在过去的一年里,生成式 ai 发展迅猛,在这当中,文本生成一直是一个特别受欢迎的领域,很多开源项目如 llama.cpp、vllm 、 mlc-llm 等,为了取得更好的效果,都在进行不停的优化。作为机器学习社区中最受欢迎框架之一的 pytorch,自然也是抓住了这一新的机遇,不断优化。为此让大家更好的了解这些创新,pytorch 团队专门设置了系列博客,重点介绍如何使用纯原生 pytorch 加速生成式 ai 模型。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

代码地址:https://github.com/pytorch-labs/gpt-fast我们先来看看结果,该团队重写 LLM,推理速度比基线足足快了 10 倍,并且没有损失准确率,只用了不到 1000 行的纯原生 PyTorch 代码!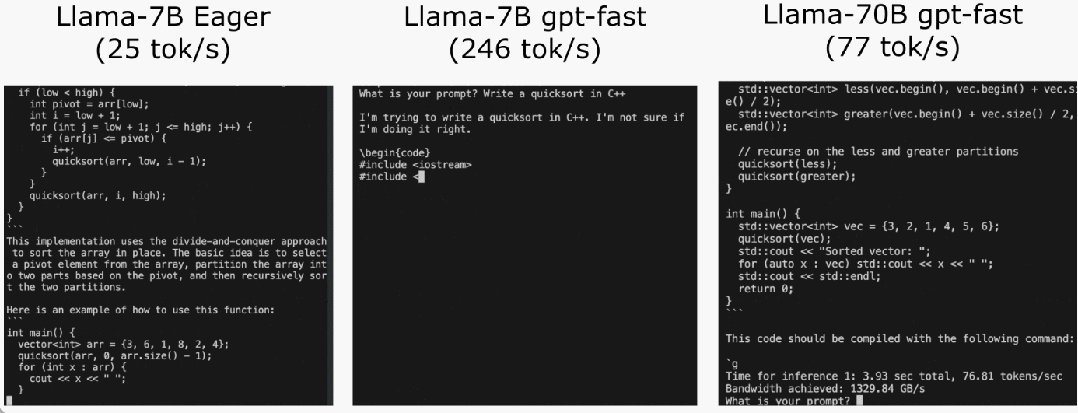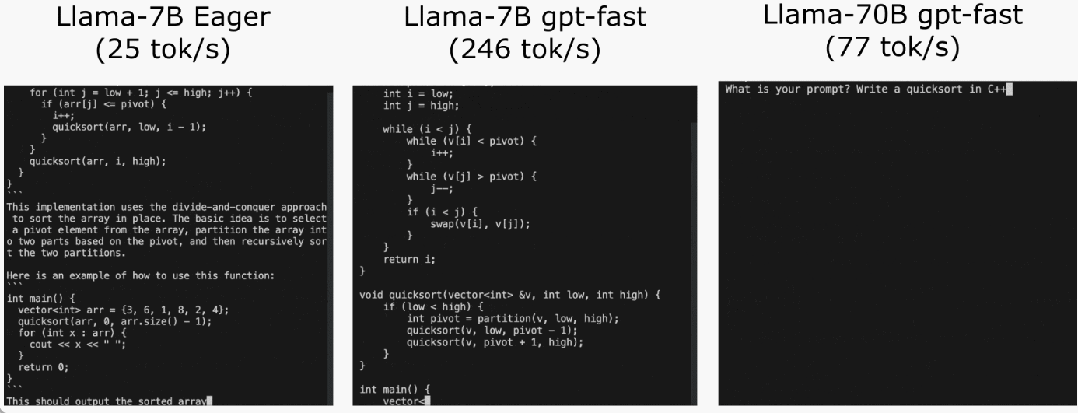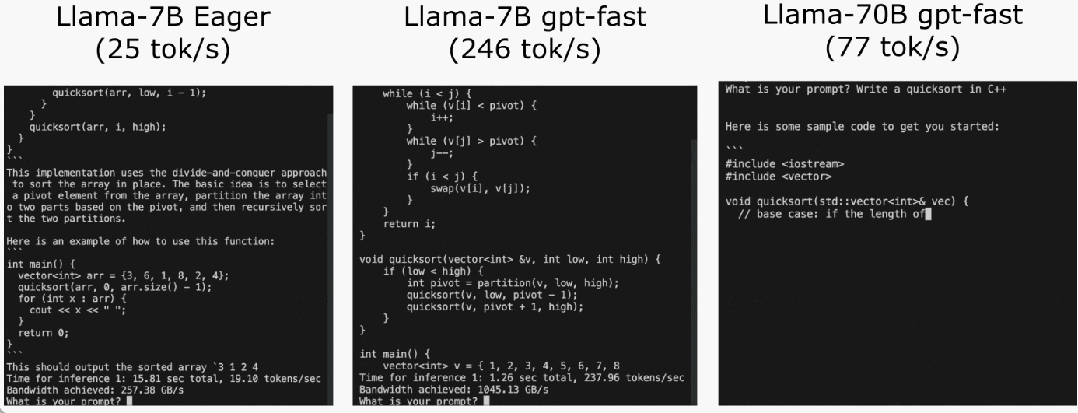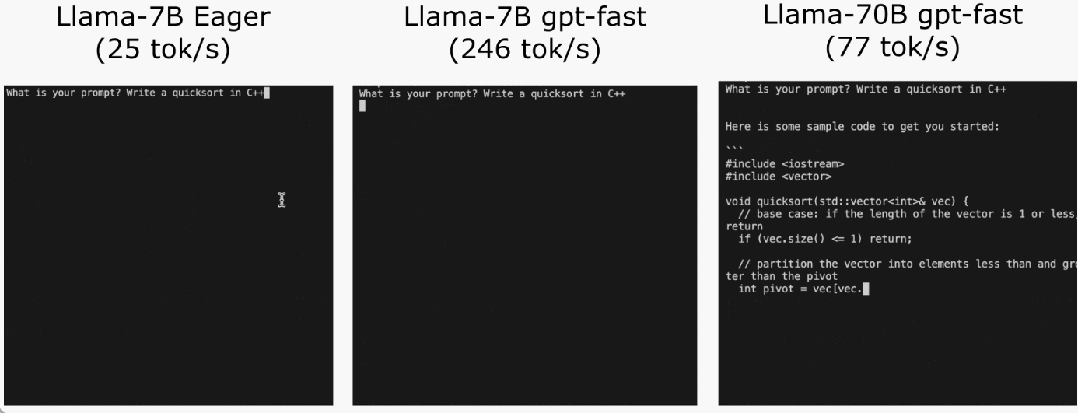
