 [INFO] Starting to read file list from dataset... 2021-05-29 23:30:44 [INFO] 720 samples in file train_list.txt 2021-05-29 23:30:44 [INFO] Starting to read file list from dataset... 2021-05-29 23:30:44 [INFO] 80 samples in file eval_list.txt
四、开始训练
model = pdx.cls.MobileNetV3_small_ssld(num_classes=2)
model.train(num_epochs=64,
train_dataset=train_dataset,
train_batch_size=32,
eval_dataset=eval_dataset,
lr_decay_epochs=[4, 6, 8],
save_interval_epochs=1,
learning_rate=0.025,
save_dir='output/mobilenetv3_small_ssld', # resume_checkpoint='output/mobilenetv3_small_ssld/epoch_18',
use_vdl=True)
1.训练日志截图

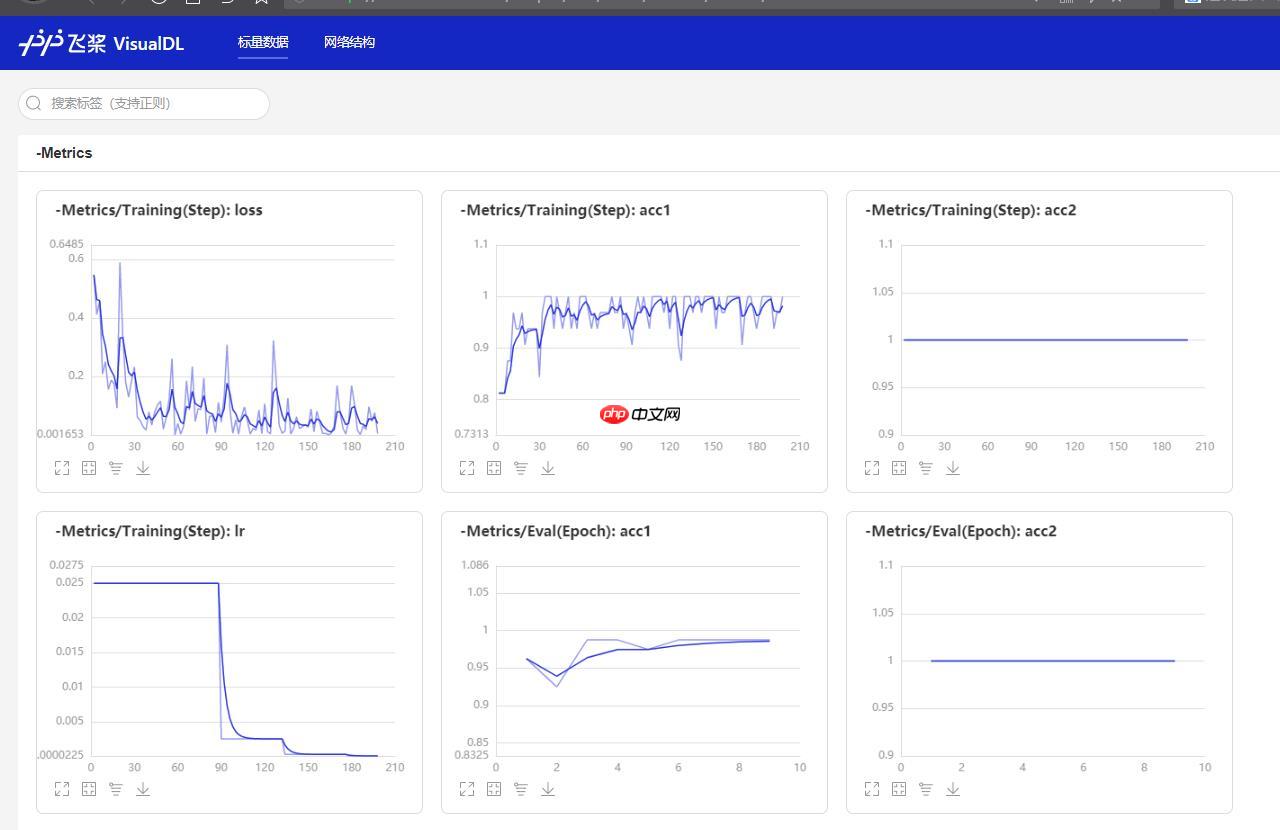
2.vdl视图
五、开始预测
1.环境配置
# 设置使用0号GPU卡(如无GPU,执行此代码后仍然会使用CPU训练模型)import matplotlib
matplotlib.use('Agg')
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'import paddlex as pdx
2.单张图片预测
# 单张预测测试import paddlex as pdx
model = pdx.load_model('output/mobilenetv3_small_ssld/epoch_9')
image_name = 'dataset/PALM-Testing400-Images/T0001.jpg'result = model.predict(image_name, topk=2)print("Predict Result:", result)
image_name = 'dataset/PALM-Testing400-Images/T0002.jpg'result = model.predict(image_name, topk=2)print("Predict Result:", result)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/math_op_patch.py:298: UserWarning: /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlex/cv/nets/mobilenet_v3.py:231 The behavior of expression A * B has been unified with elementwise_mul(X, Y, axis=-1) from Paddle 2.0. If your code works well in the older versions but crashes in this version, try to use elementwise_mul(X, Y, axis=0) instead of A * B. This transitional warning will be dropped in the future. op_type, op_type, EXPRESSION_MAP[method_name]))
2021-05-30 00:01:55 [INFO] Model[MobileNetV3_small_ssld] loaded.
