







☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

背景
聊天机器人或客服助手是AI工具,希望通过互联网上的文本或语音与用户的交付,实现业务价值。聊天机器人的发展在这几年间迅速进步,从最初的基于简单逻辑的机器人到现在基于自然语言理解(NLU)的人工智能。对于后者,构建此类聊天机器人时最常用的框架或库包括国外的RASA、Dialogflow和Amazon Lex等,以及国内大厂百度、科大讯飞等。这些框架可以集成自然语言处理(NLP)和NLU来处理输入文本、分类意图并触发正确的操作以生成响应。
随着大型语言模型(LLM)的出现,我们可以直接使用这些模型构建功能齐全的聊天机器人。其中一个著名的LLM例子是来自OpenAI的生成Generative Pre-trained Transformer 3 (GPT-3:chatgpt就是基于gpt fine-tuning及加入人类反馈模型的),它可以通过使用对话或会话数据来fine-tuning模型,生成类似于自然对话的文本。这种能力使其成为构建自定义聊天机器人的最佳选择。
今天我们来聊如何通过fine-tuning GPT-3模型来构建满足属于我们自己的简单会话聊天机器人。
通常,我们希望在自己的业务对话示例的数据集上fine-tuning模型,例如客户服务的对话记录、聊天日志或电影中的字幕。fine-tuning过程调整模型的参数,让它更好地适应这些会话数据,从而使聊天机器人更擅长理解和回复用户输入。
要fine-tuningGPT-3,我们可以使用Hugging Face的Transformers库,该库提供了预训练模型和fine-tuning工具。该库提供了几种不同大小和较多能力的GPT-3模型。模型越大,可以处理的数据就越多,精度也可能越高。但是,为了简单起见,我们这次使用的是OpenAI接口,可通过编写少量的代码来实现fine-tuning。
接下来就是我们使用OpenAI GPT-3 来实现fine-tuning,可从这获取数据集,抱歉我又用国外数据集了,国内真的很少这类已经处理好的数据集。
1、创建Open API密匙
创建帐户非常简单,可以使用打开这个链接就可以完成。我们可以通过openai key访问 OpenAI 上的模型。创建API 密钥步骤如下:
- 登录到您的帐户
- 转到页面的右上角,然后单击帐户名,下拉列表,然后单击“查看 API 密钥”
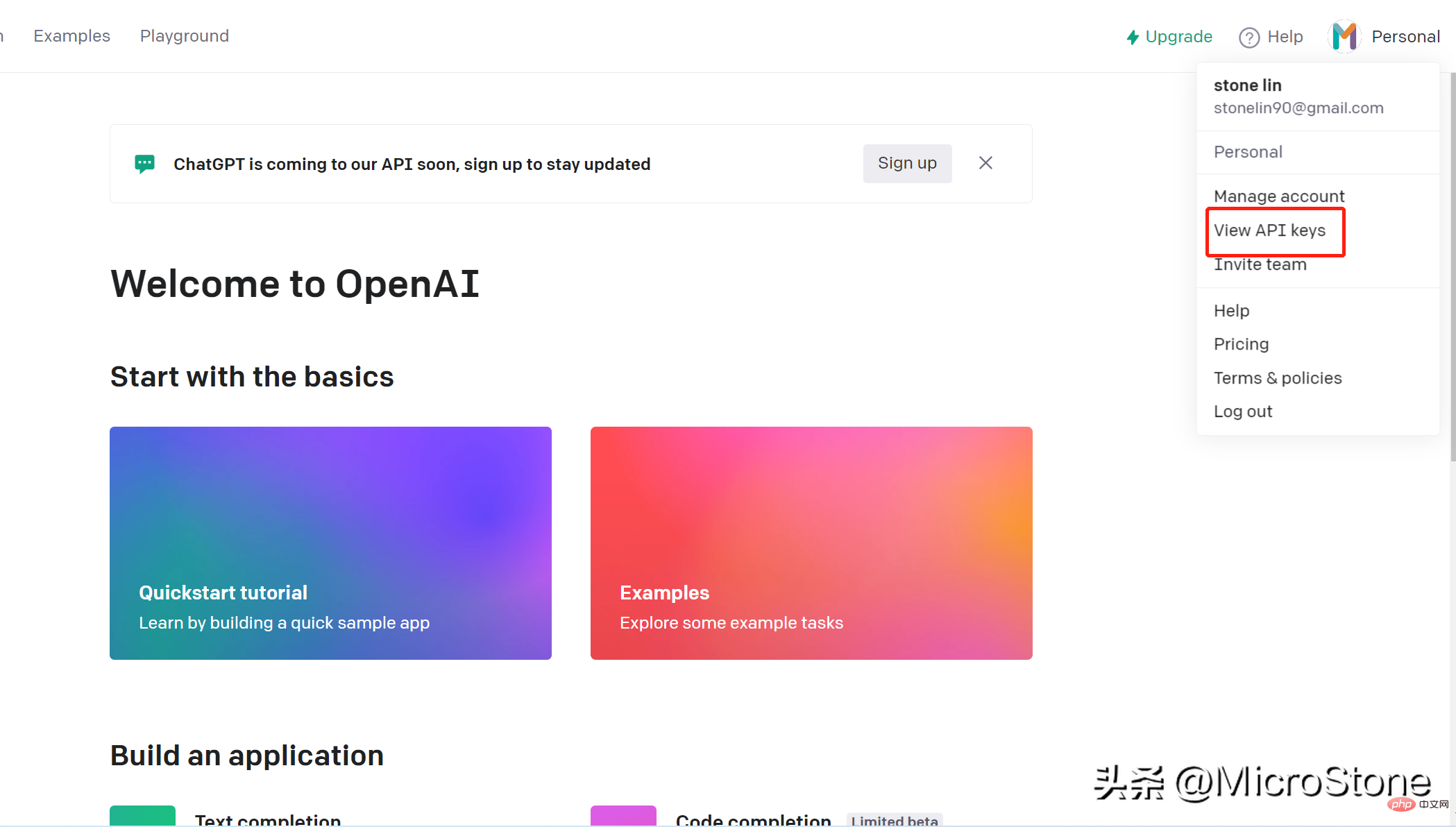
- 单击“创建新密钥”,记得马上复制生成的密钥,切记,并保存好,不然无法再次查看它。
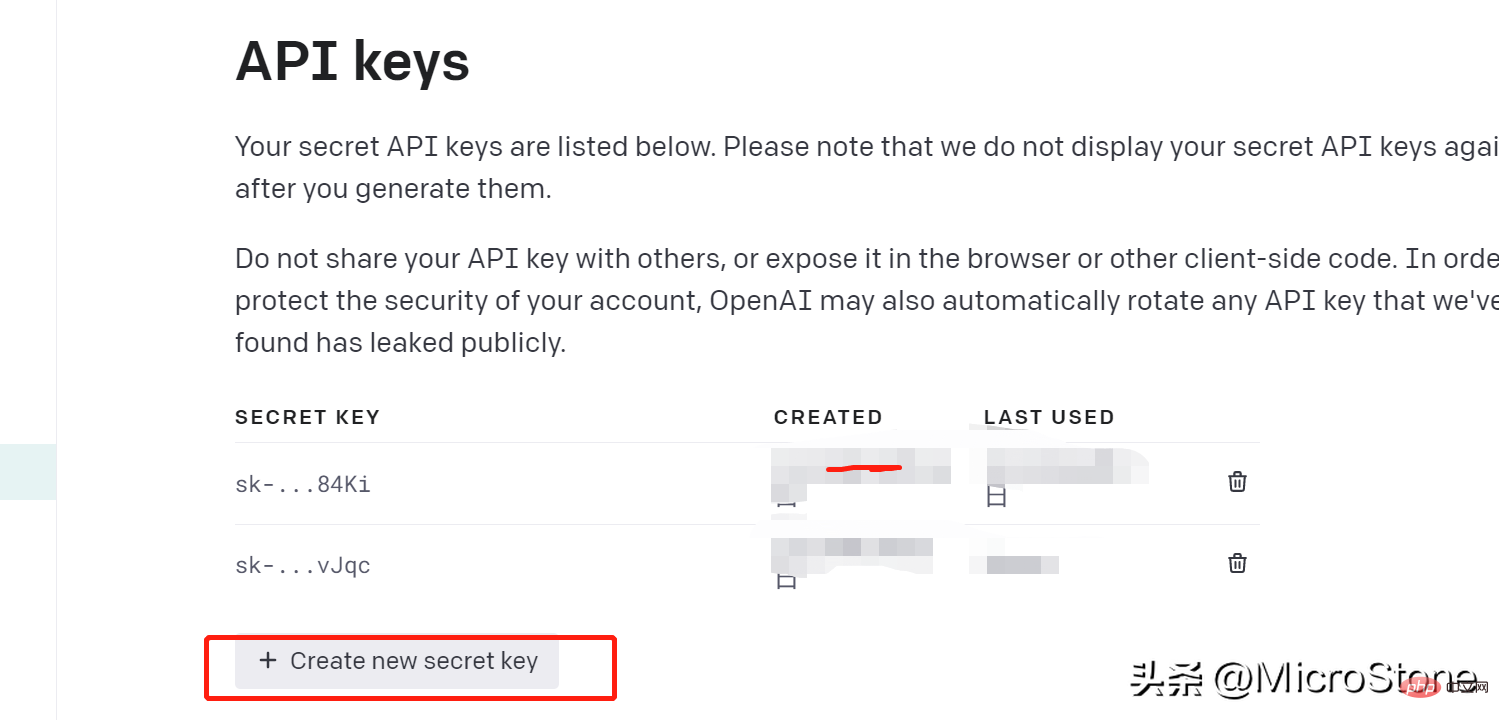
2、准备数据
我们已经创建了api密匙,那么我们可以开始准备fine-tuning模型的数据,在这可以查看数据集。

第一步:
安装 OpenAI 库pip install openai
安装后,我们就可以加载数据了:
import os
import json
import openai
import pandas as pd
