







机器之心报道
编辑:Panda
用过 DeepSeek-R1 等推理模型的人,大概都遇到过这种情况:一个稍微棘手的问题,模型像陷入沉思一样长篇大论地推下去,耗时耗算力,结果却未必靠谱。现在,我们或许有了解决方案。
这两天,微软研究员 Dimitris Papailiopoulos 在 ? 上曝出一个新成果:Group Filtered Policy Optimization(GFPO)—— 一种颠覆性的强化学习算法。

GFPO 能同时权衡训练与测试阶段的计算开销,可在提升准确率的同时,将推理中因强化学习带来的多余 token 长度削减多达 80%!
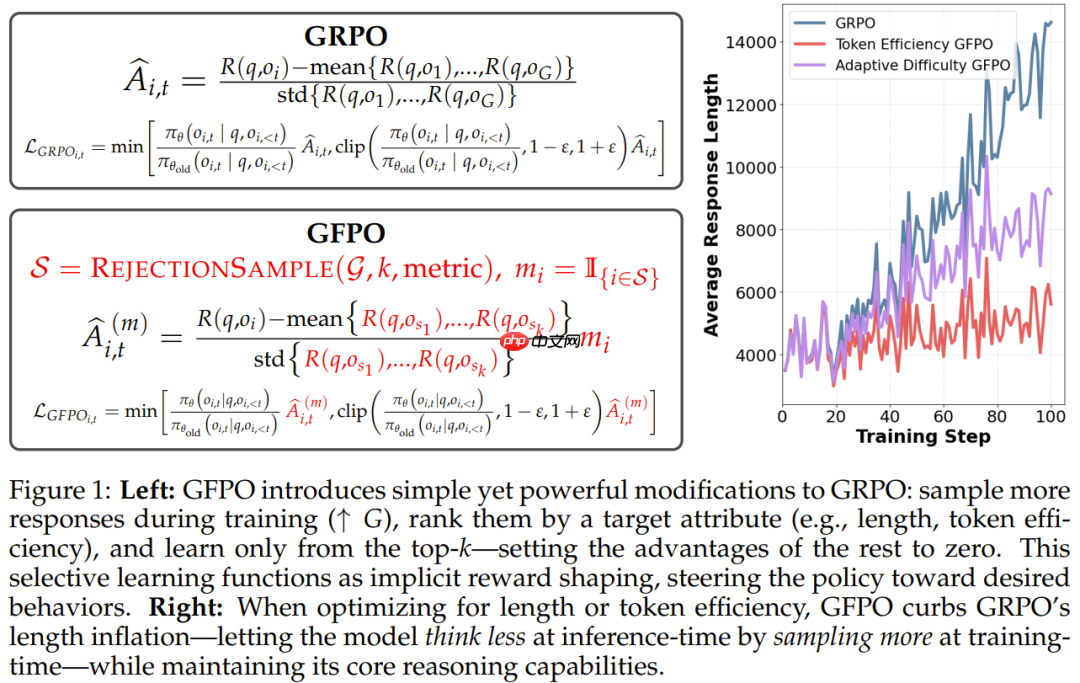
数据很惊人,但这究竟是如何做到的呢?
