在爬取
http://www.jyeoo.com/chinese/...
这个网页的内容的时候,我使用beautifulSoup解析网页内容
head = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'}
r = urllib2.Request('http://www.jyeoo.com/chinese/ques/detail/798530b2-05b0-4c11-9434-bb3f50c4c6f4',headers=head)
html = urllib2.urlopen(r)
soup = BeautifulSoup(html,'html5lib')
print soup.prettify()
这样打印出来的网页内容与原网页相比,某些字符丢失了!!这是原网页的html,注意其中的文字
这是我爬取的html,在同一个地方,我的截图如下:
可以发现,中文字符部分丢失了一些字,但是在页面的其他部分,就没有丢失,比如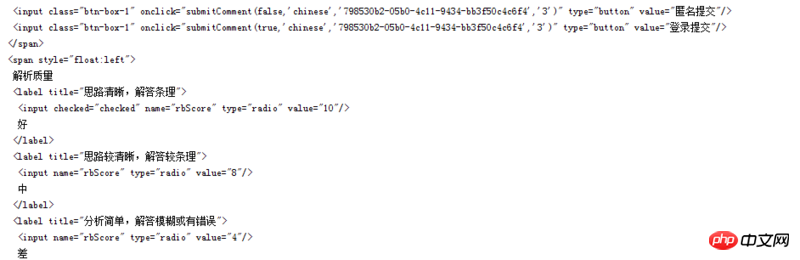
不知道是什么原因,有知道的大神还请帮忙解答一下!!!!多谢



Copyright 2014-2026 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号


 1
1 706
706