Predict Result: [{'category_id': 1, 'category': '病理性近视眼底彩照', 'score': 0.9999714}, {'category_id': 0, 'category': '非病理性近视眼底彩照', 'score': 2.862251e-05}]
Predict Result: [{'category_id': 0, 'category': '非病理性近视眼底彩照', 'score': 0.9999293}, {'category_id': 1, 'category': '病理性近视眼底彩照', 'score': 7.070572e-05}]
3.预测数据集生成
# 预测数据集val_listval_list=[]for i in range(1,401,1):# for i in range(1,201,1):
filename='T'+ str(i).zfill(4)+'.jpg'
# print(filename)
val_list.append(filename+'\n')with open('val_list.txt','w') as f:
f.writelines(val_list)
val_list=[]with open('val_list.txt', 'r') as f: for line in f:
line='dataset/PALM-Testing400-Images/'+line
val_list.append(line.split('\n')[0]) # print(line.split('\n')[0])# print(val_list)
print(len(val_list))
400
4.批量预测
import paddlex as pdx
result_list=[]
model = pdx.load_model('output/mobilenetv3_small_ssld/best_model')for image_name in val_list:
result = model.predict(image_name, topk=2)
result_list.append(result) print("Predict Result:", result)
训练日志
Predict Result: [{'category_id': 1, 'category': '病理性近视眼底彩照', 'score': 0.9957604}, {'category_id': 0, 'category': '非病理性近视眼底彩照', 'score': 0.004239624}]Predict Result: [{'category_id': 1, 'category': '病理性近视眼底彩照', 'score': 0.9999951}, {'category_id': 0, 'category': '非病理性近视眼底彩照', 'score': 4.892705e-06}]Predict Result: [{'category_id': 0, 'category': '非病理性近视眼底彩照', 'score': 0.99935}, {'category_id': 1, 'category': '病理性近视眼底彩照', 'score': 0.00064998}]Predict Result: [{'category_id': 0, 'category': '非病理性近视眼底彩照', 'score': 0.99942756}, {'category_id': 1, 'category': '病理性近视眼底彩照', 'score': 0.00057246856}]Predict Result: [{'category_id': 0, 'category': '非病理性近视眼底彩照', 'score': 0.9437856}, {'category_id': 1, 'category': '病理性近视眼底彩照', 'score': 0.056214407}]Predict Result: [{'category_id': 0, 'category': '非病理性近视眼底彩照', 'score': 0.9995437}, {'category_id': 1, 'category': '病理性近视眼底彩照', 'score': 0.0004562317}]Predict Result: [{'category_id': 0, 'category': '非病理性近视眼底彩照', 'score': 0.9999137}, {'category_id': 1, 'category': '病理性近视眼底彩照', 'score': 8.6307664e-05}]Predict Result: [{'category_id': 0, 'category': '非病理性近视眼底彩照', 'score': 0.9968087}, {'category_id': 1, 'category': '病理性近视眼底彩照', 'score': 0.0031912646}]Predict Result: [{'category_id': 1, 'category': '病理性近视眼底彩照', 'score': 0.99964285}, {'category_id': 0, 'category': '非病理性近视眼底彩照', 'score': 0.00035708834}]Predict Result: [{'category_id': 1, 'category': '病理性近视眼底彩照', 'score': 0.9999894}, {'category_id': 0, 'category': '非病理性近视眼底彩照', 'score': 1.0667162e-05}]Predict Result: [{'category_id': 0, 'category': '非病理性近视眼底彩照', 'score': 0.9979461}, {'category_id': 