就在刚刚,GFPO 终于上线 arXiv,所有细节首次公开,高效强化学习的新玩法即将揭晓。

欲知 GFPO,先看 GRPO
在介绍 GFPO 之前,有必要先看看 DeepSeek 提出的组相对策略优化(GRPO)。
GRPO 基于近端策略优化(PPO)算法,但进行了简化,即不再需要使用价值模型来估计基线优势。具体操作是对每个问题采样多个响应,并使用它们的平均奖励作为基线,而其优化的目标仍然是与 PPO 类似的裁剪替代目标(clipped surrogate objective)。
写成公式的话,如果令 θ 表示模型参数,q 表示问题,o 表示从旧策略 π_θ_old 采样的响应,则 GRPO 目标可以写成:
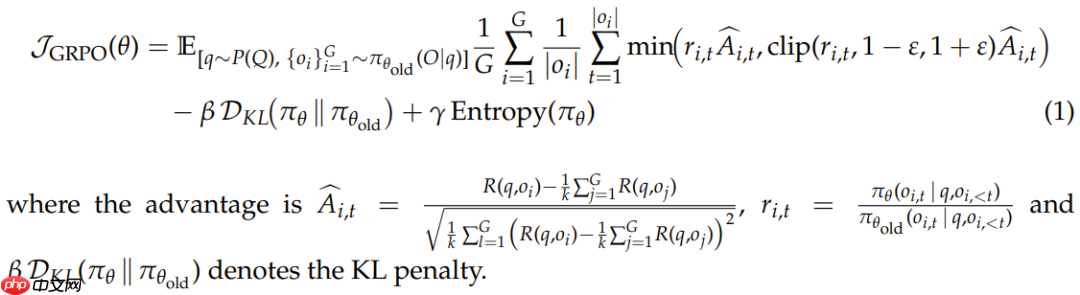
需要注意的是,尽管这里展示了标准的 GRPO 损失归一化公式,但包括 verl 和 TRL 在内的多个开源强化学习库都默认为 GRPO 使用了 DAPO token 级损失归一化 ,这也是该微软团队在实验中使用的方法。
GRPO 的一个关键限制在于它依赖于单一的标量奖励信号,这使得它难以联合优化多个期望得到的响应属性,例如简洁性和准确度。结果就是,GRPO 确实能提高准确度,但也会让响应长度大幅增加。
GFPO 正是为了解决这个问题而生的,它可以同时优化多个响应属性。
组过滤策略优化:GFPO
GFPO 是一种简单而有效的方法,可以针对想要的响应属性进行有针对性的策略优化。
GFPO 会为每个问题采样更大的候选响应组,从而扩大响应池以包含更多具有所需特性的候选响应,然后在计算策略梯度时显式地过滤这些特性。虽然将简洁性或信息量等所需属性直接编码到标量奖励中是看似自然的做法,但同时编码多个特性却可能很难,尤其是在必须保证正确性的情况下。
