







我们常常被教育的做事“三思而后行”,充分运用积累过的经验,现在这句话对ai也有所启发了。
传统的决策AI模型由于遗忘效应的存在不能有效积累经验,但一项由华人主导的研究改变了AI的记忆方式。
新的记忆方式模仿了人类大脑,有效地提高了AI积累经验的效率,从而将AI打游戏的成绩提高了29.9%。
研究团队由六人组成,分别来自米拉-魁北克AI研究院和微软蒙特利尔研究所,其中有四名是华人。
他们将成果命名为的带有记忆的决策Transformer(DT-Mem)。
相比传统的决策模型,DT-Mem适用广泛性更强,模型运算的效率也更高。
除了应用效果,DT-Mem的训练时间也从最短200小时缩短至50小时。
同时,团队还提出了一种微调方式,让DT-Mem能够适应未训练过的新场景。
微调后的模型,面对没有学习过的游戏,也能拥有不错的表现。
工作机制受到人类启发
传统的决策模型基于LLM进行设计,采用隐性记忆,其性能依赖于数据和计算。
隐性记忆是无意识产生而非刻意记住的,因而也无法有意识地进行调用。
说得通俗一些,就是明明有关内容就存储在那里,但是模型却并不知道它的存在。
隐性记忆的这一特点决定了传统模型存在遗忘现象,导致其工作效率往往不高。
遗忘现象表现为,在学了新的问题解决方式之后,模型可能会将旧的内容忘记,哪怕新旧问题是同一类型。
而人脑采用分布式记忆存储方式,记忆的内容被分散存储在大脑中的多个不同区域。
这种方式有助于有效地管理和组织多种技能,从而减轻遗忘现象。
受此启发,研究团队提出了一个内部工作记忆模块来存储、混合和检索不同下游任务的信息。
具体而言,DT-Mem由Transformer、记忆模块和多层感知(MLP)模块三部分组成。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
