







scrapy是一个python网络爬虫框架,用于从网站提取数据。它可以通过自动访问和解析网页来实现,并易于定制和扩展。scrapy的基本组成部分包括:项目:scrapy项目包含爬虫和提取数据的设置。蜘蛛:负责从网页中提取数据的组件。解析器:提取网页数据并存储到item中的组件。

Scrapy爬虫框架使用教程
什么是Scrapy?
Scrapy是一个强大的Python框架,用于从网站提取数据,也被称为网络爬虫。它通过自动访问和解析网页来实现,并易于定制和扩展。
安装Scrapy
- 安装Python 3.6或更高版本。
- 使用pip安装Scrapy:
pip install scrapy
创建一个项目
- 创建一个新的目录,作为项目的根目录。
- 使用Scrapy命令行创建一个项目:
scrapy startproject myproject
创建一个蜘蛛
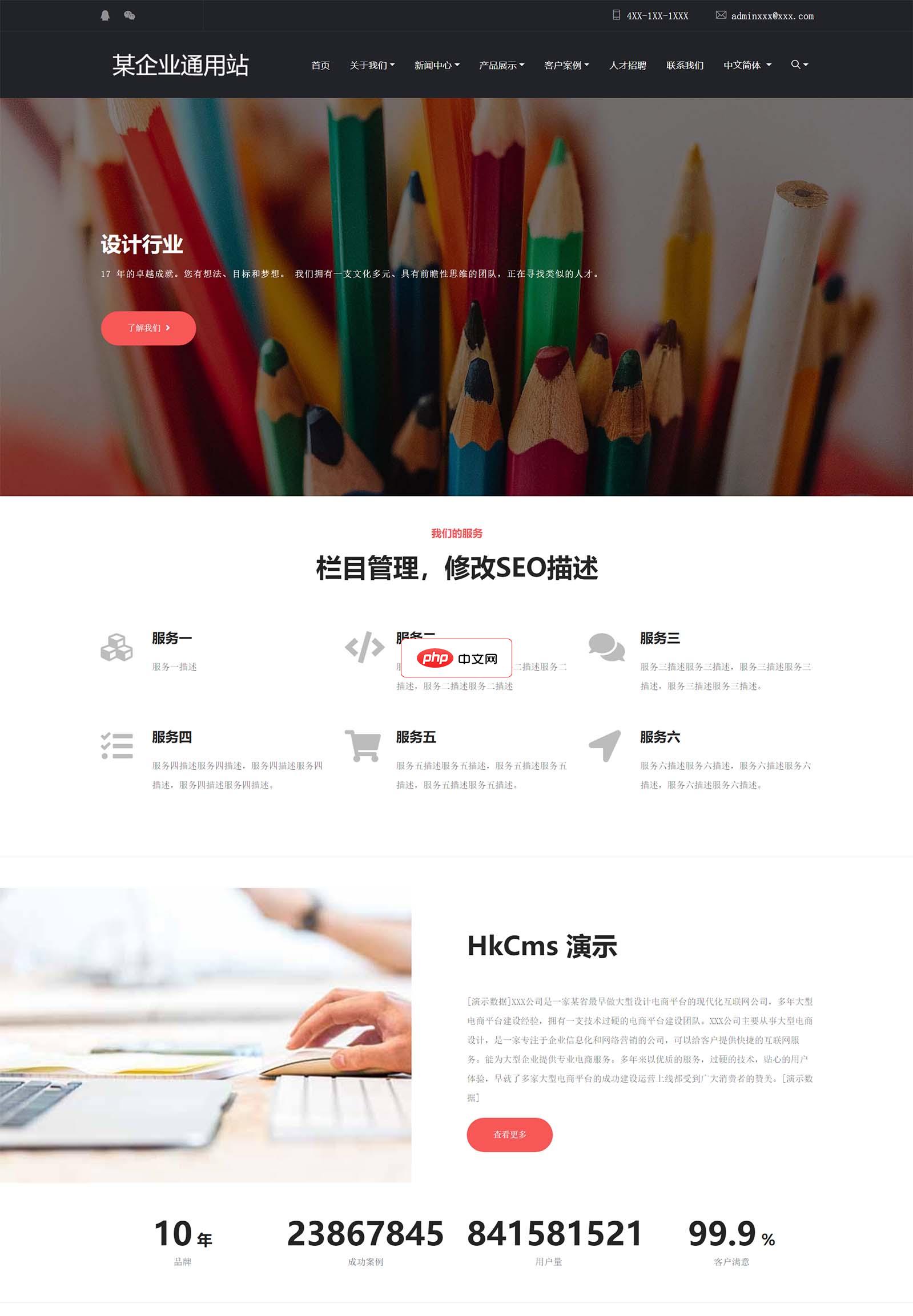
免费红色响应式多语言企业通用模板1.0.0
下载
该模板源码有公司简介、公司新闻、产品展示、客户案例、留言等企业官网常用页面功能。模板是响应式模板,支持多语言,完善的标签调用修改起来很方便。功能特点:1. 使用的框架采用HkCms开源内容管理系统v2.2.3版本、免费可以商用。2. 所需环境Apache/Nginx,PHP7.2 及以上 + MySQL 5.6 及以上。3. 安装教程: (1) 站点运行路径填写到public目录下。 (2) 浏览
蜘蛛是负责从网页中提取数据的Scrapy组件。
- 在项目目录中创建一个新的Python文件,例如
myspider.py。 - 从
scrapy.spiders导入scrapy.Spider类。 - 定义一个派生自
Spider类的子类,并指定爬取的域:
<code class="python">import scrapy
class MySpider(scrapy.Spider):
name = 'my_spider'
allowed_domains = ['example.com']
start_urls = ['https://example.com/']</code>解析器
解析器是提取网页数据并存储到Item中的组件。
- 覆盖
parse()方法,并在其中指定如何解析网页:
<code class="python">def parse(self, response):
# 从响应中提取数据,并将其存储到Item中
item = MyItem()
item['title'] = response.css('title::text').get()
return item</code>运行蜘蛛
- 从命令行进入项目根目录。
- 使用
scrapy crawl命令运行蜘蛛:scrapy crawl my_spider
其他功能
Scrapy还提供以下功能:
- 中间件:用于自定义请求和响应处理。
- 管道:用于在数据提取后处理数据。
- 扩展:用于扩展Scrapy的功能。



























