过去几年里,YOLOs因在计算成本和检测性能之间实现有效平衡而成为实时目标检测领域的主流范式。研究人员针对YOLOs的结构设计、优化目标、数据增强策略等进行了深入探索,并取得了显著进展。然而,对非极大值抑制(NMS)的后处理依赖阻碍了YOLOs的端到端部署,并对推理延迟产生负面影响。此外,YOLOs中各种组件的设计缺乏全面和彻底的审查,导致明显的计算冗余并限制了模型的性能。这导致次优的效率,以及性能提升的巨大潜力。在这项工作中,我们旨在从后处理和模型架构两个方面进一步推进YOLOs的性能-效率边界。为此,我们首先提出了用于YOLOs无NMS训练的持续双重分配,该方法同时带来了竞争性的性能和较低的推理延迟。此外,我们为YOLOs引入了全面的效率-准确性驱动模型设计策略。我们从效率和准确性两个角度全面优化了YOLOs的各个组件,这大大降低了计算开销并增强了模型能力。我们的努力成果是新一代YOLO系列,专为实时端到端目标检测而设计,名为YOLOv10。广泛的实验表明,YOLOv10在各种模型规模下均达到了最先进的性能和效率。例如,在COCO数据集上,我们的YOLOv10-S在相似AP下比RT-DETR-R18快1.8倍,同时参数和浮点运算量(FLOPs)减少了2.8倍。与YOLOv9-C相比,YOLOv10-B在相同性能下延迟减少了46%,参数减少了25%。代码链接:https://github.com/THU-MIG/yolov10。
YOLOv10有哪些改进?
首先通过为无NMS的YOLOs提出一种持续双重分配策略来解决后处理中的冗余预测问题。该策略包括括双重标签分配和一致匹配度量。这使得模型在训练过程中能够够获得丰富而和谐的监督,同时消除了推理过程中对NMS的需求,从而在保持高效率的同时获得了竞争性的性能。
此次,为模型架构提出了全面的效率-准确度驱动模型设计策略,对YOLOs中的各个组件进行了全面检查。在效率方面,提出了轻量级分类头、空间-通道解耦下采样和rank引导block设计,以减少明显的计算冗余并实现更高效的架构。
在准确度方面,探索了大核卷积并提出了有效的部分自注意力模块,以增强模型能力,以低成本挖掘性能提升潜力。
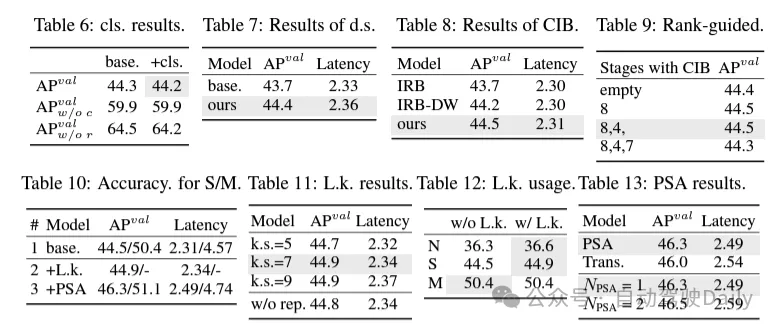
基于这些方法,作者成功地实现了一系列不同模型规模的实时端到端检测器,即YOLOv10-N / S / M / B / L / X。在标准目标检测基准上进行的广泛实验表明,YOLOv10在各种模型规模下,在计算-准确度权衡方面显示出了优于先前的最先进模型的能力。如图1所示,在类似性能下,YOLOv10-S / X分别比RT-DETR R18 / R101快1.8倍/1.3倍。与YOLOv9-C相比,YOLOv10-B在相同性能下实现了46%的延迟降低。此外,YOLOv10展现出了极高的参数利用效率。YOLOv10-L / X在参 数数量分别减少了1.8倍和2.3倍的情况下,比YOLOv8-L / X高出0.3 AP和0.5 AP。YOLOv10-M在参数数量分别减少了23%和31%的情况下,与YOLOv9-M / YOLO-MS实现了相似的AP。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
