







康奈尔大学与苹果最新研究得出结论:为了用更少的算力生成高分辨率图像,可以不使用注意力机制
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
众所周知,注意力机制是 Transformer 架构的核心组件,对于高质量的文本、图像生成都至关重要。但它的缺陷也很明显,即计算复杂度会随着序列长度的增加呈现二次方增长。这在长文本、高分辨率的图像处理中都是一个令人头疼的问题。
为了解决这个问题,这项新研究用一个可扩展性更强的状态空间模型(SSM)主干替代了传统架构中的注意力机制,开发出了一个名为 Diffusion State Space Model(DIFFUSSM)的新架构。这种新架构可以使用更少的算力,媲美或超越具有注意力模块的现有扩散模型的图像生成效果,出色地生成高分辨率图像。

得益于上周「Mamba」的发布,状态空间模型 SSM 正受到越来越多的关注。Mamba 的核心在于引入了一种新的架构 ——「选择性状态空间模型( selective state space model)」,这使得 Mamba 在语言建模方面可以媲美甚至击败 Transformer。当时,论文作者 Albert Gu 表示,Mamba 的成功让他对 SSM 的未来充满了信心。如今,康奈尔大学和苹果的这篇论文似乎又给 SSM 的应用前景增加了新的例证。
微软首席研究工程师 Shital Shah 提醒说,注意力机制可能要从坐了很久的王座上被拉下来了。
论文概览
图像生成领域的迅速进展得益于去噪扩散概率模型(DDPMs)。这类模型将生成过程建模为迭代去噪潜变量,当执行足够的去噪步骤时,它们能够产生高保真度的样本。DDPMs 捕捉复杂视觉分布的能力使其在推动高分辨率、照片级合成方面具有潜在的优势。
在将 DDPMs 扩展到更高分辨率方面仍然存在重要的计算挑战。主要瓶颈是在实现高保真生成时依赖自注意力。在 U-Nets 架构中,这个瓶颈来自将 ResNet 与注意力层相结合。DDPMs 超越了生成对抗网络 (GANs),但需要多头注意力层。在 Transformer 架构中,注意力是中心组件,因此对于实现最新的图像合成结果至关重要。在这两种架构中,注意力的复杂性,与序列长度成二次方关系,所以当处理高分辨率图像时将变得不可行。