所有基准测试都在 A100-80GB 上运行的,功率限制在 330W。
- Torch.compile:PyTorch 模型编译器, PyTorch 2.0 加入了一个新的函数,叫做 torch.compile (),能够通过一行代码对已有的模型进行加速;
- Speculative Decoding:一种大模型推理加速方法,使用一个小的「draft」模型来预测大的「目标」模型的输出;
- 张量并行:通过在多个设备上运行模型来加速模型推理。
该研究表示,在没有优化之前,大模型的推理性能为 25.5 tok/s,效果不是很好: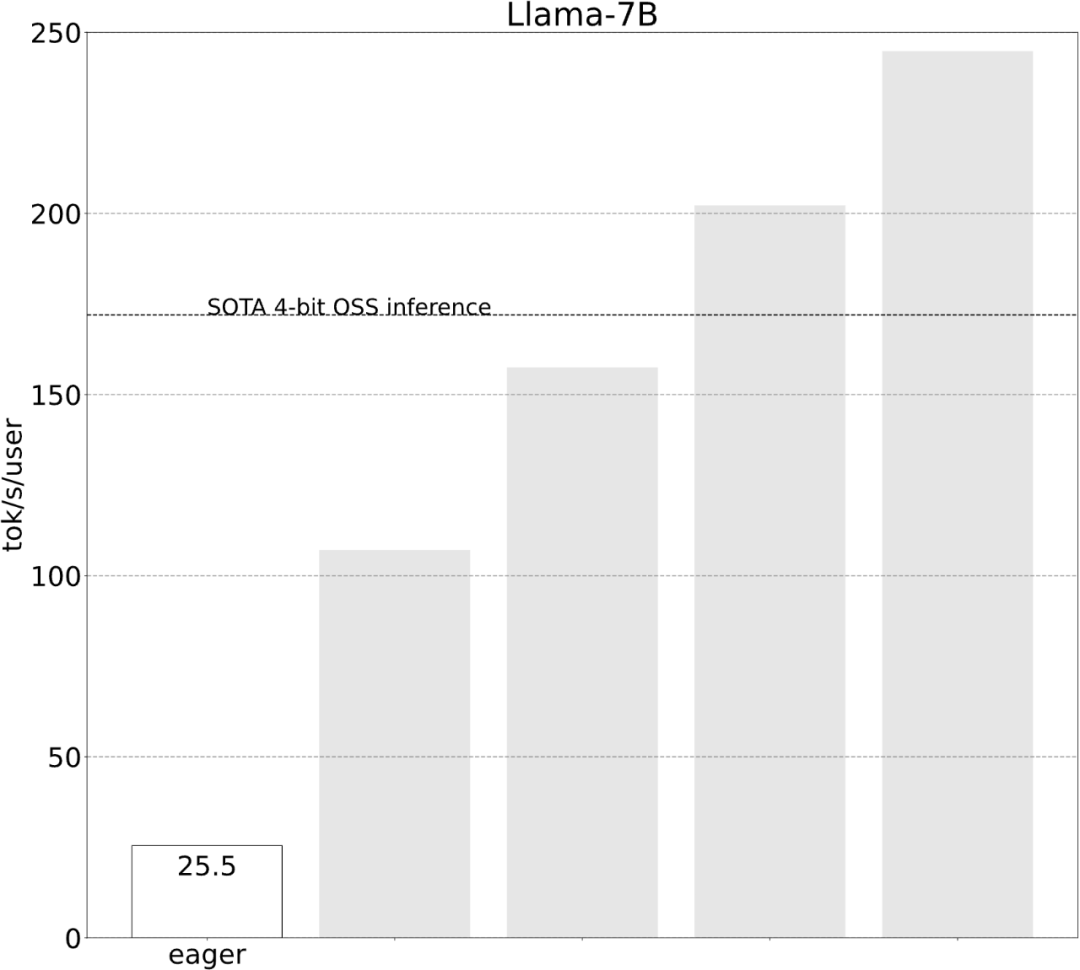
经过一番探索后终于找到了原因:CPU 开销过大。然后就有了下面的 6 步优化过程。
第一步:通过 Torch.compile 和静态 KV 缓存减少 CPU 开销,实现 107.0 TOK/Storch.compile 允许用户将更大的区域捕获到单个编译区域中,特别是在 mode=”reduce-overhead” 时(参考下面的代码),这一功能对于减少 CPU 开销非常有效,除此以外,本文还指定 fullgraph=True,用来验证模型中没有「图形中断」(即 torch.compile 无法编译的部分)。
