






最近老婆大人的公司给老婆大人安排了一个根据关键词查询google网站排名的差事。老婆大人的公司是做seo的,查询的关键词及网站特别的多,看着老婆大人这么辛苦的重复着查询工作,心疼啊。所以花点时间用python写了一个根据关键词搜索网站排名的py脚本。
在写这个脚本之前,我也曾在网站搜索过关于在google查排名的脚本。很多是利用google的api。但是我测试了一下,不准。所以,自己写一个吧。
脚本内容如下:(关键词我在网站随便找了几个。以做测试使用)
#vim keyword.py
import urllib,urllib2,cookielib,re,sys,os,time,random
cj = cookielib.CookieJar()
vibramkey=['cheap+five+fingers','vibram+five+fingers']
beatskey=['beats+by+dre','beats+by+dre+cheap']
vibramweb=['vibramforshoes.com','vibramfivetoeshoes.net','vibramfivefingersshoesx.com ']
beatsweb=['beatsbydre.com','justlovebeats.com']
allweb=['vibramweb','beatsweb']
def serchkey(key,start):
url="http://www.google.com/search?hl=en&q=%s&revid=33815775&sa=X&ei=X6CbT4GrIoOeiQfth43GAw&ved=0CIgBENUCKAY&start=%s" %(key,start)
try:
opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
opener.addheaders = [('User-agent', 'Opera/9.23')]
urllib2.install_opener(opener)
req=urllib2.Request(url)
response =urllib2.urlopen(req)
content = response.read()
f=open('google','w')
f.write(content)
tiqu=os.popen("grep -ioP '(?<=<cite>).*?(?=</cite>)' google|sed -r 's/(<*\/*cite>|<\/*b>)//g'").readlines()
except:
changeip()
else:
for yuming in pinpai:
a=1
for shouyuming in tiqu:
real=shouyuming.find(yuming)
if real>0:
if start==0:
page=1
elif start==10:
page=2
elif start==20:
page=3
elif start==30:
page=4
else:
page=5
lastkey=key.replace("+"," ")
xinxi="%s\t\t %s\t\t page%s,%s<br>\n" %(yuming,lastkey,page,a)
xinxifile=open('index.html','a')
xinxifile.write(xinxi)
xinxifile.close()
a=a+1
def changeip():
ip=random.randint(0,2)
de="route del -host google.com"
add="route add -host google.com eth1:%s" %ip
os.system(de)
os.system(add)
print "changip to %s" %ip
pinpaiid=0
for x in vibramkey,beatskey:
if pinpaiid == 0:
pinpai=vibramweb
elif pinpaiid == 1:
pinpai=beatsweb
pinpaiid=pinpaiid+1
for key in x:
for start in 0,10,20,30,40:
serchkey(key,start)
changeip()
os.system("sh paiban.sh")
#vim paiban.sh
#! /bin/bash
sort index.html -o index.html
line=`wc -l index.html|awk '{print $1}'`
yuming2=`sed -n 1p index.html|awk '{print $1}'`
for i in `seq 2 $line`
do
yuming=`sed -n "$i"p index.html|awk '{print $1}'`
if [ $yuming == $yuming2 ];then
sed -i ""$i"s/"$yuming"/\t\t/g" index.html
else
yuming2=$yuming
fi
done
这段脚本分两部分,第一部分是python利用关键词搜索google的页面。老婆大人说只要每一个关键词的前5页就可以。所以只查询了前5页。
第二部分是将查询出来的结果进行排版。也就是最下面调用paiban.sh 所做的事情,让最终出来的结果为如下格式:
网站1 关键词1 第几页 第几名
关键词2 第几页 第几名
关键词3 第几页 第几名
网站2 关键词1 第几页 第几名
关键词2 第几页 第几名
关键词3 第几页 第几名
下面就来对程序进行讲解。
import urllib,urllib2,cookielib,re,sys,os,time,random #加载模块
cj = cookielib.CookieJar()
vibramkey=['cheap+five+fingers','vibram+five+fingers'] #定义要查询的关键词组1,里面的单引号里面就是要查询的关键词。
beatskey=['beats+by+dre','beats+by+dre+cheap'] #同上,定义关键词组2,这个是另一组关键词。
vibramweb=['vibramforshoes.com','vibramfivetoeshoes.net','vibramfivefingersshoesx.com ']
#定义关健词组1要查询的网站
beatsweb=[' beatsbydre.com',' justlovebeats.com'] #定义关健词组2要查询的网站
allweb=['vibramweb','beatsweb'] #这里定义了一个所有网站的组,下面好调用。
def serchkey(key,start): #这里定义一个函数,key为查询的关健词,start为页面,通过google查询页面可以看出来每个页面除ads外只有十条记录,start=0时显示为第一个页面第一至第十条记录,start=10时,显示第二页的第一至十条记录,以些类推。
url="http://www.google.com/search?hl=en&q=%s&revid=33815775&sa=X&ei=X6CbT4GrIoOeiQfth43GAw&ved=0CIgBENUCKAY&start=%s" %(key,start) #这个定义了查询的URL
try:
opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
opener.addheaders = [('User-agent', 'Opera/9.23')] #模拟浏览器访问
urllib2.install_opener(opener)
req=urllib2.Request(url) #用urllib2访问
response =urllib2.urlopen(req)
content = response.read()#这块是模拟浏览器进行访问url的页面并读取源代码
f=open('google','w')
f.write(content) #将读取出来的内容保存到google的一个页面里。
tiqu=os.popen("grep -ioP '(?<=<cite>).*?(?=</cite>)' google|sed -r 's/(<*\/*cite>|<\/*b>)//g'").readlines() #这里利用了系统命令了。利用正则的零宽断言提直接取出第一到第十位的网站域名。
except:
changeip() #这边是怕访问过多被google封了。所以这里有一个换ip的函数,下面有定义。上面如果try失败了,就执行换ip的动作。
else:
for yuming in pinpai: #循环读取要查找的网站
a=1
for shouyuming in tiqu: #循环读取查找出来的网站
real=shouyuming.find(yuming) #将查找出来的网站与需要查找的网站进行比对
if real>0:
if start==0:
page=1
elif start==10:
page=2
elif start==20:
page=3
elif start==30:
page=4
else:
page=5
#这里的查看域名在google搜索后的哪一页。
lastkey=key.replace("+"," ") #将定义的关键词中间的加号去掉。
print yuming,lastkey,page,a
xinxi="%s\t\t %s\t\t 第%s页,排名%s\n" %(yuming,lastkey,page,a)
xinxifile=open('index.html','a')
xinxifile.write(xinxi)
xinxifile.close() #将查找出来的信息写入到index.html文件里
aa=a+1
def changeip(): #这里是定义查询时换ip的函数。如果机器只有一个ip那就不用这段了。
ip=random.randint(0,10) #随机生成0-10的数
del="route del -host google.com" #删除路由命令
add="route add -host google.com eth1:%s" %ip #添加路由命令
os.system(del) #执行删除路由命令
os.system(add) #执行添加路由命令
print "changip to %s" %ip #打印更改路由信息
pinpaiid=0
for x in vibramkey,beatskey: #循环所有的关键词组
if pinpaiid == 0: # 对应关键词组与要查询的网站组
pinpai=vibramweb
elif pinpaiid == 1:
pinpai=beatsweb
pinpaiidpinpaiid=pinpaiid+1
for key in x: #循环关键词组里的关键词
for start in 0,10,20,30,40: #定义所要查找的google的页面
serchkey(key,start)
changeip() #更改ip函数。在每一组关键词查询完毕后更改ip.
以上命令执行后,我们看一下index.html文件内容。如下:
#cat index.html
vibramforshoes.com cheap five fingers page 1,rank 3
vibramfivetoeshoes.net cheap five fingers page 5,rank 5
vibramforshoes.com vibram five fingers page 1,rank 6
vibramfivetoeshoes.net vibram five fingers page 5,rank 10
beatsbydre.com beats by dre page 1,rank 1
justlovebeats.com beats by dre page 5,rank 7
beatsbydre.com beats by dre cheap page 2,rank 2
beatsbydre.com beats by dre cheap page 2,rank 3
beatsbydre.com beats by dre cheap page 5,rank 10
如图:
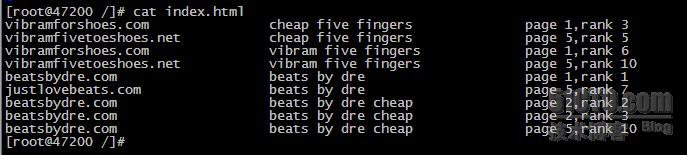
立即学习“Python免费学习笔记(深入)”;