from dotenv import load_dotenv
load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv('OPENAI_KEY')
openai.api_key = os.getenv('OPENAI_KEY')
data = pd.read_csv('data/data.csv')
new_df = pd.DataFrame({'Interview AI': data['Text'].iloc[::2].values, 'Human': data['Text'].iloc[1::2].values})
print(new_df.head(5))我们将问题加载到Interview AI列中,并将相应的答案加载到Human列中。我们还需要创建一个环境变量.env文件来保存OPENAI_API_KEY
接下来,我们将数据转换为 GPT-3 的标准。根据文档,确保数据采用JSONL具有两个键的格式,这个很重要:prompt例如completion
{ "prompt" :"<prompt text>" ,"completion" :"<ideal generated text>" }
{ "prompt" :"<prompt text>" ,"completion" :"<ideal generated text>" }重新构造数据集以适应以上方式,基本是循环遍历数据框中的每一行,并将文本分配给Human,将Interview AI文本分配给完成。
output = []
for index, row in new_df.iterrows():
print(row)
completion = ''
line = {'prompt': row['Human'], 'completion': row['Interview AI']}
output.append(line)
print(output)
with open('data/data.jsonl', 'w') as outfile:
for i in output:
json.dump(i, outfile)
outfile.write('n')使用prepare_data命令,这时会在提示时询问一些问题,我们可以提供Y或N回复。
os.system("openai tools fine_tunes.prepare_data -f 'data/data.jsonl' ")最后,一个名为的文件data_prepared.jsonl被转储到目录中。
3、fun-tuning 模型
要fun-tuning模型,我们只需要运行一行命令:
os .system( "openai api fine_tunes.create -t 'data/data_prepared.jsonl' -m davinci " )
这基本上使用准备好的数据从 OpenAI 训练davinci模型,fine-tuning后的模型将存储在用户配置文件下,可以在模型下的右侧面板中找到。
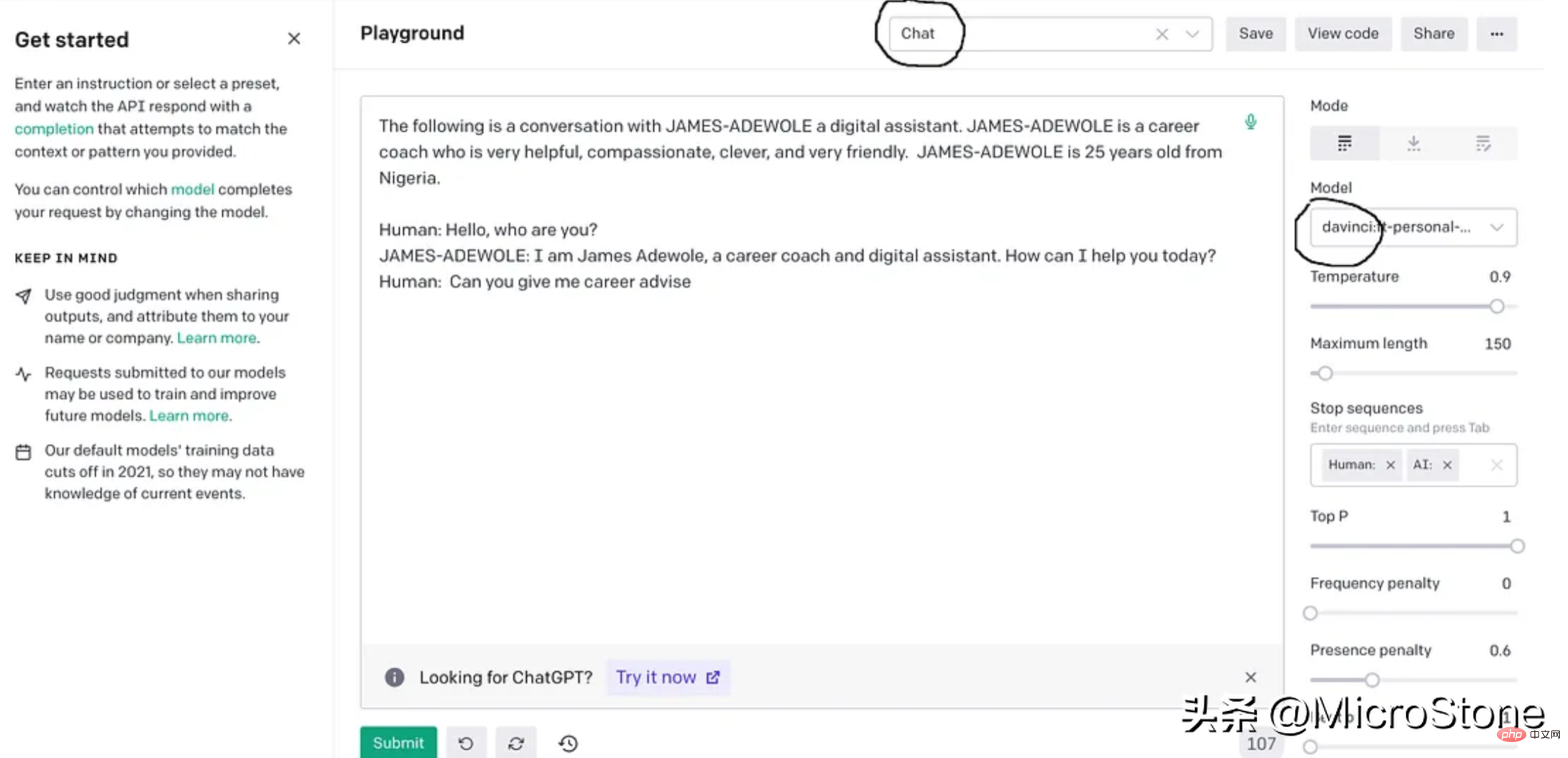