然而,即使有 torch.compile 的加持,还是会遇到一些障碍。第一个障碍是 kv 缓存。即当用户生成更多的 token 时, kv 缓存的「逻辑长度(logical length)」会增长。出现这种问题有两个原因:一是每次缓存增长时重新分配(和复制)kv 缓存的成本非常高;其次,这种动态分配使得减少开销变得更加困难。为了解决这个问题,本文使用静态 KV 缓存,静态分配 KV 缓存的大小,然后屏蔽掉注意力机制中未使用的值。
第二个障碍是 prefill 阶段。用 Transformer 进行文本生成可视为一个两阶段过程:1. 用来处理整个提示的 prefill 阶段 2. 解码 token.尽管 kv 缓存被设置为静态化,但由于提示长度可变 ,prefill 阶段仍然需要更多的动态性。因此,需要使用单独的编译策略来编译这两个阶段。
虽然这些细节有点棘手,但实现起来并不困难,而且性能的提升是巨大的。这一通操作下来,性能提高了 4 倍多,从 25 tok/s 提高到 107 tok/s。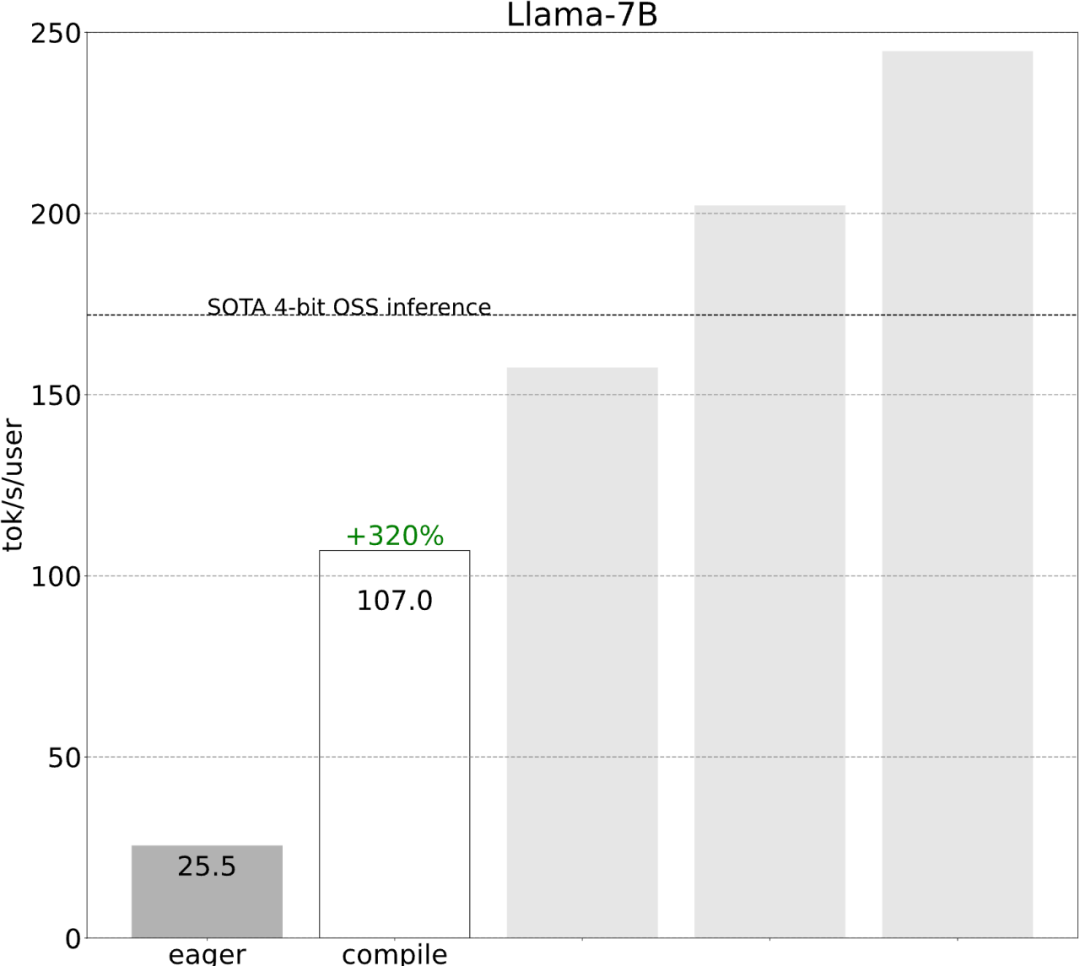
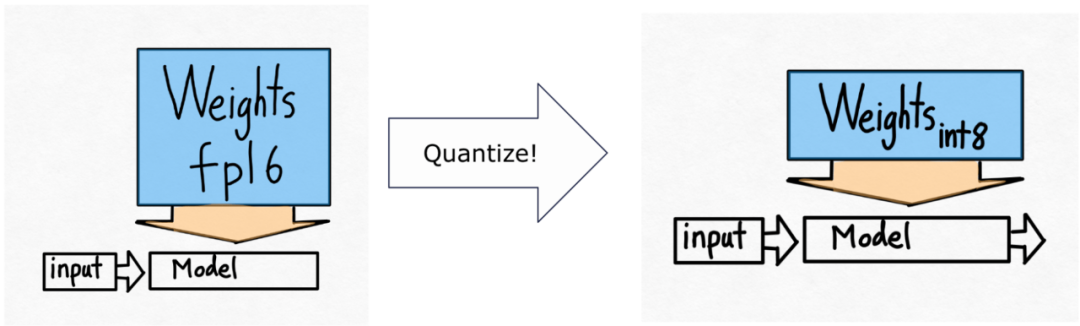
