







正则表达式处理文本有如疾风扫秋叶,绝大部分编程语言都内置支持正则表达式,它应用在诸如表单验证、文本提取、替换等场景。下文给大家带来了python正则表达式指南,需要的的朋友参考下吧
正则表达式处理文本有如疾风扫秋叶,绝大部分编程语言都内置支持正则表达式,它应用在诸如表单验证、文本提取、替换等场景。爬虫系统更是离不开正则表达式,用好正则表达式往往能收到事半功倍的效果。
介绍正则表达式前,先来看一个问题,下面这段文本来自豆瓣的某个网页链接,我对内容进行了缩减。问:如何提取文本中所有邮箱地址呢?
html = """34613453@qq.com,谢谢了
30604259@qq.com麻烦楼主
490010464@163.com
"""
谢谢
如果你还没接触过正则表达式,我想对此会是一筹莫展,不用正则,似乎想不到一种更好的方式来处理,不过,我们暂且放下这个问题,待学习完正则表达式之后再来考虑如何解决。
字符串的表现形式
立即学习“Python免费学习笔记(深入)”;
Python 字符串有几种表现形式,以u开头的字符串称为Unicode字符串,它不在本文讨论范围内,此外,你应该还看到过这两种写法:
>>> foo = "hello" >>> bar = r"hello"
前者是常规字符串,后者 r 开头的是原始字符串,两者有什么区别?因为在上面的例子中,它们都是由普通文本字符组成的串,在这里没什么区别,下面可以证明
>>> foo is bar True >>> foo == bar True
但是,如果字符串中包括有特殊字符,会是什么情况呢?再来看一个例子:
>>> foo = "\n"
>>> bar = r"\n"
>>> foo, len(foo)
('\n', 1)
>>> bar, len(bar)
('\\n', 2)
>>> foo == bar
False
>>>"\n" 是一个转义字符,它在 ASCII 中表示换行符。而 r"\n" 是一个原始字符串,原始字符串不对特殊字符进行转义,它就是你看到的字面意思,由 "\" 和 "n" 两个字符组成的字符串。
定义原始字符串可以用小写r或者大写R开头,比如 r"\b" 或者 R"\b" 都是允许的。在 Python 中,正则表达式一般用原始字符串的形式来定义,为什么呢?
举例来说,对于字符 "\b" 来说,它在 ASCII 中是有特殊意义的,表示退格键,而在正则表达式中,它是一个特殊的元字符,用于匹配一个单词的边界,为了能让正则编译器正确地表达它的意义就需要用原始字符串,当然也可以使用反斜杠 "\" 对常规定义的字符串进行转义
>>> foo = "\\b" >>> bar = r"\b" >>> foo == bar True
正则基本介绍
正则表达式由普通文本字符和特殊字符(元字符)两种字符组成。元字符在正则表达式中具有特殊意义,它让正则表达式具有更丰富的表达能力。例如,正则表达式 r"a.d"中 ,字符 'a' 和 'd' 是普通字符,'.' 是元字符,. 可以指代任意字符,它能匹配 'a1d'、'a2d'、'acd' ,它的匹配流程是:
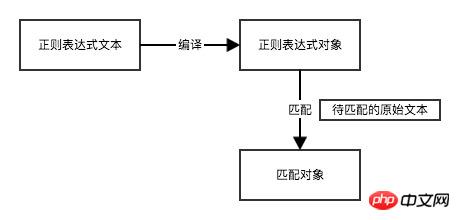
Python 内置模块 re 是专门用于处理正则表达式的模块。
>>> rex = r"a.d" # 正则表达式文本 >>> original_str = "and" # 原始文本 >>> pattern = re.compile(rex) # 正则表达式对象 >>> m = pattern.match(original_str) # 匹配对象 >>> m <_sre.SRE_Match object at 0x101c85b28> # 等价于 >>> re.match(r"a.d", "and") <_sre.SRE_Match object at 0x10a15dcc8>
如果原文本字符串与正则表达式匹配,那么就会返回一个 Match 对象,当不匹配时,match 方法返回的 None,通过判断m是否为None可进行表单验证。
接下来,我们需要学习更多元字符。
基本元字符
.:匹配除换行符以外的任意一个字符,例如:"a.c" 可以完全匹配 "abc",也可以匹配 "abcef" 中的 "abc"
\: 转义字符,使特殊字符具有本来的意义,例如: 1\.2 可以匹配 1.2