数据过滤则是一种隐式、灵活的奖励塑造形式 —— 类似于使用选择性采样来放大特定模型行为的迭代式自我改进方法 。在此显式过滤步骤分离出所需的响应后,将在所选组内使用标准奖励来计算相对优势。因此,GFPO 无需复杂的奖励工程,即可同时优化多个所需属性(例如长度和准确度)。
由于这里的目标是减少强化学习中响应长度的膨胀,因此该团队主要研究的是在保持与 GRPO 相当的准确度的用时,使用 GFPO 来优化缩短响应长度。
给定一个问题 q,从当前策略采样大量响应 G = {o_1, ..., o_G}。GFPO 并不会在所有响应上平等地训练,而是会根据用户指定的指标应用选择步骤,过滤出大小为 k 的最符合期望的响应子集,然后进行训练。之后,为每个响应计算一个指标得分并进行相应排序,从中选出前 k 个响应,形成留存子集 S ⊆ G(算法 1)。这里,该团队定义了一个二元掩码 m ∈ {0, 1}^G,其中 m_i = 1 表示被选中响应,m_i = 0 表示被拒绝响应。

下面是 GFPO 的形式化定义:

这里使用 S 中响应层面的奖励的平均值 (μ_S) 和标准差 (σ_S) 对所选子集 S 中响应的优势进行归一化。这样一来,便可以有意义地比较已表现出所需属性的响应,从而确保 GFPO 优先考虑过滤子集中奖励最高的响应。不在 S 中的响应的优势为零,从而可有效地被排除在策略更新之外。
因此,GFPO 的主要干预措施是在优势估计层面,使其可与任何 GRPO 变体兼容,例如 DAPO、Dr. GRPO 或带有 Dual-Clip PPO 损失的 GRPO。
虽然通过采样更多响应,GFPO 会导致更高的训练时间计算成本,但由于学习到的策略比 GRPO 能产生更短的响应,因此这部分成本可以被抵消。
尽管 GFPO 是通用的,可以适应各种评分指标,但微软在这里的实验中研究的是旨在减少响应长度膨胀的指标:
响应长度:使用短响应进行训练能直接鼓励实现简洁性。token 效率(奖励/长度):使用高 token 效率的响应进行训练可鼓励简洁性,但如果较长响应能「证明」其正当性,则仍可允许较长响应。其他指标(例如事实性、多样性或外部质量得分)也可以集成到 GFPO 中,以优化不同的目标属性。