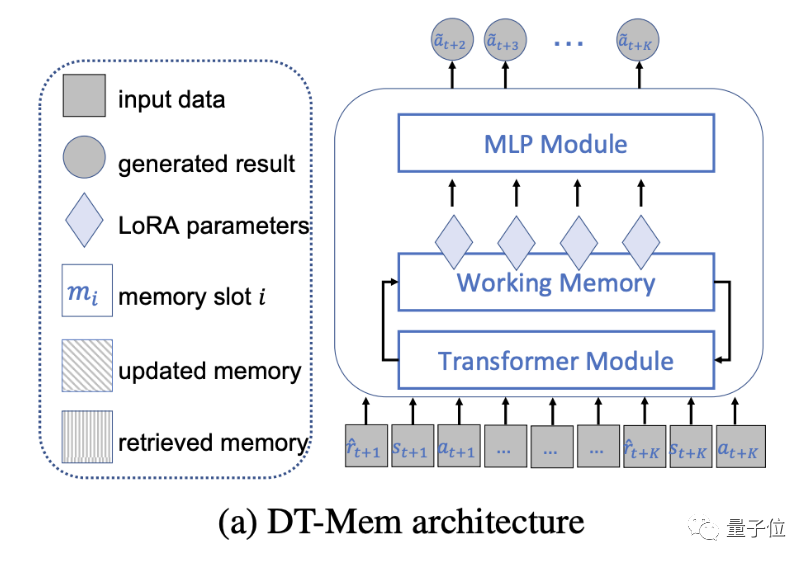
DT-Mem的Transformer模仿了GPT-2的架构,但删去了注意力机制后的前馈层。
同时,GPT-2中的MLP模块被拆分成了独立组件,作为DT-Mem的一部分。
在二者之间,研究团队引入了一个工作记忆模块,用于存储和处理中间信息。
这一结构是受到神经图灵机的启发,其中的记忆被用于推断多种算法。
记忆模块分析Transformer输出的信息,并决定其存储位置以及与已有信息的整合方式。
此外,该模块还要考虑这些信息在今后做出决策的过程当中如何使用。
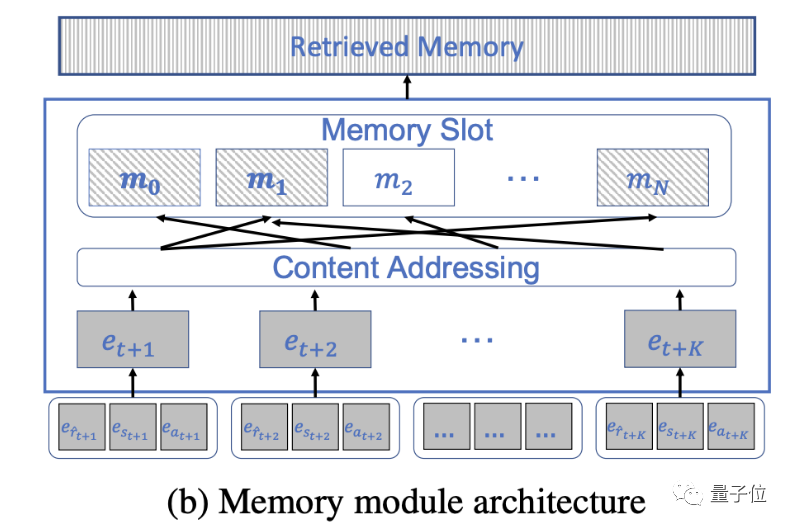
这些任务大概通过五个步骤来完成,记忆模块首先被初始化为一个随机矩阵。
然后是对输入信息的整理,这一步并不是将信息传给Transformer,而是以元组形式存入同一空间。
之后就要确定存储位置。人类通常会将相关的信息存储到同一位置,DT-Mem也是基于这一原理。
最后两步——记忆更新和检索是记忆模块的核心,也是整个DT-Mem中最重要的环节。
记忆更新,即对已有信息进行编辑替换,以确保信息能根据任务需要及时更新。

这一步中DT-Mem会计算擦除和写入两个向量,进而判断如何与已有数据混合。
记忆检索则是对已有信息的访问和恢复,在需要做出决策时及时调取相关有用信息。
投入实际使用之前,DT-Mem还要经历预训练过程。

而对于DT-Mem的微调,团队也提出了一种新的方式。
由于使用的是基于任务进行标记的数据,这种微调能够帮助DT-Mem适应新的任务。
这一过程基于低秩适应(LoRA)进行,在已有的矩阵中加入低秩元素。

训练时间最多缩短32倍
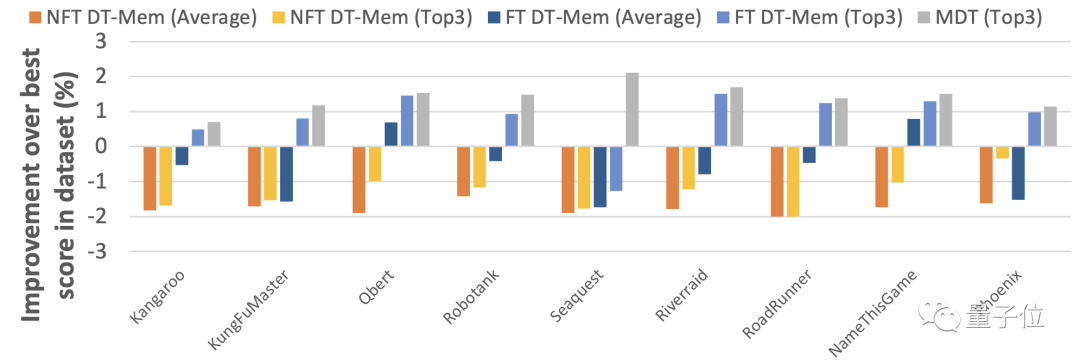
