







☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

虽然大规模语言模型(LLM)在许多自然语言处理任务中表现优异,但在具体任务中的效果却不尽如人意。为了提升模型在特定自然语言任务上的表现,现有的方法主要依赖于高质量的人工标注数据。这类数据的收集过程既耗时又费力,对于数据稀缺的任务尤为困难。
为了解决这个问题,一些研究尝试通过强大的 Teacher Model 生成训练数据,来增强 Student Model 在特定任务上的性能。然而,这种方法在成本、可扩展性和法律合规性方面仍面临诸多挑战。在无法持续获得高质量人类监督信号的情况下,如何持续迭代模型的能力,成为了亟待解决的问题。
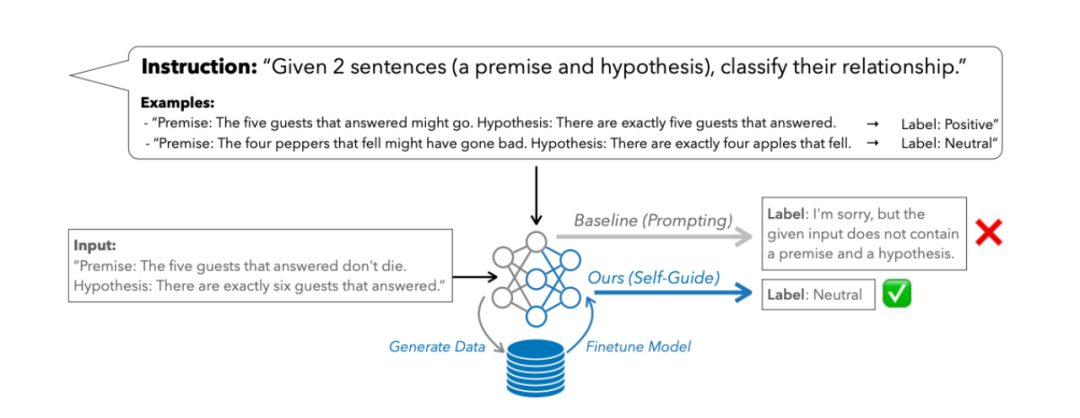
来自卡内基梅隆大学和清华大学的研究团队提出了 SELF-GUIDE 方法。该方法通过语言模型自身生成任务特定的数据集,并在该数据集上进行微调,从而显著提升模型在特定任务上的能力,无需依赖大量外部高质量数据或更强大的 Teacher Model。具体来说,在外部输入大约 3 个样例的情况下,SELF-GUIDE 采用多阶段的生成和过滤机制,利用模型生成的合成数据进行微调,使模型在特定任务上的表现更加出色。

方法
具体来说,研究团队将 SELF-GUIDE 方法分解为三个主要阶段:输入数据生成、输出数据生成和质量优化。
输入数据生成
在 SELF-GUIDE 框架的设计和实现过程中,研究者首先根据任务类型(生成型任务或分类型任务)指定不同的提示模板。对于生成型任务,SELF-GUIDE 框架使用一个相对简单的提示模板。而对于分类型任务,SELF-GUIDE 框架则采用了另一种策略。对于分类任务,SELF-GUIDE 框架首先从全部标签空间中随机选择一个标签,将其作为条件生成的伪标签,指导输入数据的生成。选定伪标签后,SELF-GUIDE 框架使用较为复杂的条件生成模板,引导模型生成与所选伪标签相对应的输入内容。

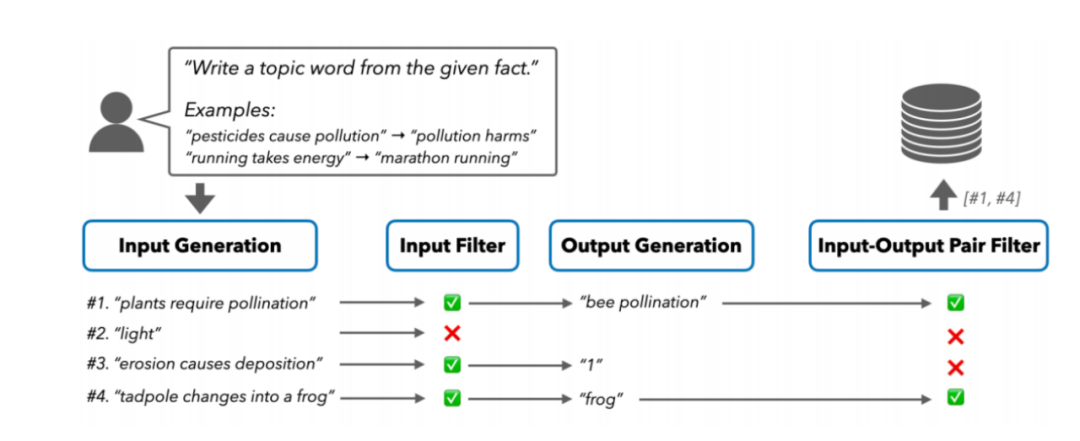
选定模板并填充示例(few-shot examples)后,完整的提示被传递给 LLM,以生成输入数据。每轮提示后,新生成的输入会被添加到输入库中。从这个库中随机抽取一部分输入,并与初始示例中的输入合并,形成新的提示,逐步扩展 LLM 生成的输入集并且减少重复。SELF-GUIDE 仅进行一轮输入生成,随后在质量优化阶段,应用基于规则的过滤器来去除低质量的输入。