计算成本促使以往的研究者们使用表示压缩方法。高分辨率架构通常采用分块化(patchifying)或多尺度分辨率。通过分块化可以创建粗粒度表示,降低计算成本,但代价是牺牲关键的高频空间信息和结构完整性。多尺度分辨率虽然可以减少注意层的计算,但也会通过降采样减少空间细节并在应用上采样时引入伪影。
DIFFUSSM是一种扩散状态空间模型,它不使用注意力机制,旨在解决在高分辨率图像合成中应用注意力机制时遇到的问题。DIFFUSSM在扩散过程中采用了门控状态空间模型(SSM)。先前的研究表明,基于SSM的序列模型是一种有效且高效的通用神经序列模型。通过采用这种架构,可以使SSM核心处理更细粒度的图像表示,消除全局分块化或多尺度层。为了进一步提高效率,DIFFUSSM在网络的密集组件中采用了沙漏架构
作者在不同分辨率下验证了 DIFFUSSM 的性能。在 ImageNet 上的实验证明,在各种分辨率下,DIFFUSSM 在 FID、sFID 和 Inception Score 上都取得了一致的改进,并且总 Gflops 更少。

论文链接:https://arxiv.org/pdf/2311.18257.pdf
DIFFUSSM 框架
为了不改变原意,需要将内容改写成中文。 作者的目标是设计一种能够在高分辨率下学习长程相互作用的扩散架构,而不需要像分块化那样进行“长度缩减”。与DiT类似,这种方法通过将图像展平并将其视为序列建模问题来实现。然而,与Transformer不同的是,该方法在处理这个序列的长度时采用了次二次(sub-quadratic)计算
DIFFUSSM是一个优化处理长序列的门控双向SSM的核心组件。为了提高效率,作者在MLP层引入了沙漏架构。这种设计在双向SSM周围交替扩展和收缩序列长度,同时在MLP中有选择地减少序列长度。完整的模型架构如图2所示
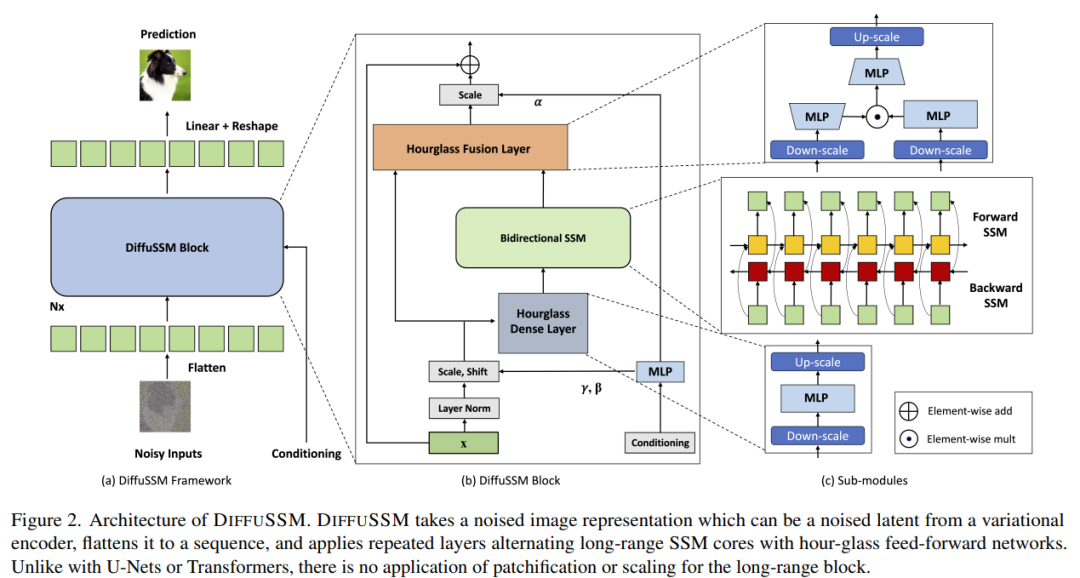
具体来说,每个沙漏层接收经过缩短并展平的输入序列 I ∈ R^(J×D),其中 M = L/J 是缩小和放大的比例。同时,整个块,包括双向 SSM,在原始长度上进行计算,充分利用全局上下文。文中使用 σ 表示激活函数。对于 l ∈ {1 . . . L},其中 j = ⌊l/M⌋,m = l mod M,D_m = 2D/M,计算方程如下所示:
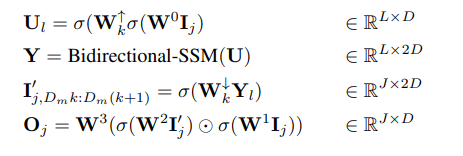
作者在每个层中使用跳跃连接集成门控 SSM 块。作者在每个位置集成了类标签 y ∈ R^(L×1) 和时间步 t ∈ R^(L×1) 的组合,如图 2 所示。
参数:DIFFUSSM 块中参数的数量主要由线性变换 W 决定,其中包含 9D^2 + 2MD^2 个参数。当 M = 2 时,这产生了 13D^2 个参数。DiT 变换块在其核心变换层中有 12D^2 个参数;然而,DiT 架构在其他层组件(自适应层归一化)中具有更多的参数。研究者在实验中通过使用额外的 DIFFUSSM 层来匹配参数。
FLOPs:图 3 比较了 DiT 和 DIFFUSSM 之间的 Gflops。DIFFUSSM 一层的总 Flops 为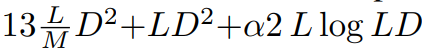 ,其中 α 代表 FFT 实现的常数。当 M = 2 且线性层主导计算时,这大约产生 7.5LD^2 Gflops。相比之下,如果在这个沙漏架构中使用全长的自注意力而不是 SSM,会有额外的 2DL^2 Flops。
,其中 α 代表 FFT 实现的常数。当 M = 2 且线性层主导计算时,这大约产生 7.5LD^2 Gflops。相比之下,如果在这个沙漏架构中使用全长的自注意力而不是 SSM,会有额外的 2DL^2 Flops。
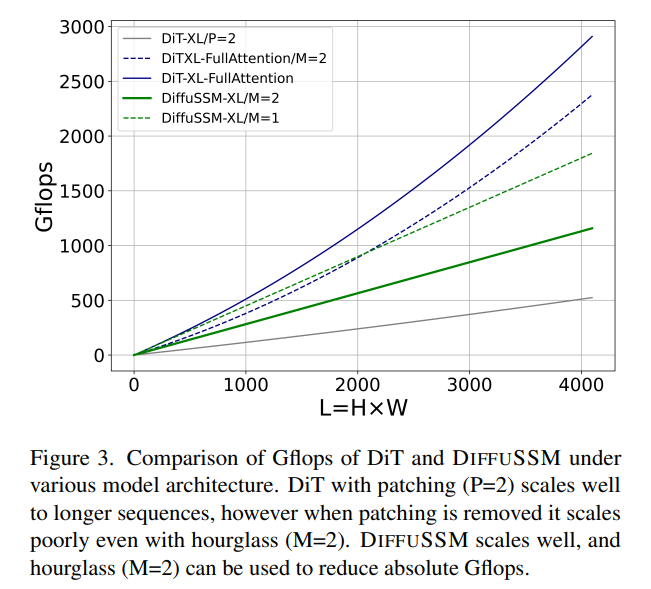
考虑两种实验场景:1) D ≈ L = 1024,这将带来额外的 2LD^2 Flops,2) 4D ≈ L = 4096,这将产生 8LD^2 Flops 并显著增加成本。由于双向 SSM 的核心成本相对于使用注意力的成本较小,因此使用沙漏架构对基于注意力的模型不起作用。正如前面讨论的,DiT 通过使用分块化来避免这些问题,以代价是压缩表示。
实验结果
生成类别条件图像
下表是DIFFUSSM与目前所有最先进的类别条件生成模型的比较结果
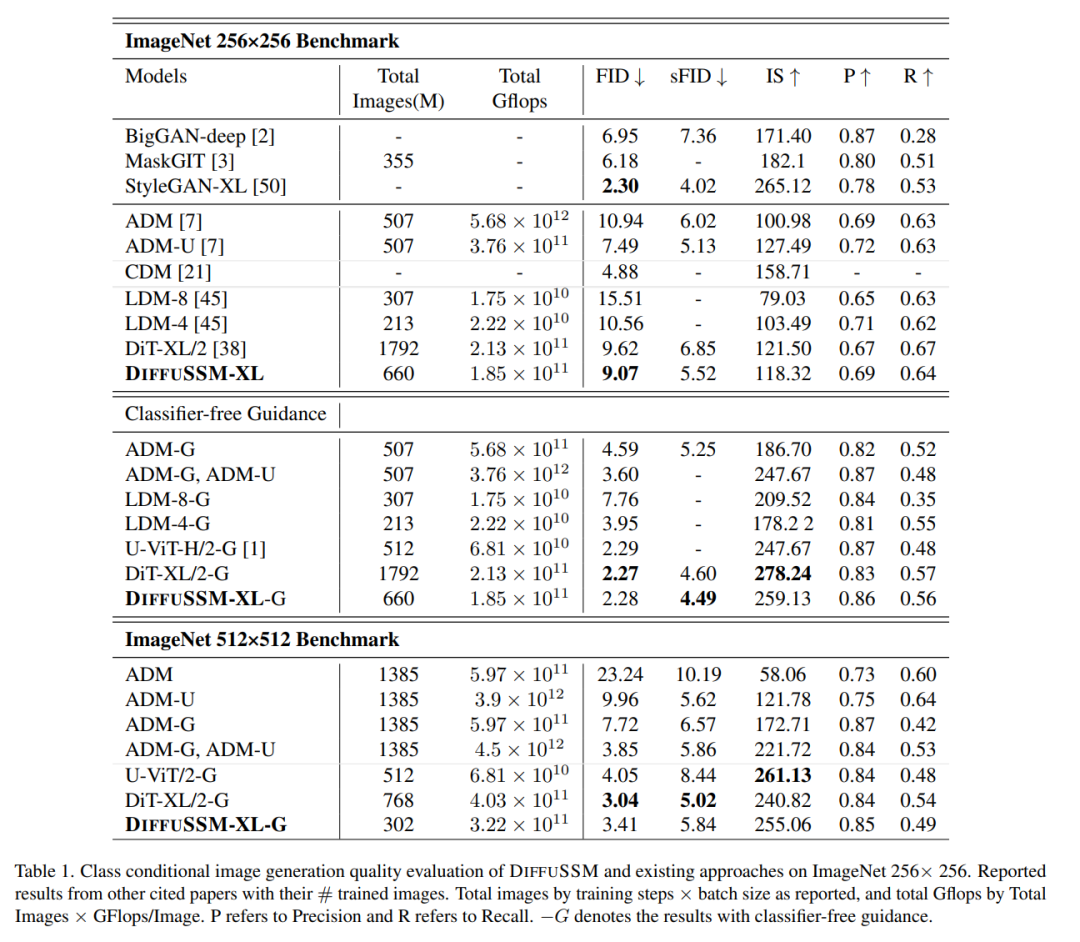