自适应难度的 GFPO
该团队还提出了 GFPO 变体:自适应难度 GFPO,见算法 2,其目标是将更多的训练信号分配给更难的问题。


在训练的每个步骤中,通过计算为每个问题采样的响应的平均奖励来估计问题难度 —— 较低的平均奖励意味着难度更高。
为了自适应地调整留存响应的数量 (k),该团队使用了一个轻量级 t-digest 数据结构维护提示词难度的流式摘要。t-digest 可以有效地近似迄今为止所有提示词难度(奖励均值)的四分位数,从而能够将新问题分类到相对难度的桶(bucket)中。
基于此分类,该团队为每个问题分配一个留存响应数量目标 k:简单 4 个,中等 6 个,困难和非常困难的问题 8 个(从 16 个样本中选取)。这种动态课程可以对简单提示词进行更积极的过滤,并对困难提示词进行更多探索。难度桶的数量和每个桶的 k 是此方法的超参数。
自适应难度 GFPO 可高效利用训练计算,将梯度更新集中在最需要的地方。它能帮助模型减少简单示例(正确率已经很高)的冗长程度,同时通过保留更多推理链来保持更难提示词的准确度。
该团队表示:「据我们所知,这是首个能根据问题难度动态调整有效分组规模的算法。」
基于 GFPO 的实验发现
那么,GFPO 的表现如何呢?基于 14B 参数的 Phi-4-reasoning 模型,该团队开展了实验。
他们评估了三种 GFPO 变体:
Shortest k/G:留存 G 中的 k 个最短响应,同时改变 k 和分组规模 G,以研究它们对长度缩减的影响。token 效率:留存 G 中 k 个每 token 奖励效率最高的响应,使用 k = 8,G = 16(与基准 Shortest k/G 设置一致)。自适应难度:留存 G 中 k 个最短的响应,k 根据实时难度估算动态选择(4、6、8,8 表示简单→非常难),G = 16。更多实验细节请参阅原论文,这里我们重点看看该团队得到的一些发现。