第二步:通过 int8 权重量化缓解内存带宽瓶颈,实现 157.4 tok /s通过上文,我们已经看到应用 torch.compile 、静态 kv 缓存等带来的巨大加速,但 PyTorch 团队并不满足于此,他们又找了其他角度进行优化。他们认为加速生成式 AI 训练的最大瓶颈是将权重从 GPU 全局内存加载到寄存器的代价。换句话说,每次前向传播都需要「接触(touch)」GPU 上的每个参数。那么,理论上我们能够以多快的速度「接触」模型中的每个参数?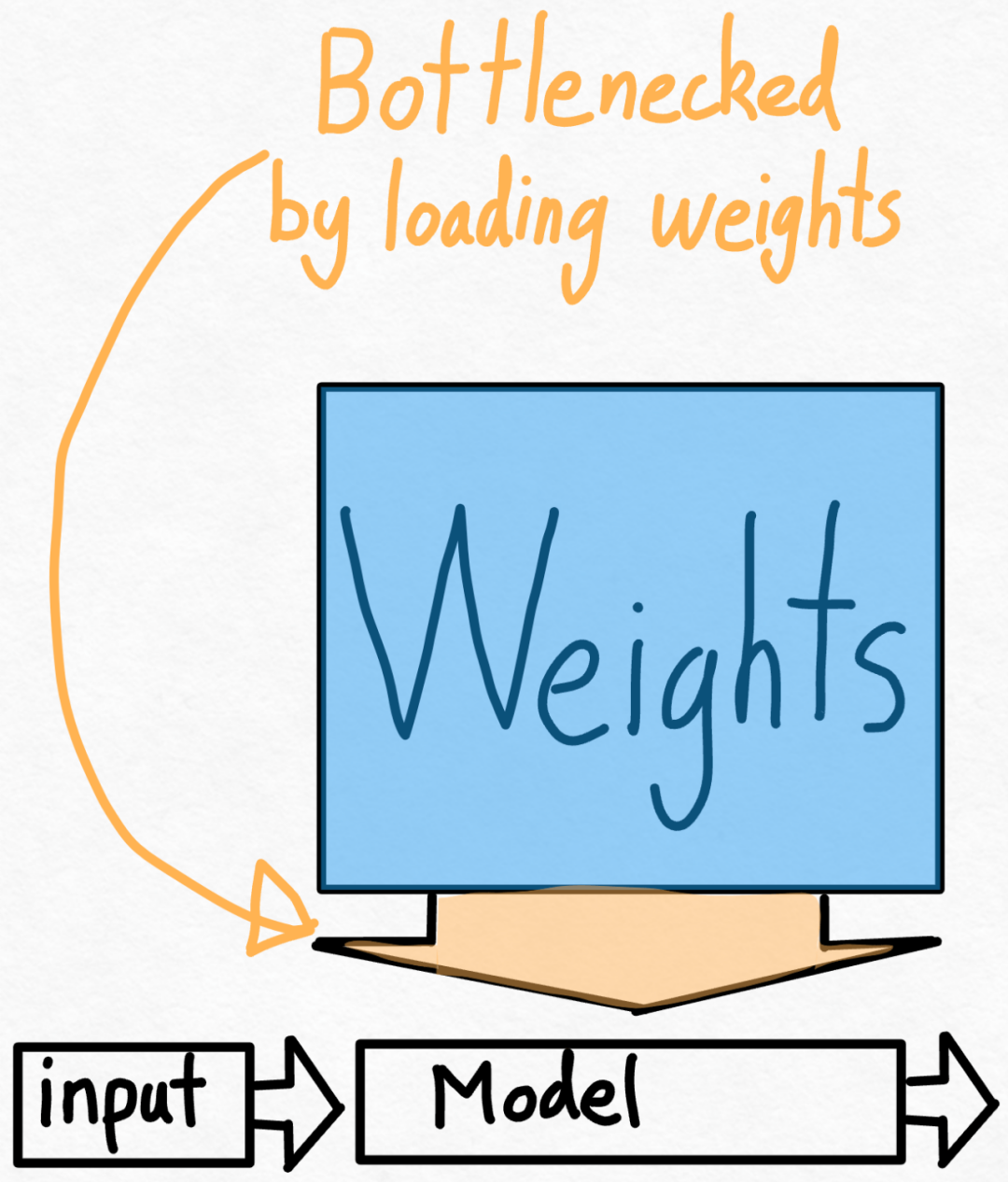
为了衡量这一点,本文使用模型带宽利用率(MBU),计算它非常简单,如下所示:
举例来说,对于一个 7B 参数模型,每个参数都存储在 fp16 中(每个参数 2 字节),可以实现 107 tokens/s。A100-80GB 理论上有 2 TB/s 的内存带宽。如下图所示,将上述公式带入具体的数值,可以得到 MBU 为 72%!这个结果是相当不错的,因为很多研究很难突破 85%。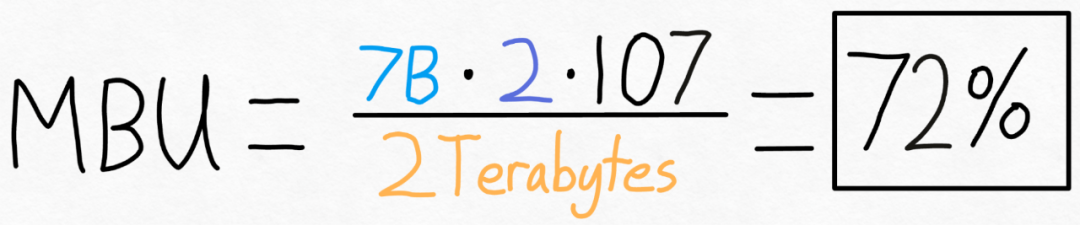
但 PyTorch 团队还想将这个数值在提高一些。他们发现无法改变模型中参数的数量,也无法改变 GPU 的内存带宽。但他们发现可以更改每个参数存储的字节数!

