







手工小作坊,终究敌不过工厂流水线。
如果说,当下的生成式AI,是一个正在茁壮成长的孩子,那么源源不断的数据,就是其喂养其生长的食物。
数据标注是制作这一“食物”的过程
然而,这一过程真的很卷,很累人。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
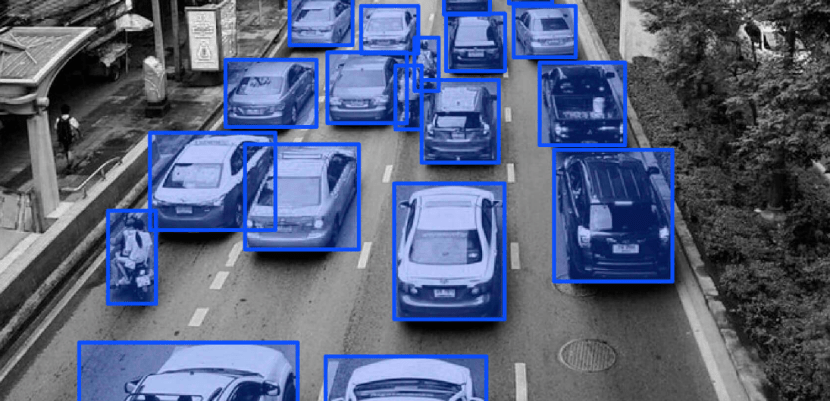
进行标注的“标注师”不仅需要反复地识别出图像中的各种物体、颜色、形状等,有时候甚至需要对数据进行清洗和预处理。
随着人工智能技术的不断进步,人工数据标注的局限性也越来越明显。人工数据标注不仅耗费时间和精力,而且有时难以保证质量

为了解决这些问题,谷歌最近提出了一种名为AI反馈强化学习(RLAIF)的方法,通过使用大型模型代替人类进行偏好标注
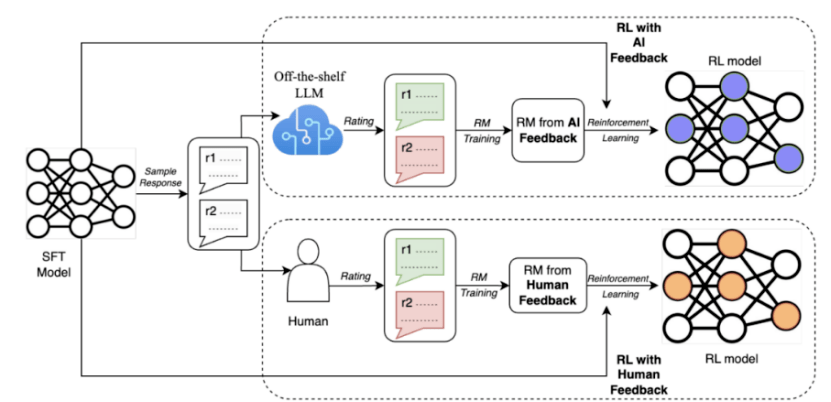
研究结果显示,RLAIF能够在没有依赖人类标注的情况下,达到与人类反馈强化学习(RLHF)相当的改进效果,两者的胜率都是50%。此外,研究还发现,RLAIF和RLHF相比于监督微调(SFT)的基线策略都更优越
这些结果表明,RLAIF不需要依赖于人工标注,是RLHF的可行替代方案。
如果这项技术将来真的被广泛推广和普及,那么依赖人工“拉框”进行数据标注的许多企业是否将面临绝境?
01 数据标注现状
如果要简单地总结目前国内标注行业的现状,那就是:劳动量大,但效率却不太高,属于费力不讨好的状态。
标注企业被称为AI领域的数据工厂,通常集中在东南亚、非洲或是中国的河南、山西、山东等人力资源丰富的地区。
为了降低成本,标注公司的老板们会在县城租一块场地,放置电脑设备。一旦有订单,他们就会在附近招募兼职人员来处理,如果没有订单,就会解散休息
简单来说,这个工种有点类似马路边上的临时装修工。

在工位上,系统会随机给“标注师”一组数据,一般包含几个问题和几个回答。
之后,“标注师”需要先标注出这个问题属于什么类型,随后给这些回答分别打分并排序。
此前,人们在谈论国产大模型与GPT-4等先进大模型的差距时,总结出了国内数据质量不高的原因。
为什么数据质量不高?其中一部分原因在于数据标注的“流水线”
目前,中文大模型的数据来源是两类,一类是开源的数据集;一类是通过爬虫爬来的中文互联网数据。
中文大模型表现不够好的主要原因之一就是互联网数据质量,比如,专业人士在查找资料的时候一般不会用百度。
因此,在面对一些较为专业、垂直的数据问题,例如医疗、金融等,就要与专业团队合作。
可这时,问题又来了:对于专业团队来说,在数据方面不仅回报周期长,而且先行者很有可能会吃亏。
例如,某家标注团队花了很多钱和时间,做了很多数据,别人可能花很少的钱就可以直接打包买走。
面对这种“搭便车困境”,国内许多大型模型都陷入了数据虽然众多,但质量却不高的奇怪境地
既然如此,那目前国外一些较为领先的AI企业,如OpenAI,他们是怎么解决这一问题的?