4、模型调试
我们可以使用多种方法来验证我们的模型。可以直接从 Python 脚本、OpenAI Playground 来测试,或者使用 Flask 或 FastAPI 等框构建 Web 服务来测试。
我们先构建一个简单的函数来与此实验的模型进行交互。
def generate_response(input_text):
response = openai.Completion.create(
engine="davinci:ft-personal-2023-01-25-19-20-17",
prompt="The following is a conversation with DSA an AI assistant. "
"DSA is an interview bot who is very helpful and knowledgeable in data structure and algorithms.nn"
"Human: Hello, who are you?n"
"DSA: I am DSA, an interview digital assistant. How can I help you today?n"
"Human: {}nDSA:".format(input_text),
temperature=0.9,
max_tokens=150,
top_p=1,
frequency_penalty=0.0,
presence_penalty=0.6,
stop=["n", " Human:", " DSA:"]
)
return response.choices[0].text.strip()
output = generate_response(input_text)
print(output)把它们放在一起。
import os
import json
import openai
import pandas as pd
from dotenv import load_dotenv
load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv('OPENAI_KEY')
openai.api_key = os.getenv('OPENAI_KEY')
data = pd.read_csv('data/data.csv')
new_df = pd.DataFrame({'Interview AI': data['Text'].iloc[::2].values, 'Human': data['Text'].iloc[1::2].values})
print(new_df.head(5))
output = []
for index, row in new_df.iterrows():
print(row)
completion = ''
line = {'prompt': row['Human'], 'completion': row['Interview AI']}
output.append(line)
print(output)
with open('data/data.jsonl', 'w') as outfile:
for i in output:
json.dump(i, outfile)
outfile.write('n')
os.system("openai tools fine_tunes.prepare_data -f 'data/data.jsonl' ")
os.system("openai api fine_tunes.create -t 'data/data_prepared.jsonl' -m davinci ")
def generate_response(input_text):
response = openai.Completion.create(
engine="davinci:ft-personal-2023-01-25-19-20-17",
prompt="The following is a conversation with DSA an AI assistant. "
"DSA is an interview bot who is very helpful and knowledgeable in data structure and algorithms.nn"
"Human: Hello, who are you?n"
"DSA: I am DSA, an interview digital assistant. How can I help you today?n"
"Human: {}nDSA:".format(input_text),
temperature=0.9,
max_tokens=150,
top_p=1,
frequency_penalty=0.0,
presence_penalty=0.6,
stop=["n", " Human:", " DSA:"]
)
return response.choices[0].text.strip()示例响应:
input_text = "what is breadth first search algorithm" output = generate_response(input_text)
The breadth-first search (BFS) is an algorithm for discovering all the reachable nodes from a starting point in a computer network graph or tree data structure
结论
GPT-3 是一种强大的大型语言生成模型,最近火到无边无际的chatgpt就是基于GPT-3上fine-tuning的,我们也可以对GPT-3进行fine-tuning,以构建适合我们自己业务的聊天机器人。fun-tuning过程调整模型的参数可以更好地适应业务对话数据,让机器人更善于理解和响应业务的需求。经过fine-tuning的模型可以集成到聊天机器人平台中以处理用户交互,还可以为聊天机器人生成客服回复习惯与用户交互。整个实现可以在这里找到,数据集可以从这里下载。


























