







在Debian系统上运行Hadoop作业,需要完成以下步骤:
一、前期准备
- Java环境: 确保系统已安装Java 8或更高版本。
- Hadoop安装: 下载Hadoop发行版并解压至指定目录。
- 环境变量: 配置Hadoop环境变量,将Hadoop安装路径及bin目录添加到系统PATH中。
二、Hadoop配置
修改Hadoop核心配置文件(core-site.xml, hdfs-site.xml, mapred-site.xml, yarn-site.xml),设置Hadoop集群参数,包括临时目录、文件系统路径、YARN资源管理器等。
三、启动Hadoop
-
格式化HDFS: 在NameNode节点执行
hdfs namenode -format命令格式化HDFS文件系统(仅需在首次启动时执行)。 -
启动服务: 使用Hadoop启动脚本(例如
start-dfs.sh和start-yarn.sh)启动Hadoop集群服务。
四、作业提交
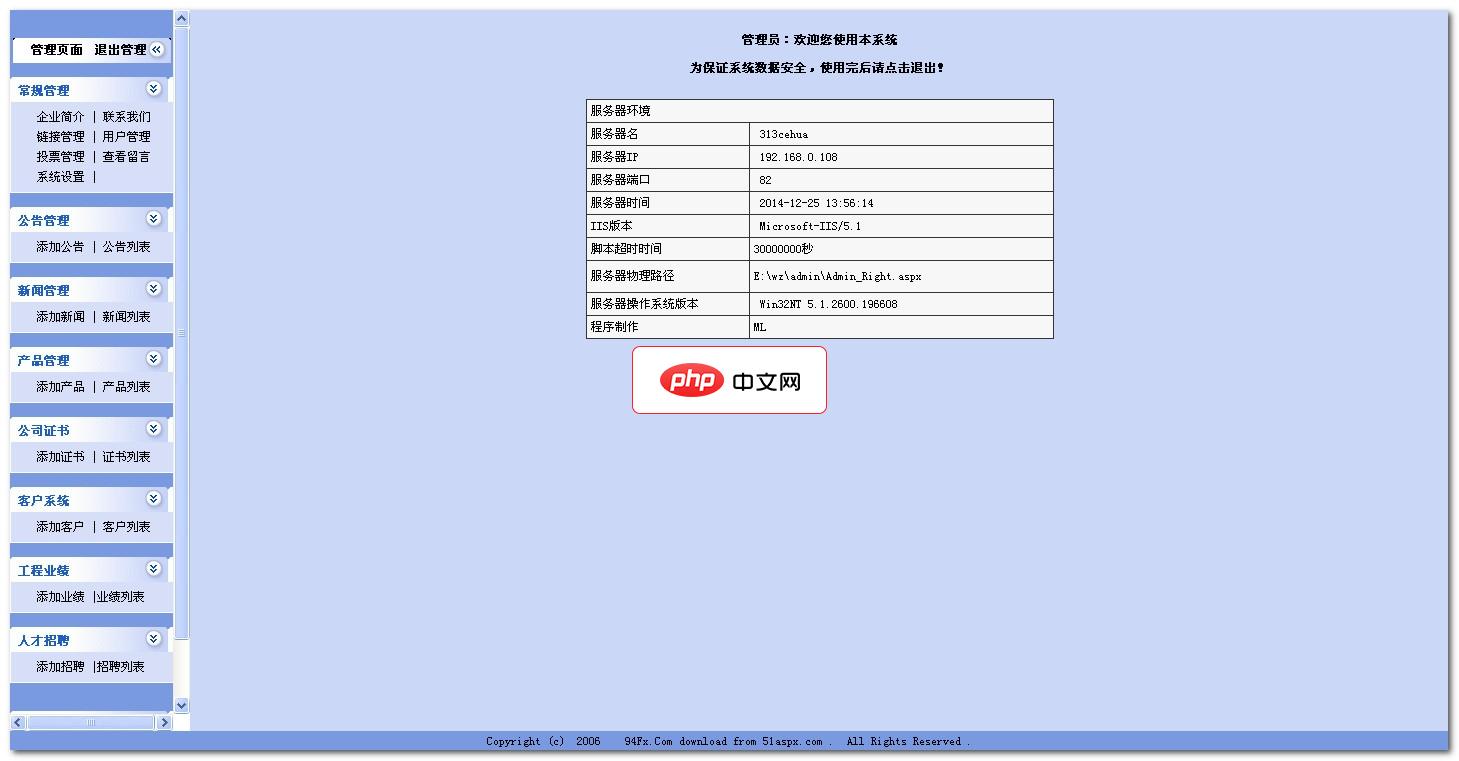
企业网站管理系统源码2.0
下载
这是一款比较精美的企业网站管理系统源码,功能比较完整,比较适合新手学习交流使用,也可以作为毕业设计或者课程设计使用,感兴趣的朋友可以下载看看哦。功能介绍:该源码主要包括前台和后台两大部分,具体功能如下:网站前台模块:主要包括企业简介、新闻中心、产品展示、公司证书、工程业绩、联系我们、客户系统、人才招聘等信息的浏览,以及客户留言的功能。网站后台模块1、常规管理:企业简介、链接管理、投票管理、系统设置
使用hadoop jar命令提交MapReduce作业:
hadoop jar your-job-jar-file.jar your.job.Class input-path output-path
其中:
-
your-job-jar-file.jar:你的MapReduce作业JAR包。 -
your.job.Class:包含Map和Reduce函数的主类。 -
input-path:输入数据路径。 -
output-path:输出数据路径。
五、作业监控
通过YARN ResourceManager的Web UI或命令行工具(例如yarn application -list)监控作业运行状态和进度。
重要提示: 以上步骤和命令可能因Hadoop版本和具体配置而略有差异。 请参考Hadoop官方文档获取最准确的信息。




