[...]:匹配方括号中的任意一个字符,例如:a[bcd]e 可以匹配 abe、ace、ade,它还支持范围操作,比如:a到z可表示为 "a-z",0到9可表示为 "0-9",注意,在 "[]" 中的特殊字符不再有特殊意义,就是它字面的意义,例如:[.*]就是匹配 . 或者 *
[^...],字符集取反,表示只要不是括号中出现的字符都可以匹配,例如:a[^bcd]e 可匹配 aee、afe等
>>> re.match(r"a.c", "abc").group() 'abc' >>> re.match(r"a.c", "abcef").group() 'abc' >>> re.match(r"1\.2", "1.2").group() '1.2' >>> re.match(r"a[0-9]b", "a2b").group() 'a2b' >>> re.match(r"a[0-9]b", "a5b11").group() 'a5b' >>> re.match(r"a[.*?]b", "a.b").group() 'a.b' >>> re.match(r"abc[^\w]", "abc!123").group() 'abc!
group 方法返回原字符串(abcef)中与正则表达式相匹配的那部分子字符串(abc),提前是要匹配成功 match 方法才会返回 Match 对象,进而才有group方法。
预设元字符

这本书给出了一份关于python这门优美语言的精要的参考。作者通过一个完整而清晰的入门指引将你带入python的乐园,随后在语法、类型和对象、运算符与表达式、控制流函数与函数编程、类及面向对象编程、模块和包、输入输出、执行环境等多方面给出了详尽的讲解。如果你想加入 python的世界,David M beazley的这本书可不要错过哦。 (封面是最新英文版的,中文版貌似只译到第二版)
\w 匹配任意一个单词字符,包括数字和下划线,它等价于 [A-Za-z0-9_],例如 a\wc 可以匹配 abc、acc
\W 匹配任意一个非单词字符,与 \w 操作相反,它等价于 [^A-Za-z0-9_],例如: a\Wc 可匹配 a!c
\s 匹配任意一个空白字符,空格、回车等都是空白字符,例如:a\sc 可以配 a\nc,这里的 \n表示回车
\S 匹配任意一个非空白字符
\d 匹配任意一个数字,它等价于[0-9],例如:a\dc 可匹配 a1c、a2c ...
\D 匹配任意一个非数字
边界匹配
边界匹配相关的符号专门用于修饰字符。
^ 匹配字符的开头,在字符串的前面,例如:^abc 表示匹配 a开头,后面紧随bc的字符串,它可以匹配 abc $ 匹配字符的结尾,在字符串的末尾位置,例如: hello$ >>> re.match(r"^abc","abc").group() 'abc' >>> re.match(r"^abc$","abc").group() 'abc'
重复匹配
前面的元字符都是针对单个字符来匹配的,如果希望匹配的字符重复出现,比如匹配身份证号码,长度18位,那么就需要用到重复匹配的元字符
* 重复匹配零次或者更多次
? 重复匹配零次或者一次
+ 重复匹配1次或者多次
{n} 重复匹配n次
{n,} 重复匹配至少n次
{n, m} 重复匹配n到m次
# 简单匹配身份证号码,前面17位是数字,最后一位可以是数字或者字母X
>>> re.match(r"\d{17}[\dX]", "42350119900101153X").group()
'42350119900101153X'
# 匹配5到12的QQ号码
>>> re.match(r"\d{5,12}$", "4235011990").group()
'4235011990'逻辑分支
匹配一个固定电话号码,不同地区规则不一样,有的地方区号是3位,电话是8位,有的地方区号是4位,电话为7位,区号与号码之间用 - 隔开,如果应对这样的需求呢?这时你需要用到逻辑分支条件字符 |,它把表达式分为左右两部分,先尝试匹配左边部分,如果匹配成功就不再匹配后面部分了,这是逻辑 "或" 的关系
# abc|cde 可以匹配abc 或者 cde,但优先匹配abc
>>> re.match(r"aa(abc|cde)","aaabccde").group()
'aaabc'
0\d{2}-\d{8}|0\d{3}-\d{7} 表达式以0开头,既可以匹配3位区号8位号码,也可以匹配4位区号7位号码