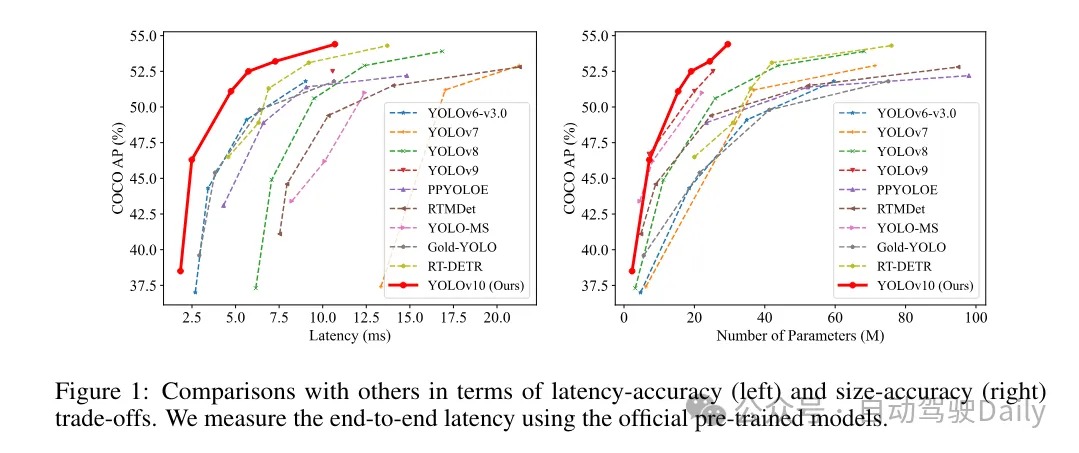
在训练过程中,YOLOs通常利用TAL(任务分配学习)为每个实例分配多个样本。采用一对多的分配方式产生了丰富的监督信号,有助于优化并实现更强的性能。然而,这也使得YOLOs必须依赖NMS(非极大值抑制)后处理,这导致在部署时的推理效率不是最优的。虽然之前的工作探索了一对一的匹配方式来抑制冗余预测,但它们通常会增加额外的推理开销或导致次优的性能。 在这项工作中,我们提出了一种无需NMS的训练策略,该策略采用双重标签分配和一致匹配度量,实现了高效率和具有竞争力的性能。通过该策略,我们的YOLOs在训练中不再需要NMS,从而实现了高效率和具有竞争力的性能。
效率驱动的模型设计。YOLO中的组件包括主干(stem)、下采样层、带有基本构建块的阶段和头部。主干部分的计算成本很低,因此我们对其他三个部分进行效率驱动的模型设计。
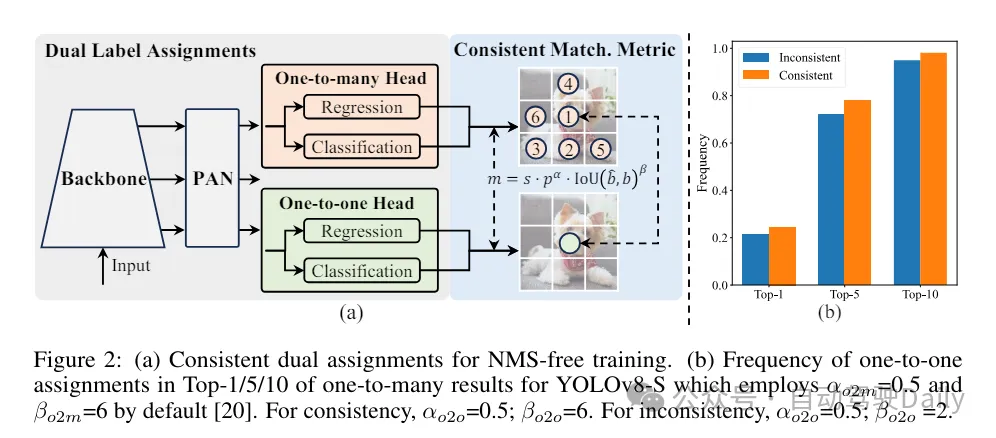
(1)轻量级的分类头。在YOLO中,分类头和回归头通常有相同的架构。然而,它们在计算开销上存在显著的差异。例如,在YOLOv8-S中,分类头(5.95G/1.51M的FLOPs和参数数量)和回归头(2.34G/0.64M)的FLOPs和参数数量分别是回归头的2.5倍和2.4倍。然而,通过分析分析分类错误和回归错误的影响(见表6),我们发现回归头对YOLO的性能更为重要。因此,我们可以在不担心性能损害的情况下减少分类头的开销。因此,我们简单地采用了轻量级的分类头架构,它由两个深度可分离卷积组成,卷积核大小为3×3,后跟一个1×1的卷积核。 通过以上改进,我们可以简化轻量级的分类头的架构,它由两个深度可分离卷积组成,卷积核大小为3×3,后跟一个1×1的卷积核。这种简化的架构可以实现分类的功能,并且具有更小的计算开销和参数数量。
(2)空间-通道解耦下采样。YOLO通常使用步长为2的常规3×3标准卷积,同时实现空间下采样(从H × W到H/2 × W/2)和通道变换(从C到2C)。这引入了不可忽视的计算成本 和参数计数。相反,我们提出将空间缩减和通道增加操作解耦,以实现更高效的下采样。具体来说,首先利用逐点卷积来调制通道维度,然后利用深度卷积进行空间下采样。这将计算成本降低到并将参数计数降低到。同时,它在下采样过程中最大限度地保留了信息,从而在降低延迟的同时保持了竞争性能。