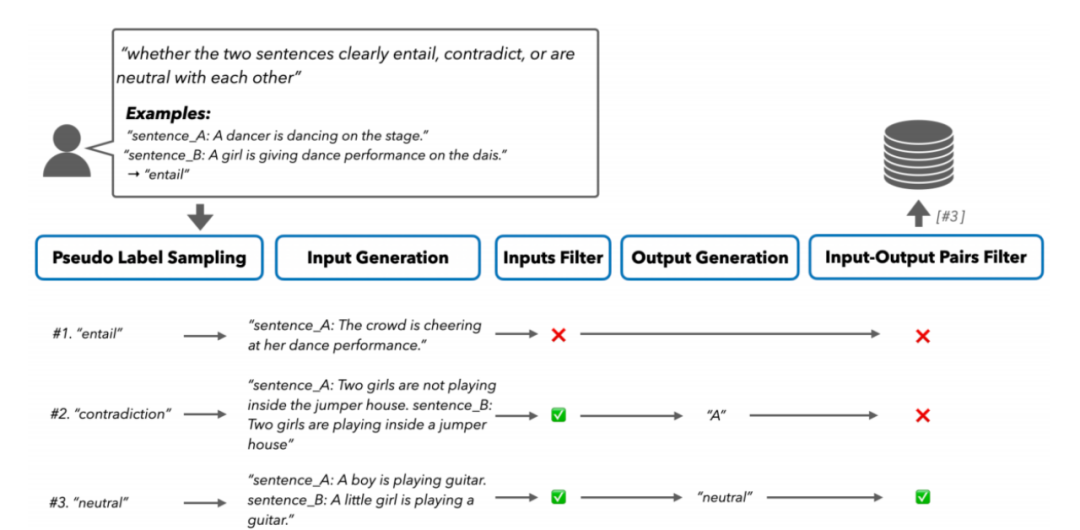
图 3:此图描述了 SELF-GUIDE 完成分类任务的过程。对于分类任务的数据,SELF-GUIDE 首先生成伪标签,然后生成对应的输入,最后重新生成真实标签。
输出数据生成
输出数据生成阶段采用了典型的上下文学习方法:研究者向模型提供任务指令和原始示例,使模型对输入生成阶段产生的每一个输入进行标注。在获取所有输出后,再进行一轮基于规则的过滤,以选择最终的合成数据集。
质量优化
生成数据的质量对于下游训练的成功至关重要。SELF-GUIDE 采用了两种策略来提高质量:调整生成参数以提高生成质量并基于规则过滤掉低质量样本。
调整温度:调整温度是一种平衡多样性和质量的常见策略。SELF-GUIDE 框架在输入生成阶段使用较高的温度以鼓励多样性,在其他阶段通过使用较低的温度确保得到概率最高的输出,从而保证整体数据质量。然而,仅依靠温度调整不足以实现所需的平衡。因此, SELF-GUIDE 还在输入生成后和输出注释后分别进行了两轮基于规则的数据过滤。
噪声过滤(Noise Filter):研究者手动整理了一份噪声术语列表,包括常见的问候语和噪声字符(例如,生成内容中的”\”)。如果生成示例的输入或输出中出现了任何来自这份列表的噪声术语, SELF-GUIDE 将丢弃整个示例。
长度过滤(Length Filter):虽然示例的长度可能存在偏差,但是研究者认为这些示例在特定任务的长度分布方面仍然具有代表性。SELF-GUIDE 假设示例的长度遵循正态分布,并计算出输入样例的均值 μ 和标准差 σ,研究者假定生成示例的输入和输出长度应符合同一正态分布,并要求长度在 (μ − 2σ, μ + 2σ) 范围内。
整体参数微调(One Parameter Fits All):为了使 SELF-GUIDE 生成符合指令和示例指定目标分布的训练数据,需要在标注数据点上优化各种超参数,包括生成输入输出的个数、输入数据生成的温度、输出数据生成的温度、微调参数等。研究者将实验测试任务分为两部分:一部分可以利用所有数据进行验证以调整生成参数,称为验证任务;另一部分的数据仅用于测试而不可用于调整参数,称为测试任务。研究者在验证任务上搜索 “最大化最差任务性能” 的参数,并将其固定用于测评 SELF-GUIDE 在测试任务上的表现。