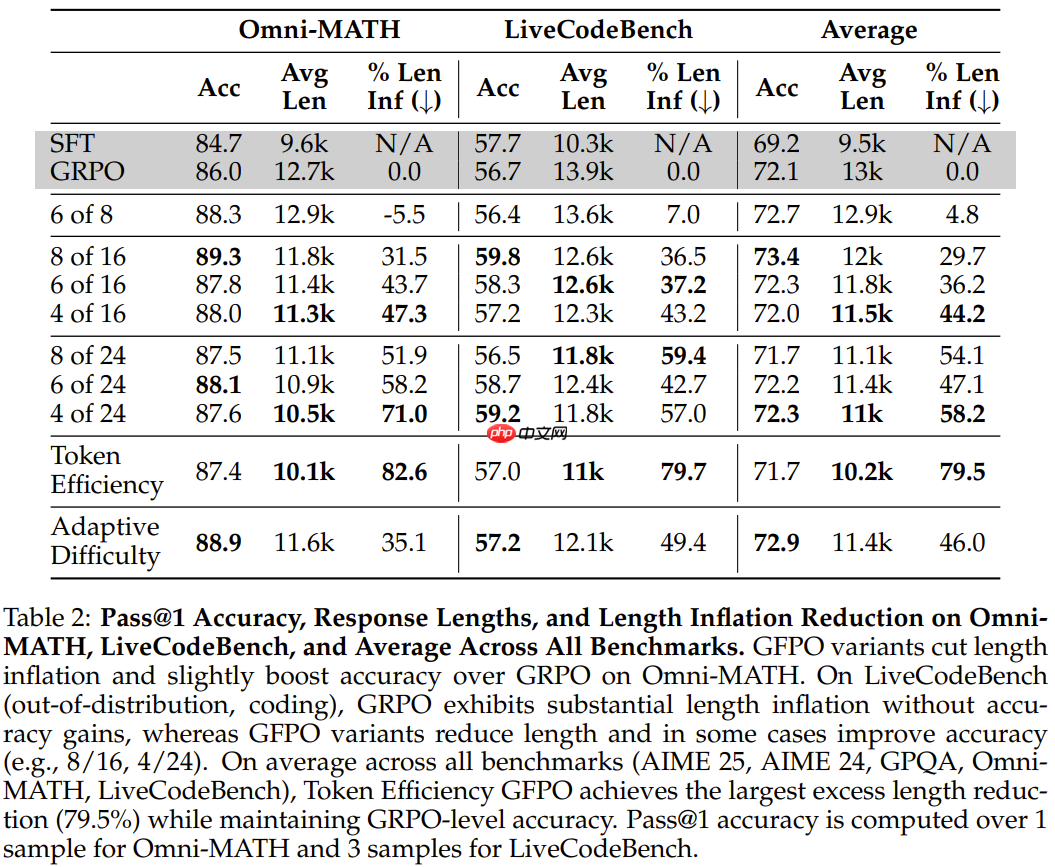
发现 1:「少思考」需要多采样:在不增加分组规模的情况下减少保留的响应(Shortest 6/8 GFPO)不会减少响应长度。
发现 2:留存响应的百分比 (k/G) 可控制长度压力:降低 k 或提高 G 会进一步缩短长度;该团队观察到保留 25-33% 的响应是最佳的,保留比例越小,增益越小。最短 4/24 是最佳长度优化的 GFPO 变体,可最大程度地减少过长响应。

发现 3:token 效率(奖励 / 长度)优化带来了最大幅度的缩减:在保持准确度的同时,额外长度减少了 70.9% (AIME 25)、84.6% (AIME 24)、79.7% (GPQA)、82.6% (OmniMATH) 和 79.7% (LiveCodeBench)。这些缩减在训练过程中会略微增加方差。
发现 4:自适应难度 GFPO 在同等计算量下优于 Shortest-k 算法:根据问题难度自适应地确定 k 值,在 4/5 基准测试中,与同等计算量下的 Shortest-k 算法相比,其长度缩减效果更佳。
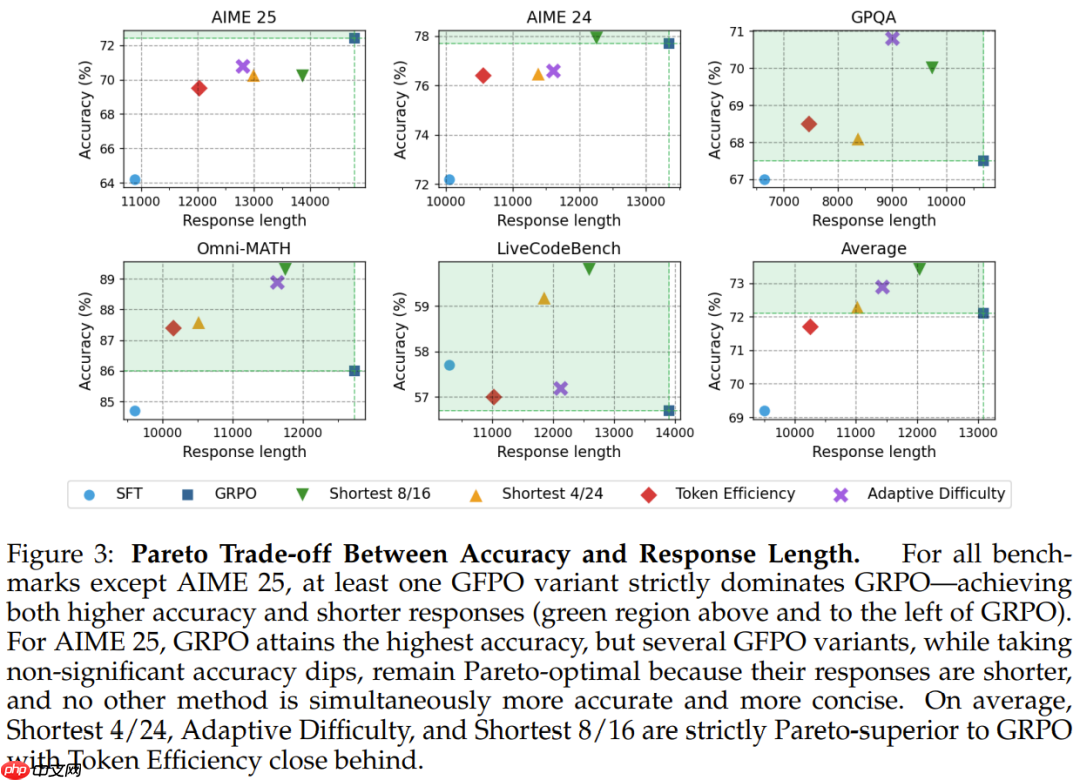
发现 5:GFPO 可缓解分布外(OOD)长度膨胀:GRPO 会增加分布外任务的响应长度,但准确度并未提高;而 GFPO 则在略微提高准确度的同时,抑制了这种膨胀。
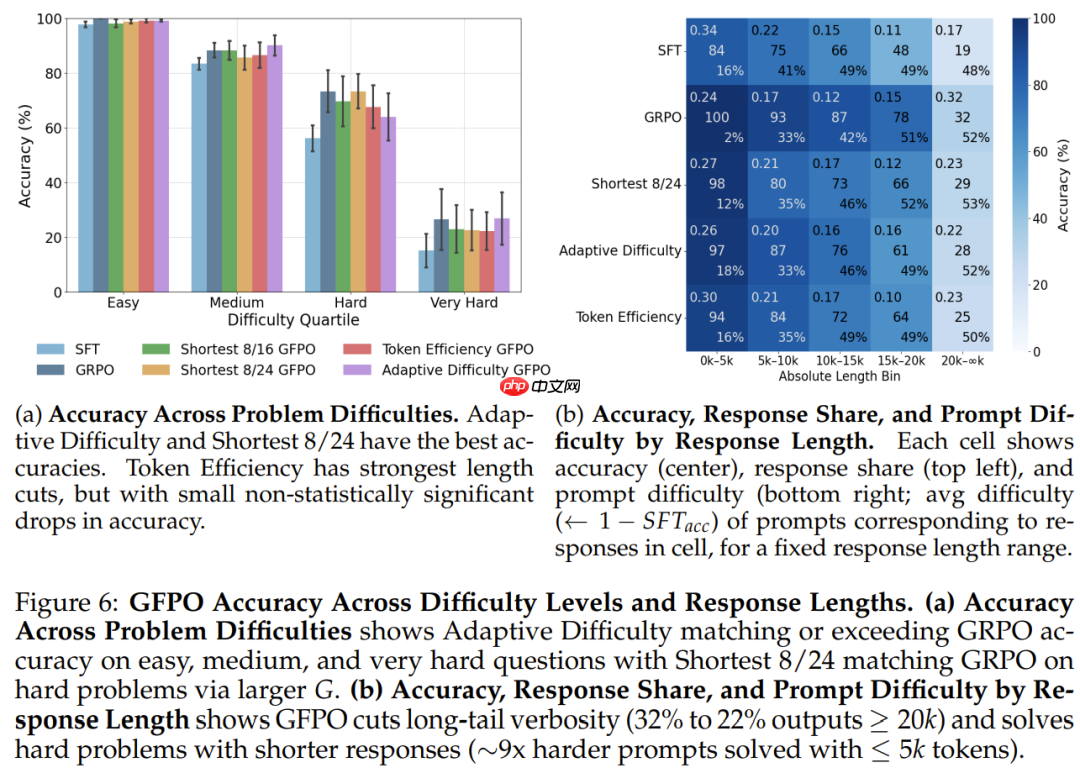
发现 6:
GFPO 在所有难度级别上都会缩短响应。token 效率 GFPO 在简单、中等和困难问题上实现了最大程度的缩减 —— 在简单问题上,其响应甚至比 SFT 模型更短,同时准确度与 GRPO 相当。Shortest 8/24 GFPO 由于其强大的过滤功能,在最难问题上实现了最大程度的缩减。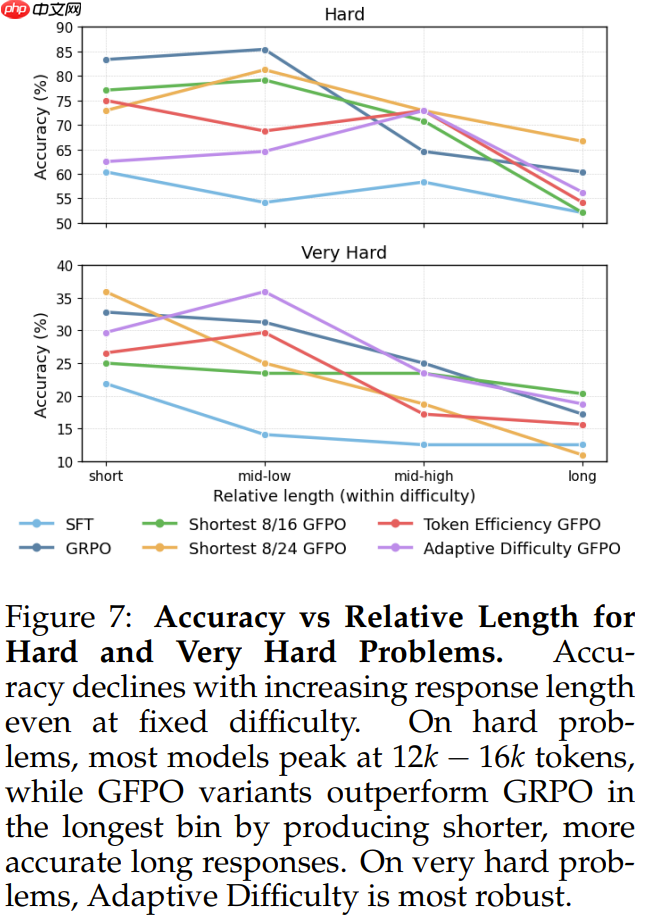