OpenAI在数据标注方面并没有放弃使用廉价的密集劳动来降低成本
例如,此前就曝出其曾以2美元/小时的价格,雇佣了大量肯尼亚劳工进行有毒信息的标注工作。
然而,重要的区别在于如何解决数据质量和标注效率的问题
具体来说,OpenAI在这方面,与国内企业最大的不同,就在于如何降低人工标注的“主观性”、“不稳定性”的影响。

02 OpenAI的方法 重新撰写内容时,需要将语言改写为中文,不需要出现原始句子
为了降低这样人类标注员的“主观性”和“不稳定性”,OpenAI大致采用了两个主要的策略:
1、人工反馈与强化学习相结合;
在重新写作时,需要将原始内容转换为中文。以下是重新写作后的内容: 首先,让我们谈谈标注方式。OpenAI的人工反馈与国内最大的区别在于,它主要是对智能系统的行为进行排序或评分,而不是对其输出进行修改或标注
智能系统的行为是指在复杂环境中,根据自身目标和策略,智能系统所采取的一系列动作或决策
比如玩游戏、操控机器人、与人对话等
智能系统的输出,则是指在一个简单的任务中,根据输入的数据,生成一个结果或回答,例如写一篇文章、画一幅画。
普遍而言,智能系统的行为往往难以用“正确”或“错误”来判断,而更需要用偏好或满意度来评价
这种以“偏好”或“满意度”为标准的评价体系,不需要修改或标注具体的内容,因此减少了人类主观性、知识水平等因素对数据标注质量和准确性的影响
诚然,国内企业在进行标注时,也会使用类似“排序”、“打分”的体系,但由于缺乏OpenAI那样的“奖励模型”作为奖励函数来优化智能系统的策略,这样的“排序”和“打分”,本质上仍然是一种对输出进行修改或标注的方法。
2、多样化、大规模的数据来源渠道;
国内的数据标注来源主要是第三方标注公司或科技公司自建团队,这些团队多为本科生组成,缺乏足够的专业性和经验,难以提供高质量和高效率的反馈。

相比之下,OpenAI的人工反馈是通过多个渠道和团队获得的
OpenAI与多家数据公司和机构合作,例如Scale AI、Appen、Lionbridge AI等,不仅使用开源数据集和互联网爬虫来获取数据,还致力于获取更多样化和高质量的数据
这些数据公司和机构的标注手段与国内的同行相比,更加“自动化”和“智能化”

例如,Scale AI使用了一种称为 Snorkel的技术,它是一种基于弱监督学习的数据标注方法,可以从多个不精确的数据源中生成高质量的标签。
同时,Snorkel还可以利用规则、模型、知识库等多种信号来为数据添加标签,而不需要人工直接标注每个数据点。这样可以大大减少人工标注的成本和时间。

在数据标注成本降低、周期缩短的情况下,这些具备竞争优势的数据公司可以选择高价值、高难度、高门槛的细分领域,如自动驾驶、大语言模型、合成数据等,以不断提升自身的核心竞争力和差异化优势
如此一来,“先行者会吃亏”的搭便车困境,也被强大的技术和行业壁垒给消弭了。
标准化与小作坊的对比
由此可见,AI自动标注技术,真正淘汰的只是那些还在使用纯人工的标注公司。
尽管数据标注听上去是一个“劳动密集型”产业,但是一旦深入细节,便会发现,追求高质量的数据并不是一件容易的事。
以海外数据标注的独角兽Scale AI为代表,Scale AI不仅仅在使用非洲等地的廉价人力资源,同样还招聘了数十名博士,来应对各行业的专业数据。

Scale AI为OpenAI等大型模型企业提供的最大价值在于数据标注的质量
而要想最大程度地保障数据质量,除了前面提到的使用AI辅助标注外,Scale AI的另一大创新,就是了一个统一的数据平台。
这些平台,包括了Scale Audit、Scale Analytics、ScaleData Quality 等。通过这些平台,客户可以监控和分析标注过程中的各种指标,并对标注数据进行校验和优化,评估标注的准确性、一致性和完整性。
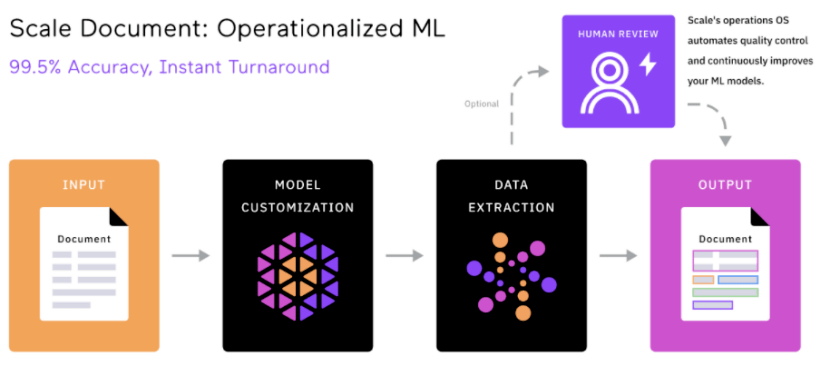
可以说,这样标准化、统一化的工具与流程,成为了区分标注企业中“流水线工厂”和“手工小作坊”的关键因素。
在这方面,目前国内大部分的标注企业,都仍在使用“人工审核”的方式来审核数据标注的质量,只有百度等少数巨头引入了较为先进的管理和评估工具,如EasyData智能数据服务平台。
如果没有专门的工具来监控和分析标注结果和指标,那么在关键的数据审核方面,对数据质量的把关就只能依赖于人工的经验,这种方式仍然只能达到作坊式水准

因此,越来越多的中国企业,如百度、龙猫数据等,开始使用机器学习和人工智能技术,以提高数据标注的效率和质量,实现人机协作的模式
从这个角度来看,人工智能标注的出现并不意味着国内标注企业的末日,而只是传统的低效、廉价、缺乏技术含量的劳动密集型标注方式的末日



























