







中科院院士鄂维南和字节跳动ai实验室总监李航联合推出先进的论文搜索agent——pasa。该系统模拟人类复杂学术搜索行为,由两个agent协同工作:一个负责多轮搜索,另一个负责判断论文是否符合查询要求。
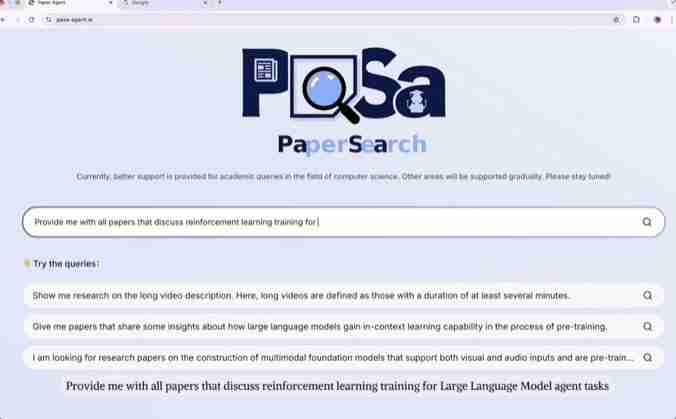
只需输入研究主题或想法,PaSa即可快速搜索并按相关性排序结果。
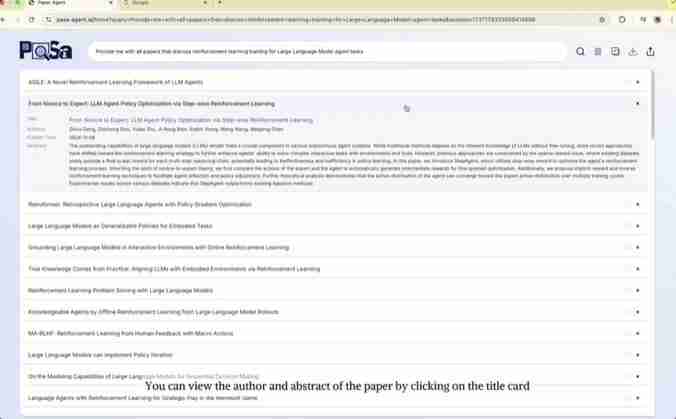
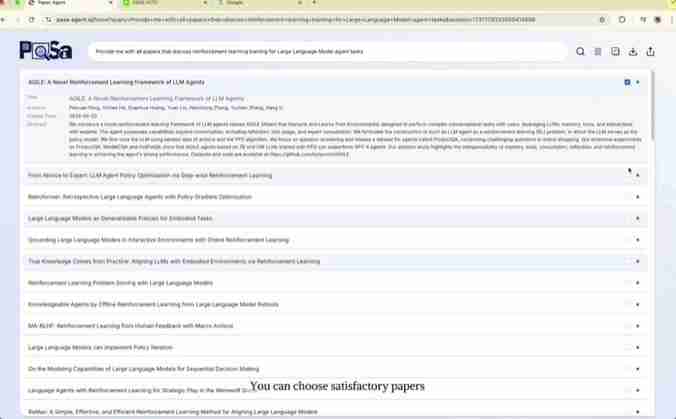
点击论文标题,即可直接查看作者和摘要;点击标题链接则可跳转至完整论文。
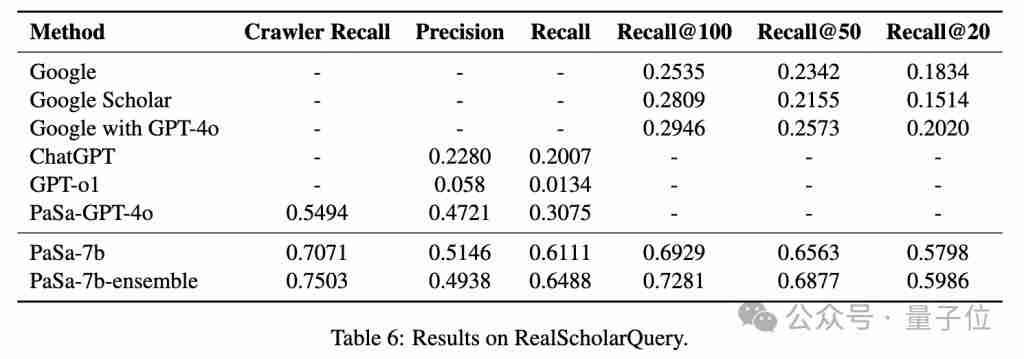