Veo
Google 最新发布的 AI 视频生成模型
下载
请注意,这仅是量化权重,计算本身仍然在 bf16 中完成。此外,有了 torch.compile,可以轻松生成 int8 量化的高效代码。
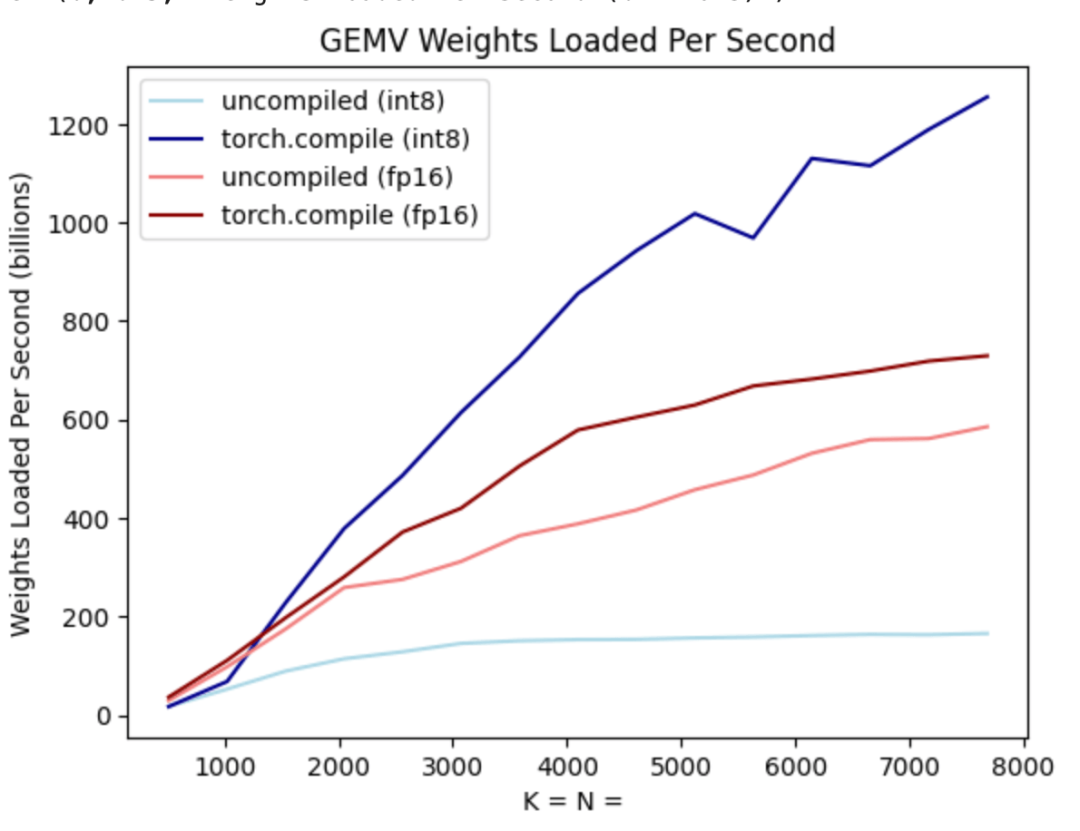
就像上图所展示的,从深蓝色线(torch.compile + int8)可以看出,使用 torch.compile + int8 仅权重量化时,性能有显着提升。将 int8 量化应用于 Llama-7B 模型,性能提高了约 50%,达到 157.4 tokens/s。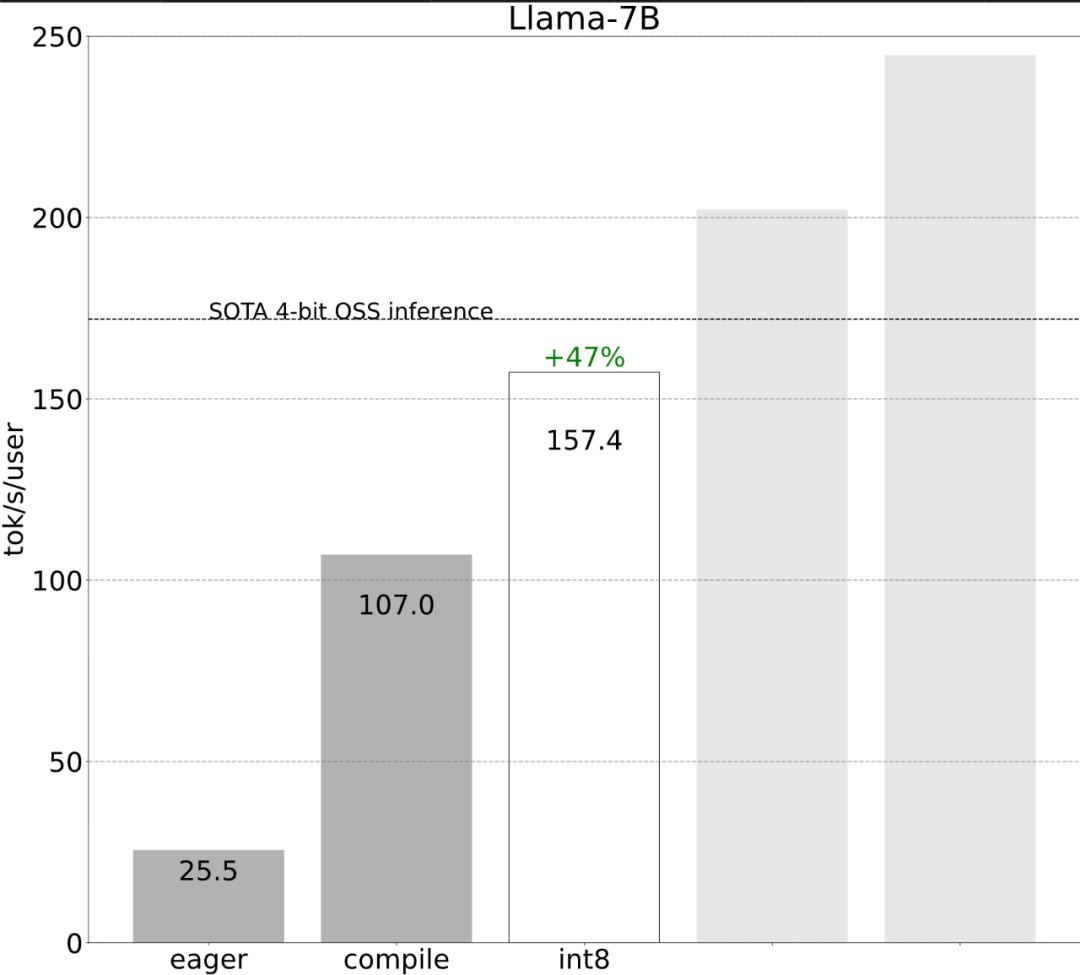
第三步:使用 Speculative Decoding
