







在本文中,我将介绍并展示四种不同的pytorch训练技巧,这些技巧是我个人发现的,用于优化我的深度学习模型的训练过程。
混合精度通常在常规的训练循环中,PyTorch使用32位精度来存储所有浮点数变量。对于那些在严格的资源限制下训练模型的人来说,这可能会导致模型占用过多的内存,从而迫使他们使用更小的模型和较小的批处理大小,导致训练速度变慢。因此,使用16位精度存储模型中的所有变量/数字可以改善并解决这些问题,例如显著减少模型的内存消耗,加速训练循环,同时仍能保持模型的性能和精度。
在PyTorch中,将所有计算转换为16位精度非常简单,只需几行代码即可实现。这里是实现方式:
scaler = torch.cuda.amp.GradScaler()
上述方法创建了一个梯度缩放标量,以最大程度避免在使用fp16进行计算时的梯度下溢。
在使用损失和优化器进行反向传播时,需要使用
scaler.scale(loss)而不是
loss.backward()和
optimizer.step()。使用
scaler.step(optimizer)来更新优化器。这允许标量转换所有的梯度,并在16位精度下进行所有计算,最后使用
scaler.update()来更新缩放标量,以适应训练过程中的梯度。
当以16位精度进行所有操作时,可能会遇到一些数值不稳定性,导致某些函数无法正常工作。只有特定操作在16位精度下能正常运行。具体详情请参考官方文档。
进度条在训练过程中显示每个阶段的进度百分比非常有用。为了实现进度条,我们将使用
tqdm库。以下是如何下载并导入它的方法:
pip install tqdm from tqdm import tqdm
在你的训练和验证循环中,你必须这样做:
for index, batch in tqdm(enumerate(loader), total=len(loader), position=0, leave=True):
在训练和验证循环中添加
tqdm代码后,你将得到一个进度条,表示模型完成训练的百分比。进度条看起来会像这样:
在图中,691表示我的模型需要完成的批次数量,7:28表示模型在691个批次上的总时间,1.54 it/s表示模型在每个批次上花费的平均时间。
梯度累积如果您遇到CUDA内存不足的错误,这意味着您已经超出了您的计算资源。为了解决这个问题,您可以采取几种措施,包括将所有内容转换为16位精度、减少模型的批处理大小、更换更小的模型等。
但是,有时转换到16位精度并不能完全解决问题。最直接的解决方案是减少批处理大小,但假设您不想减少批处理大小,可以使用梯度累积来模拟所需的批处理大小。请注意,解决CUDA内存不足问题的另一个方法是简单地使用多个GPU,但这是一个许多人无法使用的选项。
假设您的机器/模型只能支持16的批处理大小,增加它会导致CUDA内存不足错误,并且您希望批处理大小为32。梯度累积的工作原理是:以16个批次的规模运行模型两次,将计算出的每个批次的梯度累加起来,最后在这两次前向传播和梯度累积之后执行一个优化步骤。

用最优化方法解决最优化问题的技术称为最优化技术,它包含两个方面的内容: 1) 建立数学模型 即用数学语言来描述最优化问题。模型中的数学关系式反映了最优化问题所要达到的目标和各种约束条件。 2) 数学求解 数学模型建好以后,选择合理的最优化方法进行求解。 利用Matlab的优化工具箱,可以求解线性规划、非线性规划和多目标规划问题。具体而言,包括线性、非线性最小化,最大最小化,二次规划,半无限问题,线性、非线性方程(组)的求解,线性、非线性的最小二乘问题。另外,该工具箱还提供了线性、非线性最小化,方程求解,
要理解梯度累积,重要的是要理解在训练神经网络时所执行的具体功能。假设您有以下训练循环:
model = model.train()
for index, batch in enumerate(train_loader):
input = batch[0].to(device)
correct_answer = batch[1].to(device)
optimizer.zero_grad()
output = model(input).to(device)
loss = criterion(output, correct_answer).to(device)
loss.backward()
optimizer.step()关键是要记住,
loss.backward()为模型创建并存储梯度,而
optimizer.step()实际上更新权重。如果在调用优化器之前两次调用
loss.backward(),就会对梯度进行累加。以下是如何在PyTorch中实现梯度累积:
model = model.train()
optimizer.zero_grad()
for index, batch in enumerate(train_loader):
input = batch[0].to(device)
correct_answer = batch[1].to(device)
output = model(input).to(device)
loss = criterion(output, correct_answer).to(device)
loss.backward()
if (index+1) % 2 == 0:
optimizer.step()
optimizer.zero_grad()在上面的例子中,我们的机器只能支持16批大小的批量,我们想要32批大小的批量,我们本质上计算2批的梯度,然后更新实际权重。这导致有效批大小为32。
译者注:梯度累积只是一个折中方案,经过我们的测试,如果对梯度进行累加,那么最后一次
loss.backward()的梯度会比前几次反向传播的权重高,具体原因我们也不清楚。尽管有这样的问题,使用这种方式进行训练还是有效果的。
16位精度的梯度累积非常类似。
model = model.train()
optimizer.zero_grad()
for index, batch in enumerate(train_loader):
input = batch[0].to(device)
correct_answer = batch[1].to(device)
with torch.cuda.amp.autocast():
output = model(input).to(device)
loss = criterion(output, correct_answer).to(device)
scaler.scale(loss).backward()
if (index+1) % 2 == 0:
scaler.step(optimizer)
scaler.update()
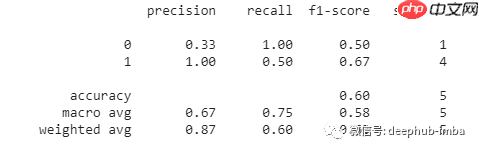
optimizer.zero_grad()结果评估在大多数机器学习项目中,人们倾向于手动计算用于评估的指标。尽管计算准确率、精度、召回率和F1等指标并不困难,但在某些情况下,您可能希望拥有这些指标的某些变体,如加权精度、召回率和F1。计算这些可能需要更多的工作,如果您的实现可能不正确、高效、快速且无错误地计算所有这些指标,可以使用sklearn的
classification_report库。这是一个专门为计算这些指标而设计的库。
from sklearn.metrics import classification_report y_pred = [0, 1, 0, 0, 1] y_correct = [1, 1, 0, 1, 1] print(classification_report(y_correct, y_pred))
上述代码用于二进制分类。您可以为更多的目的配置这个函数。第一个列表表示模型的预测,第二个列表表示正确数值。上面的代码将输出:
结论在这篇文章中,我讨论了四种在PyTorch中优化深度神经网络训练的方法。16位精度可以减少内存消耗,梯度累积可以通过模拟使用更大的批大小,
tqdm进度条和sklearn的
classification_report两个方便的库,可以轻松地跟踪模型的训练和评估模型的性能。就我个人而言,我总是使用上述所有的训练技巧来训练我的神经网络,并且在必要的时候我使用梯度累积。
最后,如果您使用的是PyTorch或者是PyTorch的初学者,可以使用这个库:https://www.php.cn/link/443a4c031f05c42f729a1ff2ac219b5a。
作者:Saketh Kotamraju
原文链接:https://www.php.cn/link/d386188d8d67a3b14820069536bcaf38
deephub翻译组




