>>> re.match(r"0\d{2}-\d{8}|0\d{3}-\d{7}", "0755-4348767").group()
'0755-4348767'
>>> re.match(r"0\d{2}-\d{8}|0\d{3}-\d{7}", "010-34827637").group()
'010-34827637'
前面介绍的匹配规则都是针对单个字符而言的,如果想要重复匹配多个字符怎么办,答案是,用子表达式(也叫分组)来表示,分组用小括号"()"表示,例如 (abc){2} 表示匹配abc两次, 匹配一个IP地址时,可以使用 (\d{1,3}\.){3}\d{1,3},因为IP是由4组表达式03个点组成的,所有,前面3组数字和3个点可以作为一个分组重复3次,最后一部分是一个1到3个数字组成的字符串。如:192.168.0.1。
关于分组,group 方法可用于提取匹配的字符串分组,默认它会把整个表达式的匹配结果当做第0个分组,就是不带参数的 group() 或者是 group(0),第一组括号中的分组用group(1)获取,以此类推
>>> m = re.match(r"(\d+)(\w+)", "123abc") #分组0,匹配整个正则表达式 >>> m.group() '123abc' #等价 >>> m.group(0) '123abc' # 分组1,匹配第一对括号 >>> m.group(1) '123' # 分组2,匹配第二对括号 >>> m.group(2) 'abc' >>>
通过分组,我们可以从字符串中提取出想要的信息。另外,分组还可以通过指定名字的方式获取。
# 第一个分组的名字是number # 第二个分组的名字是char >>> m = re.match(r"(?P\d+)(?P \w+)", "123abc") >>> m.group("number") '123' # 等价 >>> m.group(1) '123'
表达式1
默认情况下,正则表达式重复匹配时,在使整个表达式能得到匹配的前提下尽可能匹配多的字符,我们称之为贪婪模式,是一种贪得无厌的模式。例如: r"a.*b" 表示匹配 a 开头 b 结尾,中间可以是任意多个字符的字符串,如果用它来匹配 aaabcb,那么它会匹配整个字符串。
>>> re.match(r"a.*b", "aaabcb").group() 'aaabcb'
有时,我们希望尽可能少的匹配,怎么办?只需要在表达式2后面加一个问号" ?",在保证匹配的情况下尽可能少的匹配,比如刚才的例子,我们只希望匹配 aaab,那么只需要修改正则表达式为 r"a.*?b"
>>> re.match(r"a.*?b", "aaabcb").group() 'aaab' >>>
非贪婪模式在爬虫应用中使用非常频繁。比如之前在公众号「Python之禅」曾写过一篇爬取网站并将其转换为PDF文件的场景,在网页上涉及表达式3元素是相对路径的情况,我们需要把它替换成绝对路径
>>> html = '@@##@@@@##@@'
# 非贪婪模式就匹配的两个img标签 # 你可以改成贪婪模式看看可以匹配几个 >>> rex = r'@@##@@' >>> re.findall(rex, html) ['/images/category.png', '/images/js_framework.png'] >>> >>> def fun(match): ... img_tag = match.group() ... src = match.group(1) ... full_src = "http://foofish.net" + src ... new_img_tag = img_tag.replace(src, full_src) ... return new_img_tag ... >>> re.sub(rex, fun, html) @@##@@@@##@@
sub 表达式4可以接受一个函数作为替换目标对象,函数返回值用来替换正则表达式匹配的部分,在这里,我把整个img标签定义为一个正则表达式 r'返回的值是 ',group()
到此,你应该对正则表达式有了初步的了解,现在我想你应该能解决文章表达式5提的问题了。
正则表达式的基本介绍也到这里告一段落,虽然代码示例中用了re模块中的很多方法,但我还没正式介绍该模块,考虑到文章篇幅,我把这部分放在下篇,下篇将对re的常用方法进行介绍。






