即使在使用了 int8 量化等技术之后,该团队仍然面临着另一个问题,即为了生成 100 个 token,必须加载权重 100 次。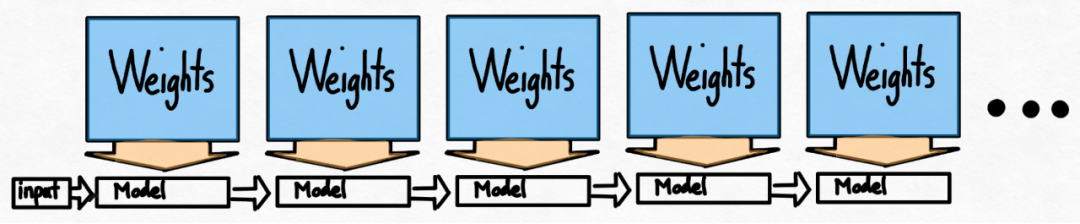
即使权重被量化,一遍又一遍地加载权重也避免不了,这种问题该如何解决呢?事实证明,利用 speculative decoding 能够打破这种严格的串行依赖性并获得加速。
该研究使用草稿(draft)模型生成 8 个 token,然后使用验证器模型并行处理,丢弃不匹配的 token。这一过程打破了串行依赖。整个实现过程大约 50 行原生 PyTorch 代码。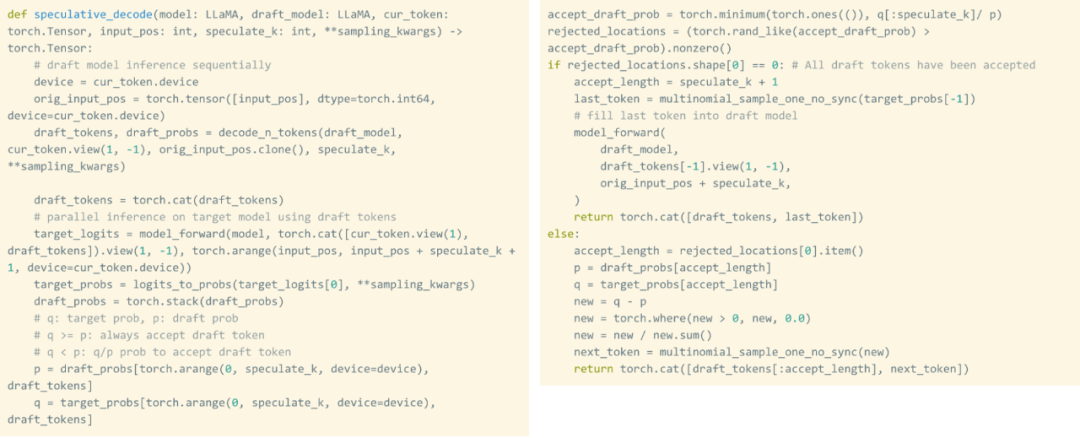
第四步:使用 int4 量化和 GPTQ 方法进一步减小权重,实现 202.1 tok/s本文发现,当权重为 4-bits 时,模型的准确率开始下降。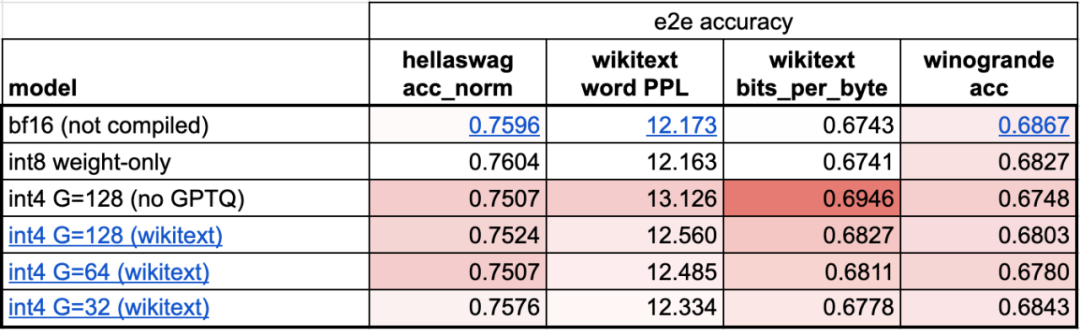