1, 'category': '病理性近视眼底彩照', 'score': 0.0020539667}]Predict Result: [{'category_id': 0, 'category': '非病理性近视眼底彩照', 'score': 0.9986249}, {'category_id': 1, 'category': '病理性近视眼底彩照', 'score': 0.0013751077}]Predict Result: [{'category_id': 0, 'category': '非病理性近视眼底彩照', 'score': 0.99954623}, {'category_id': 1, 'category': '病理性近视眼底彩照', 'score': 0.00045376387}]Predict Result: [{'category_id': 1, 'category': '病理性近视眼底彩照', 'score': 0.99998736}, {'category_id': 0, 'category': '非病理性近视眼底彩照', 'score': 1.25998295e-05}]Predict Result: [{'category_id': 1, 'category': '病理性近视眼底彩照', 'score': 0.99992466}, {'category_id': 0, 'category': '非病理性近视眼底彩照', 'score': 7.5295e-05}]Predict Result: [{'category_id': 1, 'category': '病理性近视眼底彩照', 'score': 0.9999976}, {'category_id': 0, 'category': '非病理性近视眼底彩照', 'score': 2.329274e-06}]Predict Result: [{'category_id': 1, 'category': '病理性近视眼底彩照', 'score': 0.99314296}, {'category_id': 0, 'category': '非病理性近视眼底彩照', 'score': 0.0068570557}]Predict Result: [{'category_id': 1, 'category': '病理性近视眼底彩照', 'score': 0.99992156}, {'category_id': 0, 'category': '非病理性近视眼底彩照', 'score': 7.8419114e-05}]Predict Result: [{'category_id': 1, 'category': '病理性近视眼底彩照', 'score': 0.99983764}, {'category_id': 0, 'category': '非病理性近视眼底彩照', 'score': 0.00016234258}]Predict Result: [{'category_id': 1, 'category': '病理性近视眼底彩照', 'score': 0.9999995}, {'category_id': 0, 'category': '非病理性近视眼底彩照', 'score': 5.2132276e-07}]Predict Result: [{'category_id': 0, 'category': '非病理性近视眼底彩照', 'score': 0.9907357}, {'category_id': 1, 'category': '病理性近视眼底彩照', 'score': 0.0092642745}]Predict Result: [{'category_id': 1, 'category': '病理性近视眼底彩照', 'score': 0.9999937}, {'category_id': 0, 'category': '非病理性近视眼底彩照', 'score': 6.3574516e-06}]
5.结果检查
item = result_list[0]print(item)print(item[0]['category_id'],item[0]['score'])print(item[1]['category_id'],item[1]['score'])
[{'category_id': 1, 'category': '病理性近视眼底彩照', 'score': 0.9999862}, {'category_id': 0, 'category': '非病理性近视眼底彩照', 'score': 1.3863657e-05}]
1 0.9999862
0 1.3863657e-05
六、结果提交
1.构造pandas dataframe
# 结果列pd_B=[]for item in result_list: # print(item)
if item[0]['category_id']==1:
pd_B.append(item[0]['score']) else:
pd_B.append(item[1]['score'])
# 文件名列pd_A=[]with open('val_list.txt', 'r') as f: for line in f:
pd_A.append(line.split('\n')[0]) # print(line.split('\n')[0])
# 构造pandas的DataFrameimport pandas as pd
df= pd.DataFrame({'FileName': pd_A, 'PM Risk':pd_B})
2.保存数据到csv文件
# 保存为提交文件df.to_csv("Classification_Results.csv", index=None)
3.打压缩包下载提交
!zip -q Classification_Results.zip Classification_Results.csv




