当没有使用无分类器指导时,DIFFUSSM 在 FID 和 sFID 两方面均优于其他扩散模型,将之前非无分类器指导潜在扩散模型的最佳分数从 9.62 降至 9.07,同时使用的训练步骤减少到原来的 1/3 左右。在训练的总 Gflops 方面,未压缩模型相较于 DiT 减少了 20% 的总 Gflops。当引入无分类器指导时,模型在所有基于 DDPM 的模型中获得了最佳的 sFID 分数,超过了其他最先进的策略,表明 DIFFUSSM 生成的图像对于空间失真更具鲁棒性。
DIFFUSSM 在使用无分类器指导时的 FID 分数超越了所有模型,并在与 DiT 相比时保持了相当小的差距(0.01)。需要注意的是,在没有应用无分类器指导的情况下,以减少 30% 的总 Gflops 训练的 DIFFUSSM 已经超过了 DiT。U-ViT 是另一种基于 Transformer 的架构,但采用了基于 UNet 的架构,块之间有长跳连接。U-ViT 在 256×256 分辨率下使用较少的 FLOPs,并在性能上表现更好,但在 512×512 数据集中情况并非如此。作者主要与 DiT 进行比较,为了公平,没有采用这种长跳连接,作者认为采用 U-Vit 的思想可能对 DiT 和 DIFFUSSM 都有益处。
作者进一步在更高分辨率的基准上使用无分类器指导进行比较。DIFFUSSM的结果相对强劲,并接近最先进的高分辨率模型,仅在sFID上不及DiT,并获得了可比较的FID分数。DIFFUSSM在3.02亿张图像上进行了训练,观察了40%的图像,使用的Gflops比DiT少了25%
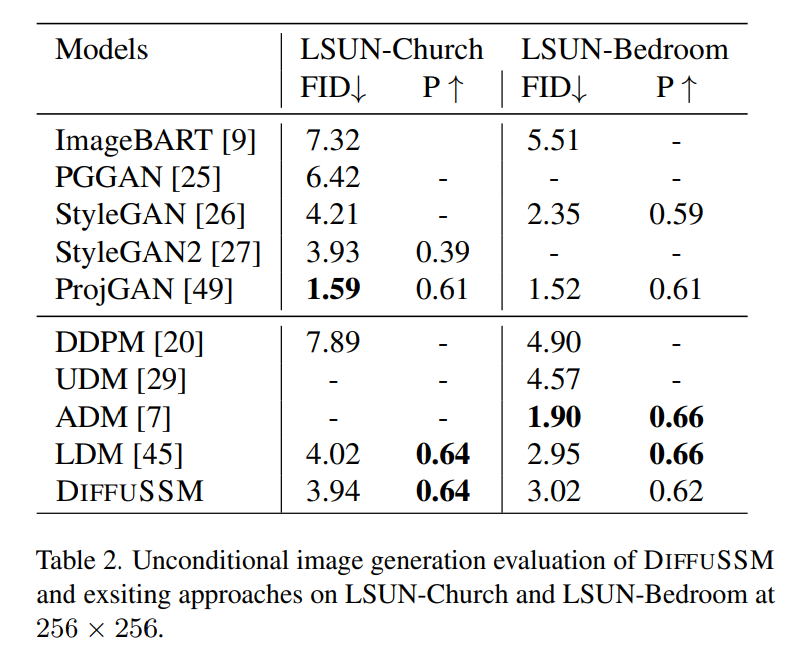
无条件图像生成

根据作者对模型的无条件图像生成能力进行比较的结果显示在表2中。作者的研究发现,在与LDM相当的训练预算下,DIFFUSSM取得了可比较的FID分数(差距为-0.08和0.07)。这个结果突显了DIFFUSSM在不同基准和不同任务中的适用性。与LDM类似,由于只使用ADM总训练预算的25%,因此在LSUN-Bedrooms任务中,该方法并未超过ADM。对于这个任务,最佳GAN模型在模型类别上胜过扩散模型
请查阅原论文获取更多详细内容





