PaSa在召回率和准确率方面显著优于谷歌、谷歌学术、结合GPT-4o的谷歌搜索以及ChatGPT等现有模型。
PaSa的双Agent架构
现有学术搜索引擎(如谷歌学术)难以处理复杂的查询,导致研究人员耗费大量时间进行文献检索。PaSa系统由两个大型语言模型Agent构成:Crawler(爬虫)和Selector(选择器)。
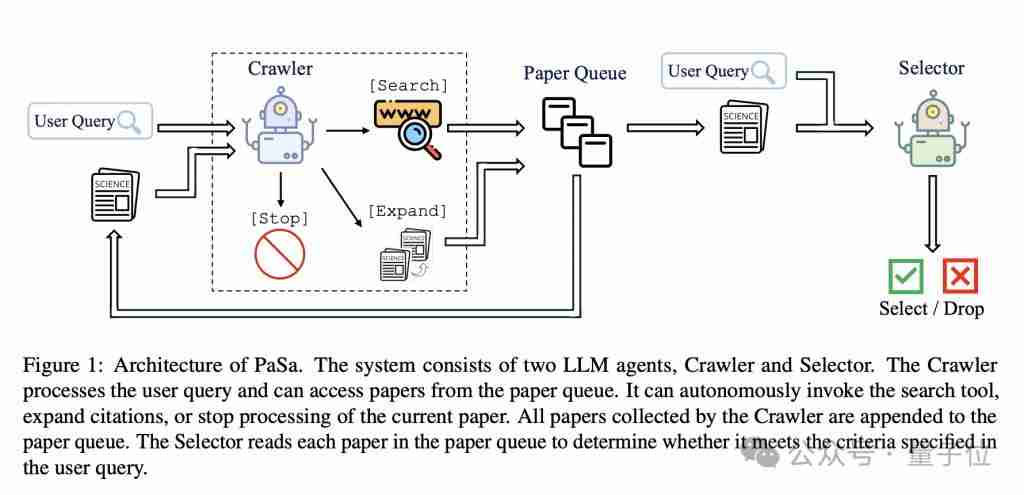

Crawler负责处理用户查询,生成多个搜索指令并检索相关论文,其工作机制基于基于token的马尔可夫决策过程(MDP)。
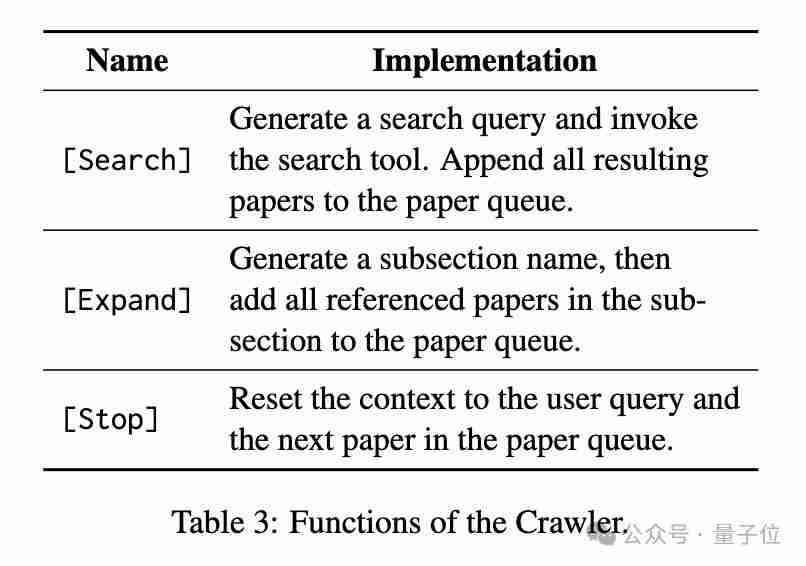
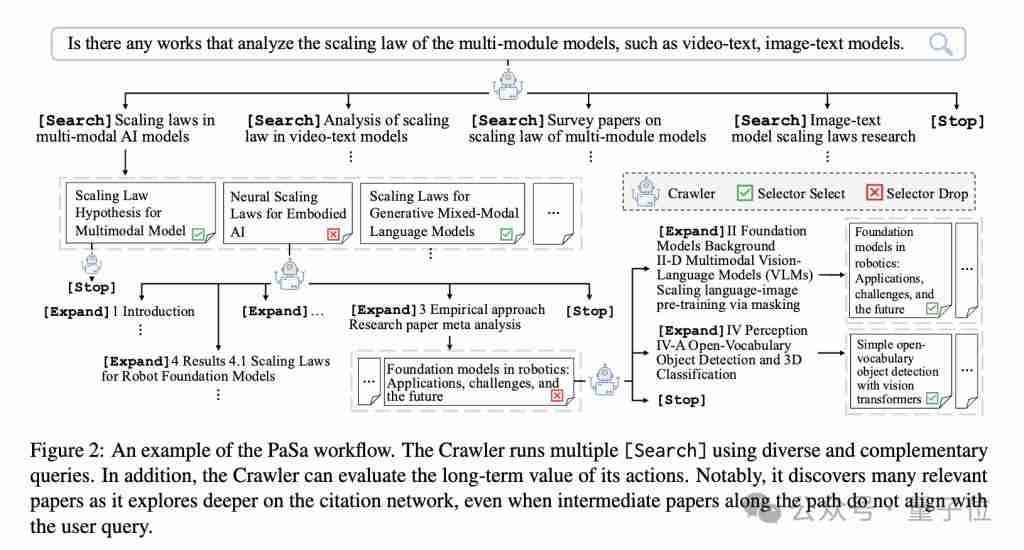
Selector负责仔细阅读每篇论文,评估其是否符合用户查询要求,并给出判断理由。
