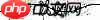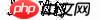概述简介坑!安装 tesseract-ocr使用 pytesseract 识别验证码高级玩法 - 除线简介
首先呢,简单的验证码是这样的:

不是这样的:

这里使用了 pytesseract 来进行验证码识别,它是基于 Google 的 Tesseract-OCR ,所以在使用之前需要先安装 Tesseract-OCR。使用 PIL 来进行图像处理。pytesseract 默认支持 tiff、bmp 图片格式,使用 PIL 库之后,能够支持 jpeg、gif、png 等其他图片格式;
坑!
PIL(Python Imaging Library) 库只支持 32 位的系统,如果要在 64 位系统中使用,请安装 pillow。嗯,这个真是坑死我了,为了安装这个倒腾了很久。希望能帮到你。
32 位系统
代码语言:javascript代码运行次数:0运行复制
pip install PIL
64 位系统
代码语言:javascript代码运行次数:0运行复制
pip install pillow
安装 Tesseract-OCR
在使用 pytesseract 之前,必须安装 tesseract-ocr ,因为 pytesserat 依赖于 tesseract-ocr ,否则无法使用
Mac代码语言:javascript代码运行次数:0运行复制
brew install tesseract
centos7代码语言:javascript代码运行次数:0运行复制
yum-config-manager --add-repo https://download.opensuse.org/repositories/home:/Alexander_Pozdnyakov/CentOS_7/yum updateyum install tesseract yum install tesseract-langpack-deu
download-address(https://github.com/tesseract-ocr/tesseract/wiki/4.0-with-LSTM#400-alpha-for-windows)
使用 pytesseract 识别验证码

首先将图像灰度化
代码语言:javascript代码运行次数:0运行复制
#使用路径导入图片 im = Image.open(imgimgName) #使用 byte 流导入图片 # im = Image.open(io.BytesIO(b)) # 转化到灰度图 imgry = im.convert('L') # 保存图像 imgry.save('gray-' + imgName)灰度化的图像是这个样子的:

然后将图像二值化
代码语言:javascript代码运行次数:0运行复制
# 二值化,采用阈值分割法,threshold为分割点 threshold = 140 table = [] for j in range(256): if j <p>二值化的图像是这个样子的:</p><figure class="">@@##@@</figure><p>最后进行识别</p>代码语言:javascript<i class="icon-code"></i>代码运行次数:<!-- -->0<svg xmlns="http://www.w3.org/2000/svg" width="16" height="16" viewbox="0 0 16 16" fill="none"><path d="M6.66666 10.9999L10.6667 7.99992L6.66666 4.99992V10.9999ZM7.99999 1.33325C4.31999 1.33325 1.33333 4.31992 1.33333 7.99992C1.33333 11.6799 4.31999 14.6666 7.99999 14.6666C11.68 14.6666 14.6667 11.6799 14.6667 7.99992C14.6667 4.31992 11.68 1.33325 7.99999 1.33325ZM7.99999 13.3333C5.05999 13.3333 2.66666 10.9399 2.66666 7.99992C2.66666 5.05992 5.05999 2.66659 7.99999 2.66659C10.94 2.66659 13.3333 5.05992 13.3333 7.99992C13.3333 10.9399 10.94 13.3333 7.99999 13.3333Z" fill="currentcolor"></path></svg>运行<svg width="16" height="16" viewbox="0 0 16 16" fill="none" xmlns="http://www.w3.org/2000/svg"><path fill-rule="evenodd" clip-rule="evenodd" d="M4.5 15.5V3.5H14.5V15.5H4.5ZM12.5 5.5H6.5V13.5H12.5V5.5ZM9.5 2.5H3.5V12.5H1.5V0.5H11.5V2.5H9.5Z" fill="currentcolor"></path></svg>复制<pre class="brush:php;toolbar:false;"> # 识别 text = pytesseract.image_to_string(out) print("识别结果:"+text)识别结果是这样的:

上面的知识简单的处理,在日常网络冲浪中,我们还会遇到这样的验证码:

这个给我们的识别增加了难度,我们要做的就是将这条线去掉。详细代码如下:
代码语言:javascript代码运行次数:0运行复制def removeLine(imgName): (img, pixdata) = open_img(imgName) for x in range(img.size[0]): # x坐标 for y in range(img.size[1]): # y坐标 if pixdata[x, y][0] 0: if pixdata[x, y - 1][0] > 120 or pixdata[x, y - 1][1] > 136 or pixdata[x, y - 1][2] > 120: pixdata[x, y] = (255, 255, 255) # ? # 二值化处理 for y in range(img.size[1]): # 二值化处理,这个阈值为R=95,G=95,B=95 for x in range(img.size[0]): if pixdata[x, y][0] <p>那么我们的运行结果是这样的:</p><figure class="">@@##@@</figure>总结<p>经过这么一些折腾,我们总算是看到了我们想要的结果,但是我很遗憾地告诉你,pytesseract 还是无法识别处理过的图片,他的识别结果是这样的:</p><figure class="">@@##@@</figure><p>结果有点令人痛心,不过我们也算是为我们的目标踏进了一小步。你以为这篇文章就这样完了吗?嗯,是的,这篇文章就这样完了。不过好在 pytesseract 提供了自定义训练功能,来提高识别能力(也可以自建神经网络进行识别),这个暂且放到下一篇文章来写吧,因为今天是七夕耶。</p><p>参考文档:Verification-code-crack</p><p>后台【验证码源码】获取源码</p>