
譬如我想处理维基百科里边的第一个表格:
https://zh.wikipedia.org/wiki/%E6%96%87%E4%BB%B6%E7%BC%96%E8%BE%91%E5%99%A8%E6%AF%94%E8%BE%83
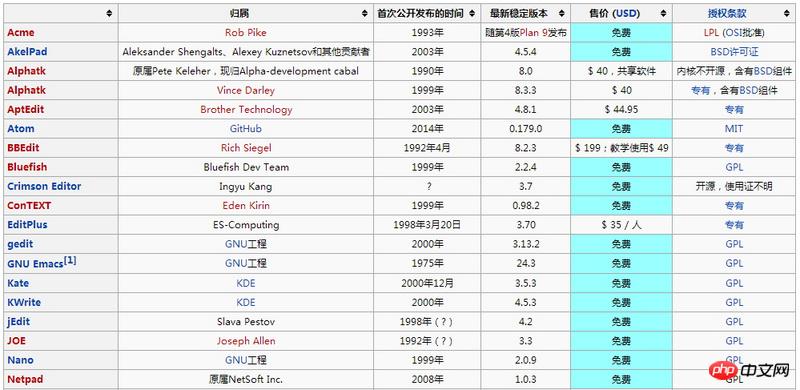
代码如下:
import urllib
import urllib2
import cookielib
import re
import csv
import codecs
from bs4 import BeautifulSoup
wiki = 'https://zh.wikipedia.org/wiki/%E6%96%87%E4%BB%B6%E7%BC%96%E8%BE%91%E5%99%A8%E6%AF%94%E8%BE%83'
header = {'User-Agent': 'Mozilla/5.0'}
req = urllib2.Request(wiki,headers=header)
page = urllib2.urlopen(req)
soup = BeautifulSoup(page)
name = "" #名字
creater = "" #归属
first = "" #首次公开发布的时间
latest = "" #最新稳定版本
cost = "" #售价
licence = "" #授权条款
table = soup.find("table", {"class" : "sortable wikitable"})
f = open('table.csv', 'w')
for row in table.findAll("tr"):
cells = row.findAll("td")
if len(cells) == 4:
name = cells[0].find(text=True)
creater = cells[1].find(text=True)
first = cells[2].find(text=True)
latest = cells[3].find(text=True)
cost = cells[4].find(text=True)
licence = cells[5].find(text=True)
(1) 因为是仿造 https://adesquared.wordpress.com/2013/06/16/using-python-beautifulsoup-to-scrape-a-wikipedia-table/ 写的,所以这里的if len(cells) == 4是有什么作用呢?
(2) 请问接下来要怎么写入csv呢?
谢谢,麻烦大家了。



Copyright 2014-2026 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号


 1
1 497
497
















ringa_lee