这样看很乱,那么我们如何才能达到上面所讲 一个站后面对应多个关键词的格式呢,这里我们就要用到 paiban.sh 这个小脚本了。我们把paiban.sh放在py程序的最后,当执行py程序执行完毕后,执行paiban.sh 这个paiban.sh已经加在py程序里面了,所有不需要另外执行。我这里主要看一下区别。所有在py程序里注释了。
#sh paiban.sh
#cat index.html
beatsbydre.com beats by dre cheap page 2,rank 2
beats by dre cheap page 2,rank 3
beats by dre cheap page 5,rank 10
beats by dre page 1,rank 1
justlovebeats.com beats by dre page 5,rank 7
vibramfivetoeshoes.net cheap five fingers page 5,rank 5
vibram five fingers page 5,rank 10
vibramforshoes.com cheap five fingers page 1,rank 3
vibram five fingers page 1,rank 6
如图:

这样就能达到上面的效果了。排版也很清楚,哪个站对应哪个关键词。在第几页,第几位,一目了然。
我们也对paiban.sh这个脚本做一下解释。
#vim paiban.sh
#! /bin/bash
sort index.html -o index.html #先把index.html文件排下序,再写入index.html
line=`wc -l index.html|awk '{print $1}'` #统计行
yuming2=`sed -n 1p index.html|awk '{print $1}'` #取第一行的域名 给yuming2
for i in `seq 2 $line` #从第二行开始了取域名
do
yuming=`sed -n "$i"p index.html|awk '{print $1}'`
if [ $yuming == $yuming2 ];then
sed -i ""$i"s/"$yuming"/\t\t/g" index.html #如果下一行域名与yuming2域名相同,就把下一行域名替换成空
else
yuming2=$yuming #如果不相等,就把下一行的域名给yuming2变量
fi
done
好了。这个小脚本挺好用的,老婆大人天天在用。为她减轻了不少工作量。直夸我能干。。。,哈哈。。如果有看不明白的,欢迎加QQ讨论。QQ:410018348





























