
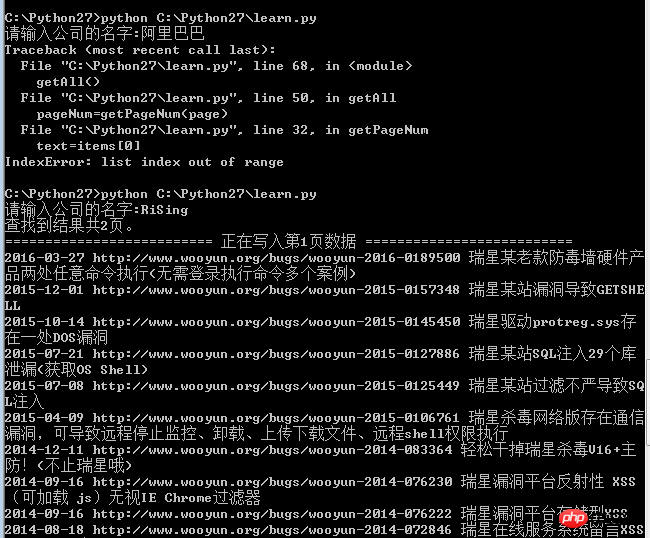
我写了一个爬乌云漏洞库的爬虫,其URL形式为http://www.wooyun.org/corps/公司名称/page/1,程序最后raw_input处输入公司名称即可跑出该公司的漏洞。现在的问题是中文编码的问题没解决好,如果公司的名称是英文如RiSing就可以,如果是中文就报错。求各位大大指点
# coding=utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import urllib
import urllib2
import re
def getPage(pageNum):
try:
url = 'http://www.wooyun.org/corps/' + corpName + '/page/' + str(pageNum)
request = urllib2.Request(url)
response = urllib2.urlopen(request)
return response.read().decode('utf-8')
except urllib2.URLError, e:
if hasattr(e,u"reason"):
print u"error",e.reason
return None
def getContent(page):
pattern = re.compile('.*?(.*?) .*?(.*?) ',re.S)
items = re.findall(pattern,page)
for item in items:
print item[0],'http://www.wooyun.org'+item[1],item[2]
def getPageNum(page):
pattern = re.compile('(.*?)(.*?)



Copyright 2014-2026 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号


 3
3 454
454 赞 +0
赞 +0

















业精于勤,荒于嬉;行成于思,毁于随。