实验结果:全面超越基准模型
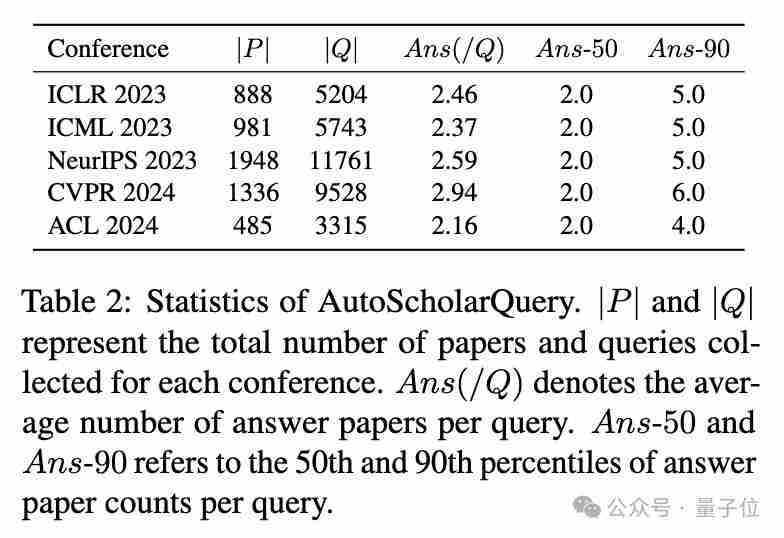
研究团队使用AutoScholarQuery和RealScholarQuery两个数据集对PaSa进行了评估。结果表明,PaSa-7b在召回率和准确率方面均显著优于所有基准模型。


团队介绍
PaSa由中科院院士鄂维南和字节跳动AI实验室总监李航领导的团队开发。


论文链接:https://www.php.cn/link/5eea6fd7b02448c35fd405cfe823d128 Demo:https://www.php.cn/link/b3ca85cd30bca7607c9520accaa4ffcf





