实验结果
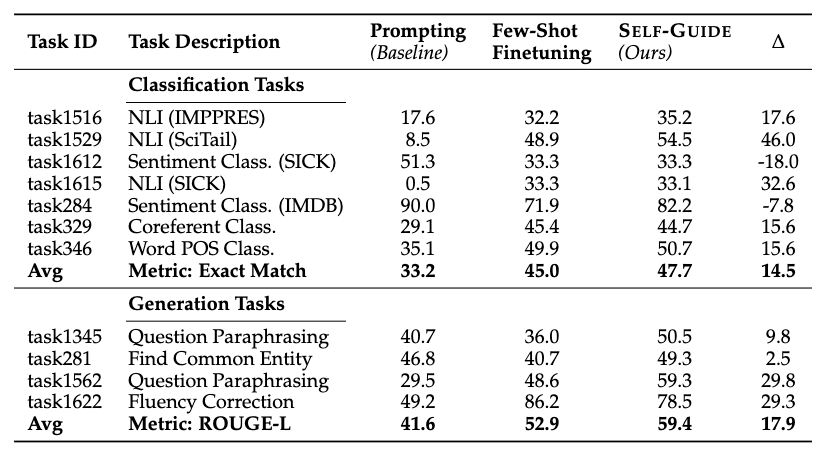
为了评估 SELF-GUIDE 的有效性,研究者从 Super-NaturalInstructions V2 基准中选择了 14 个分类任务和 8 个生成任务。研究者随机选择了一半任务用于超参数搜索,剩余的一半用于评估。在模型方面,研究者选择了 Vicuna-7b-1.5 作为输入生成、输出生成和微调的基础模型。在评估指标方面,研究者采用了与 Super-NaturalInstructions 基准相同的评估指标,即分类任务的 Exact Match 和生成任务的 ROUGE-L。
为了体现 SELF-GUIDE 的效果,研究者将 SELF-GUIDE 与其他指令跟随和上下文学习方法进行了比较:
1.Few-Shot ICL:作为主要基准,研究者与直接提示语言模型进行了比较。这种方法直接依赖于模型固有的指令跟随能力。
2.Self-ICL:Self-ICL 使用自生成的示例来提高零样本指令跟随。研究者在 Self-ICL 工作的基础上进行了修改,通过自生成尽可能多的示例(而不是固定个数的示例)填充提示词,从而增加参考样本数目。
3.Few-Shot Finetuning:直接利用输入的少量示例进行微调。
SELF-GUIDE 原文主要实验结果如下所示。在基准的评估指标上,分类任务的绝对提升达到了 14.5%,而生成任务的绝对提升则达到了 17.9%。这些结果表明, SELF-GUIDE 在指导 LLM 向任务特定专业化方向发展方面具有显著效果,即使在数据极其有限的情况下。这突显了自我生成数据在大规模适应 LLM 到特定任务中的潜力。更多实验结果和消融实验请参考论文原文。
总结
SELF-GUIDE 框架鼓励模型自主生成训练数据并在此数据上进行微调。实验结果表明,这种方法在提升大规模语言模型特定任务的专业能力方面具有巨大潜力,尤其是在数据有限的情况下,SELF-GUIDE 可以有效解决缺少训练数据的问题。同时,这也为探索自主模型适应和持续学习的技术提供了参考。研究者希望这一工作能够推动 AI 系统在自主对齐和改进机制方面的发展,使其更加符合人类的意图。





