(3)基于rank引导的模块设计。YOLOs通常对所有阶段都使用相同的基本构建块,例如YOLOv8中的bottleneck块。为了彻底检查YOLOs的这种同构设计,我们利用内在秩来分析每个阶段的冗余性。具体来说,计算每个阶段中最后一个基本块中最后一个卷积的数值秩,它计算大于阈值的奇异值的数量。图3(a)展示了YOLOv8的结果,表明深层阶段和大型模型更容易表现出更多的冗余性。这一观察表明,简单地对所有阶段应用相同的block设计对于实现最佳容量-效率权衡来说并不是最优的。为了解决这个问题,提出了一种基于秩的模块设计方案,旨在通过紧凑的架构设计来降低被证明是冗余的阶段的复杂性。
首先介绍了一种紧凑的倒置块(CIB)结构,它采用廉价的深度卷积进行空间混合和成本效益高的逐点卷积进行通道混合,如图3(b)所示。它可以作为有效的基本构建块,例如嵌入在ELAN结构中(图3(b))。然后,倡导一种基于秩的模块分配策略,以在保持竞争力量的同时实现最佳效率。具体来说,给定一个模型,根据其内在秩的升序对所有阶段进行排序。进一步检查用CIB替换领先阶段的基本块后的性能变化。如果与给定模型相比没有性能下降,我们将继续替换下一个阶段,否则停止该过程。因此,我们可以在不同阶段和模型规模上实现自适应紧凑块设计,从而在不影响性能的情况下实现更高的效率。
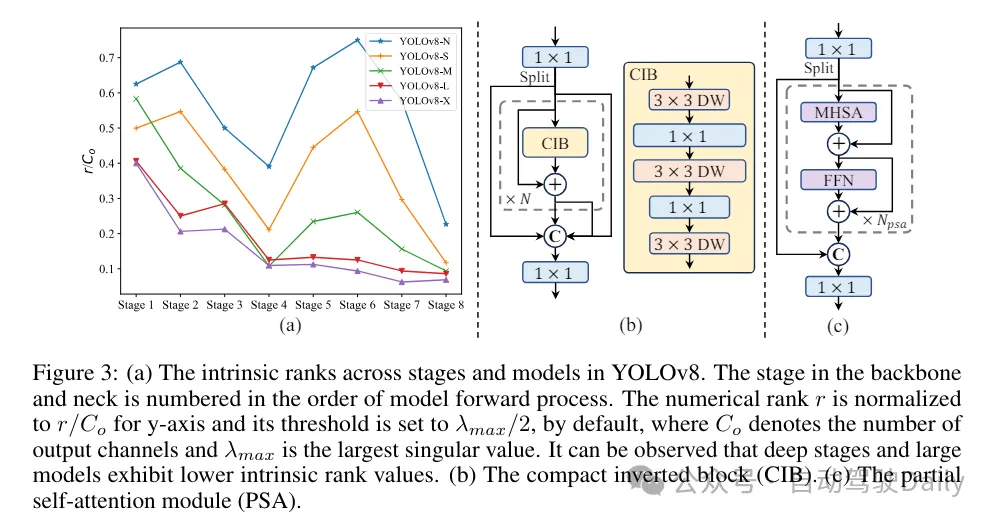
基于精度导向的模型设计。论文进一步探索了大核卷积和自注意力机制,以实现基于精度的设计,旨在以最小的成本提升性能。
(1)大核卷积。采用大核深度卷积是扩大感受野并增强模型能力的一种有效方法。然而,在所有阶段简单地利用它们可能会在用于检测小目标的浅层特征中引入污染,同时也在高分辨率阶段引入显著的I/O开销和延迟。因此,作者提出在深层阶段的跨阶段信息块(CIB)中利用大核深度卷积。这里将CIB中的第二个3×3深度卷积的核大小增加到7×7。此外,采用结构重参数化技术,引入另一个3×3深度卷积分支,以缓解优化问题,而不增加推理开销。此外,随着模型大小的增加,其感受野自然扩大,使用大核卷积的好处逐渐减弱。因此,仅在小模型规模上采用大核卷积。
(2)部分自注意力(PSA)。自注意力机制因其出色的全局建模能力而被广泛应用于各种视觉任务中。然而,它表现出高计算复杂度和内存占用。为了解决这个问题,鉴于普遍存在的注意力头冗余,作则提出了一种高效的部分自注意力(PSA)模块设计,如图3.(c)所示。具体来说,在1×1卷积之后将特征均匀地按通道分成两部分。只将一部分特征输入到由多头自注意力模块(MHSA)和前馈网络(FFN)组成的NPSA块中。然后,将两部分特征通过1×1卷积进行拼接和融合。此外,将MHSA中查询和键的维度设置为值的一半,并将LayerNorm替换为BatchNorm以实现快速推理。PSA仅放置在具有最低分辨率的第4阶段之后,以避免自注意力的二次计算复杂度带来的过多开销。通过这种方式,可以在计算成本较低的情况下将全局表示学习能力融入YOLOs中,从而很好地增强了模型的能力并提高了性能。
实验对比
这里就不做过多介绍啦,直接上结果!!!latency减少,性能继续增加。