为了解决这个问题,本文使用两个技巧来解决:第一个是拥有更细粒度的缩放因子;另一种是使用更先进的量化策略。将这些操作组合在一起,得到如下: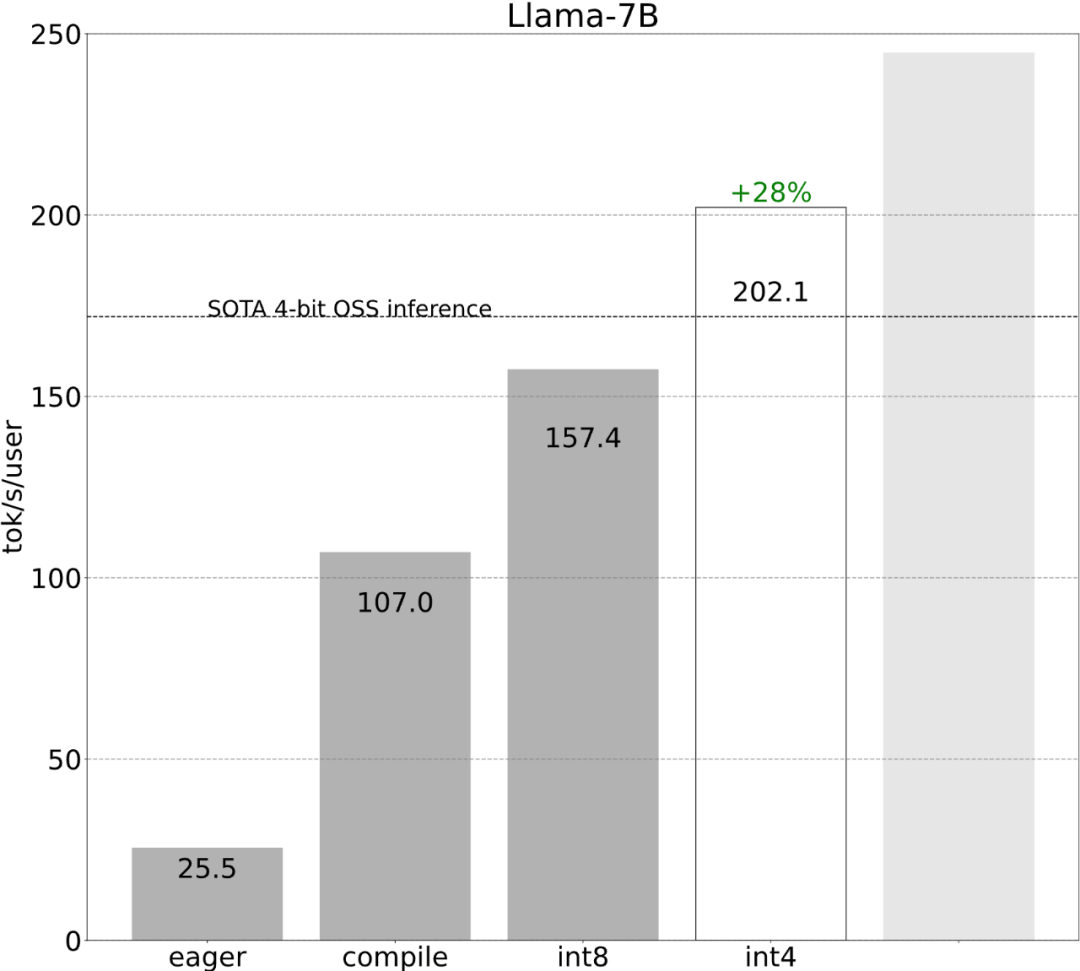
第五步:将所有内容组合在一起,得到 244.7 tok/s最后,将所有技术组合在一起以获得更好的性能,得到 244.7 tok/s。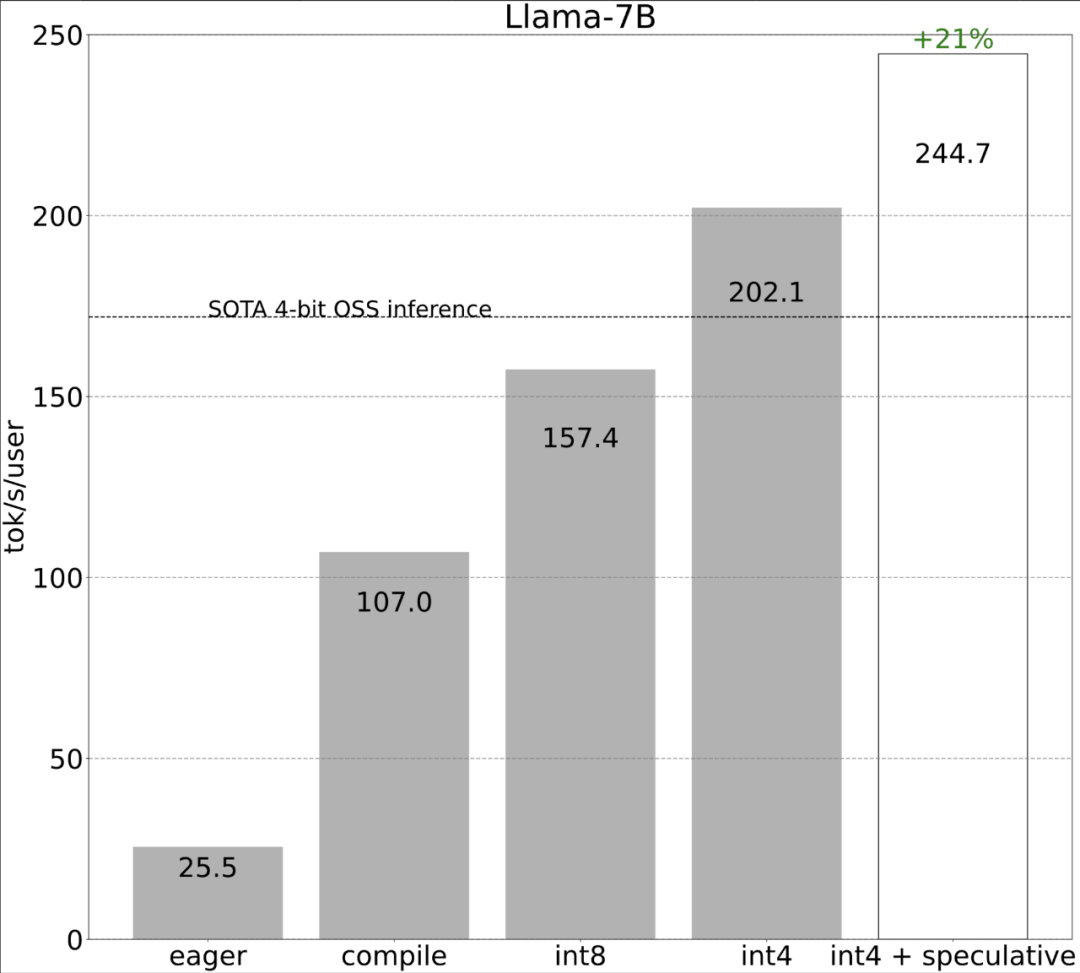
到目前为止,本文一直是在单个 GPU 上最大限度地减少延迟。其实,使用多个 GPU 也是可以的,这样一来,延迟现象会得到进一步改善。非常庆幸的是,PyTorch 团队提供了张量并行的低级工具,只需 150 行代码,并且不需要任何模型更改。
