
安卓游戏排行榜
上边的地址,是豌豆荚的游戏排行榜,我想爬取游戏列表的TOP100,我用的是requests和BeautifulSoup这两个库
代码如下:
import requests
from bs4 import BeautifulSoup as bs
URL = 'http://www.wandoujia.com/top/game'
re = requests.get(URL).text
soup = bs(re)
result = soup.find_all('a','name')
for i in result:
print(i.text)输出的结果是正确的,但是,如下图所示
只能够读取到玩玩四川麻将这个游戏这,需要点击查看更多才能显示出来的游戏,并不能抓取到
于是,我就手动点击查看更多,让他展示出来剩下的游戏,然后保存成html文件,上述的代码改动一部分,读取本地的html来解析
soup = bs(open('D:\\game.html'))
结果发现,输出的内容中还是没有查看更多这个链接生成的那些,于是,我用VS Code打开html文件,发现查看更多这部分的内容是这样的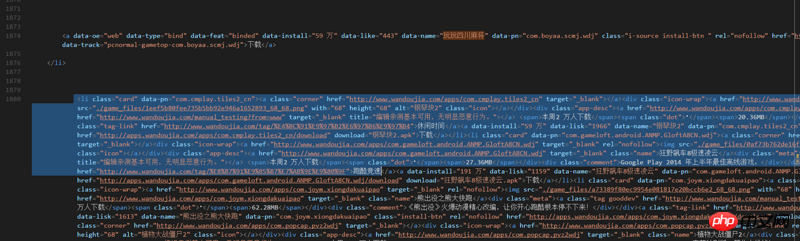
查看更多生成的内容格式跟原来的完全不一样,他们就在一行,没有格式,所以这下我不知道应该怎么办了,所以求教这样该怎么办?



Copyright 2014-2026 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号


 6
6 465
465
















还有比抓ajax返回json 更好抓的页面吗???