发现 7:
自适应难度 GFPO 在中等难度和极难问题上的准确度超越 GRPO,同时将过长问题缩短了 47%-60%。更大的分组规模提高了难题的准确度:自适应难度(k = 8,G = 16)在难题上略有下降,但 Shortest 8/24 算法可通过更多采样找到简洁的正确响应,从而与 GRPO 的准确度相当。发现 8:即使在固定难度下,较长的响应准确度也会降低:在较难的问题中,推理的最佳点出现在 12k-16k 个 token 左右。
发现 9:在最长的响应四分位数中,GFPO 的准确度优于 GRPO。
发现 10:GFPO 可减少极端冗长:将 ≥ 20k 个 token 的响应比例从 32% 降至 22%,同时能以较短的长度解决更难的问题(在 GFPO 中,用 ≤ 5k 个 token 回答的问题比 GRPO 的难度高 9 倍)。

发现 11:哪种 GFPO 变体效果最佳?
token 效率:长度缩减效果最强,准确度略有下降 难度自适应:在最难问题上,通过稳健的长度缩减获得了最佳准确度 Shortest 8/24:在管理准确度与长度的权衡方面非常有效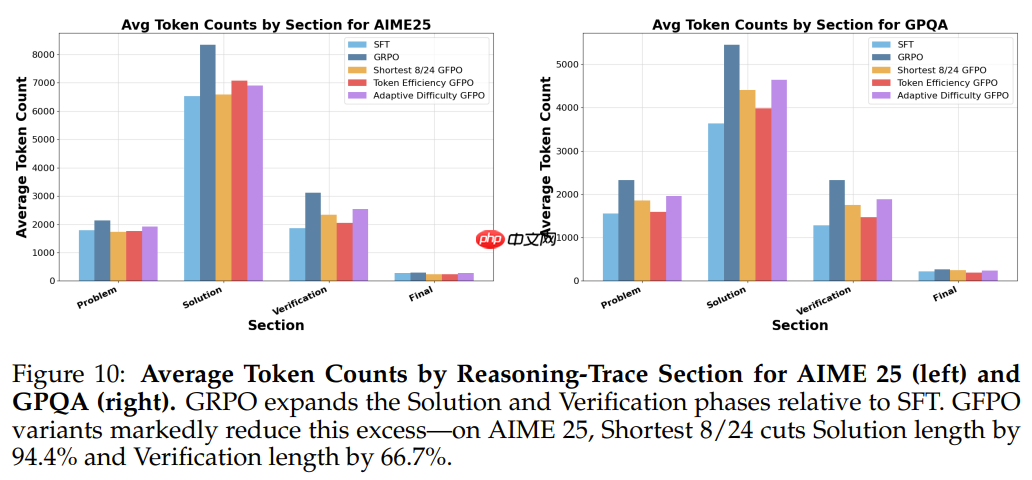
发现 12:GFPO 可大幅降低推理解答和验证阶段的冗长程度,在 AIME 25 上,解答中减少了 94.4% 的多余长度,验证步骤中减少了 66.7% 的多余长度。

参考链接
https://x.com/DimitrisPapail/status/1955652396572721184
https://x.com/DimitrisPapail/status/1955653211819270337
© THE END
转载请联系本公众号获得授权





