前面提到的所有优化都可以继续与张量并行性组合,将这些组合在一起,能以 55 tokens/s 的速度为 Llama-70B 模型提供 int8 量化。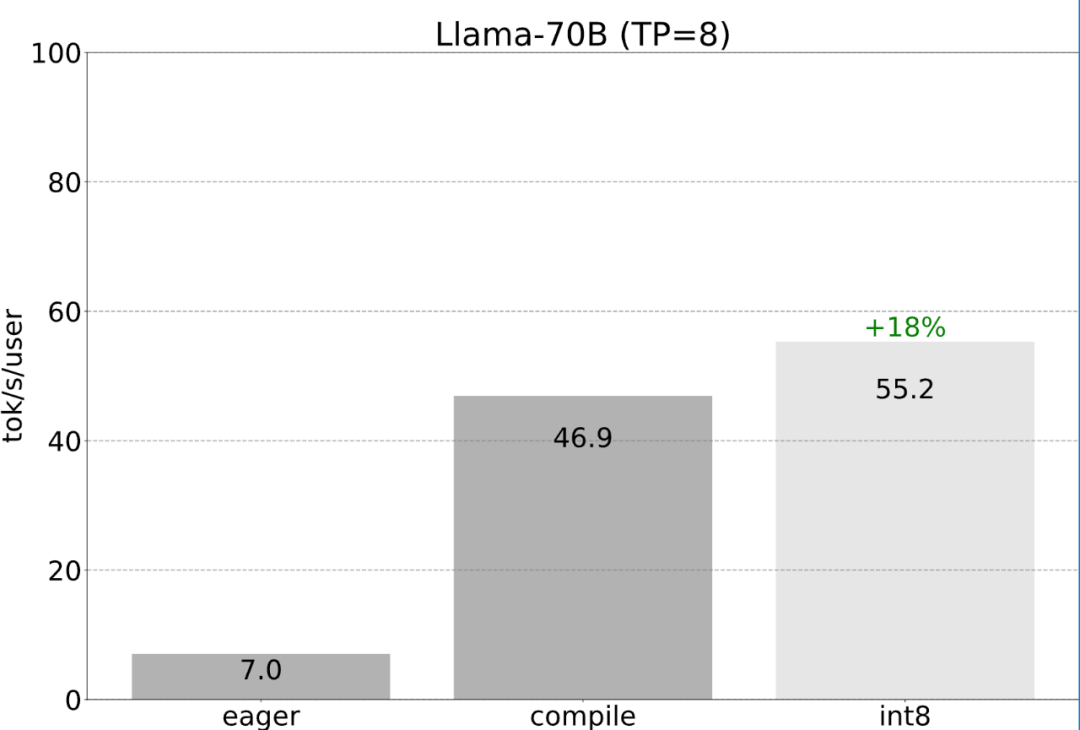
最后,简单总结一下文章主要内容。在 Llama-7B 上,本文使用「compile + int4 quant + speculative decoding」这一套组合拳,实现 240+ tok/s。在 Llama-70B,本文还通过引入张量并行性以达到约 80 tok/s,这些都接近或超过 SOTA 性能。原文链接:https://pytorch.org/blog/accelerating-generative-ai-2/




