为了测试DT-Mem的决策能力,研究团队让它玩了几款游戏。
游戏一共有5款,全部来自Atari公司。
同时,团队还测试了传统模型M[ulti-game]DT的表现作为参照。
结果,DT-Mem在其中4款游戏里的最好成绩均胜过MDT。
具体而言,DT-Mem比MDT的DQN标准化分数提高了29.9%。
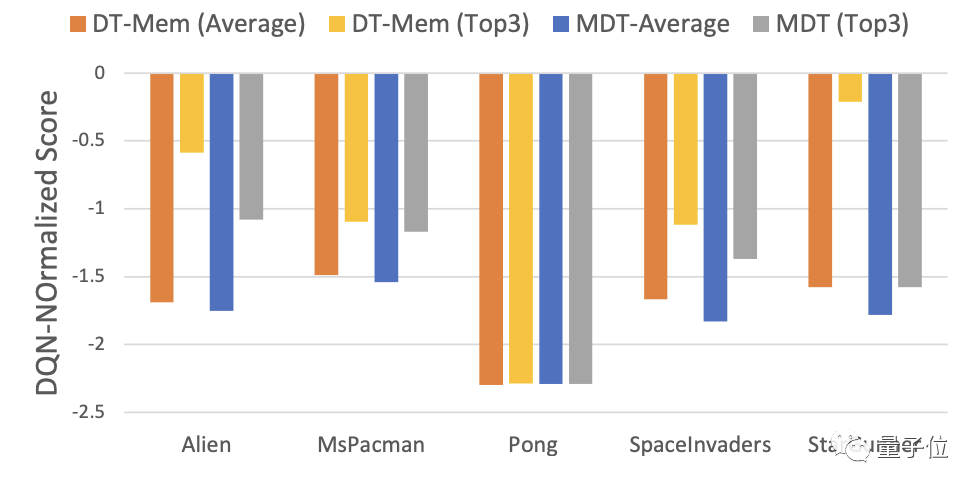
但是,DT-Mem的参数量只有20M,仅是MDT(200M参数)的10%。
这样的表现,说是四两拨千斤一点也不过分。
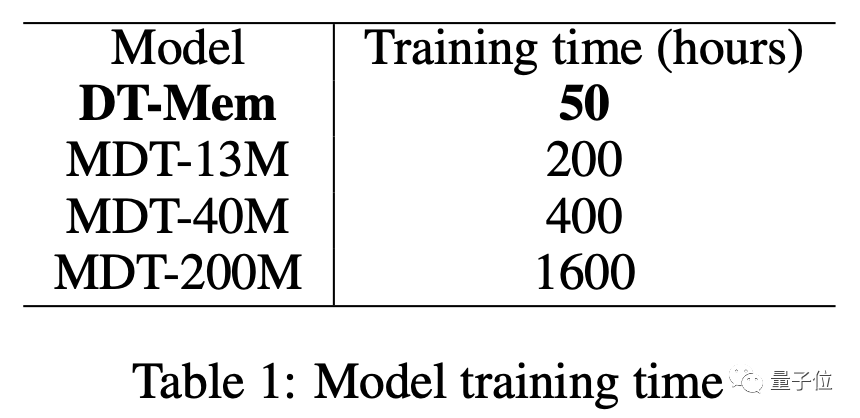
除了表现优异,DT-Mem的训练效率也完爆MDT。
13M参数量版本的MDT需要200小时进行训练,而20M的DT-Mem却只需要50个小时。
如果和200M的版本相比,训练时间足足缩短了32倍,表现却更优异。
而针对团队提出的微调方式的测试结果也表明,这种微调增强了DT-Mem适应未知情景的能力。
需要说明的是,下表中用来测试的游戏对于MDT来说是已知的,因此MDT的表现在这一轮当中不作为衡量依据。
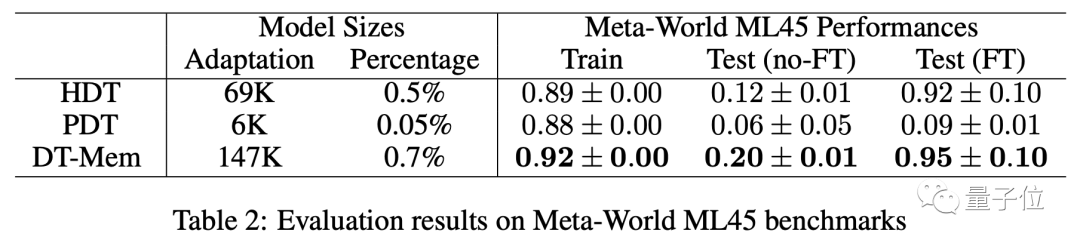
除了玩游戏,团队还使用了Meta-World ML45基准对DT-Mem进行了测试。
这次用作参照的是H[yper]DT和P[romot]DT。
结果显示,未经微调的模型当中,DT-Mem成绩比HDT高出8个百分点。
需要说明的是,这里测试的HDT本身参数量虽然只有69K,但需依赖于2.3M参数量的预训练模型,因此实际的参数量是DT-Mem(147K)的10余倍。
论文地址:https://arxiv.org/abs/2305.16338





























