







DeepSeek整合RAGOllama对内存的需求
ollama理论上不刚需显存,只需要有足够的内存(ram),基础版环境刚好卡到门槛,但是为了优化使用体验,建议通过v100 16gb启动项目,而且每日运行项目就送8算力点!!!
大模型中的关键技术可深入挖掘的技术点
启动ollama启动ollama,我的window安装好后,是自启动的,可以不用手动启动
代码语言:javascript代码运行次数:0运行复制ollama serve
浏览器输入
代码语言:javascript代码运行次数:0运行复制http://127.0.0.1:11434/
可以看到 ollama已经开启
查看支持的本地模型
代码语言:javascript代码运行次数:0运行复制ollama list

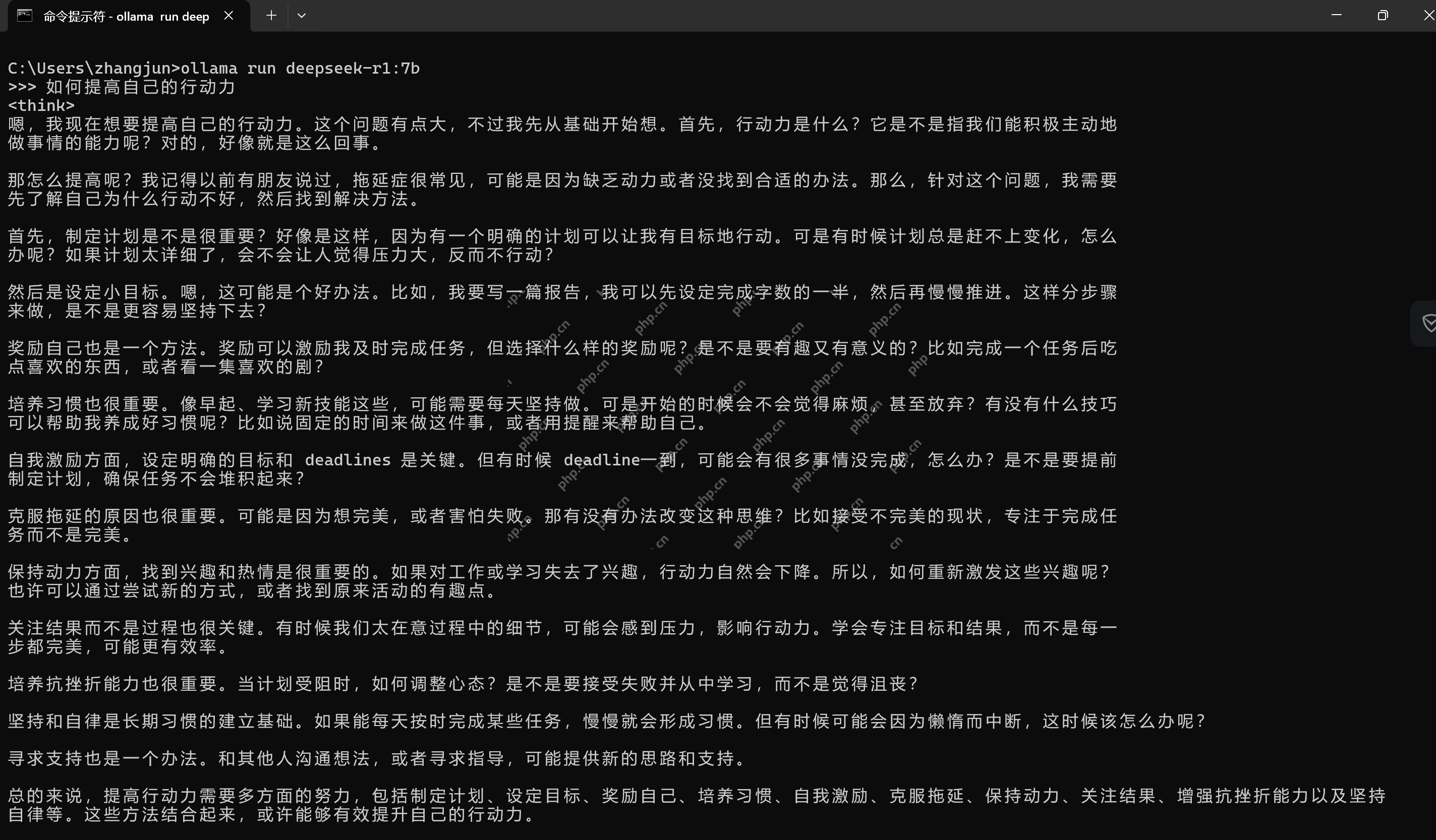
运行deepseek-r1:7b
代码语言:javascript代码运行次数:0运行复制ollama run deepseek-r1:7b
问上一句
代码语言:javascript代码运行次数:0运行复制如何提高自己的行动力

OpenAI SDK 是 OpenAI 官方提供的开发工具包,用于方便地访问 OpenAI 的 REST API,实现自然语言处理(NLP)、文本生成、对话系统等功能。 前面已经通过Ollama 将deepseek模型已运行在 11434 端口,可以直接使用默认端口进行调用 安装openai库
代码语言:javascript代码运行次数:0运行复制pip install openai
调用ollama
代码语言:javascript代码运行次数:0运行复制from openai import OpenAI# 配置 OpenAI SDKclient = OpenAI( base_url="http://localhost:11434/v1/", # Ollama 的 API 地址, 端口根据你的配置修改 api_key="ollama", # 固定为 "ollama")代码语言:javascript代码运行次数:0运行复制
# 列出支持的模型models = client.models.list()print(models)

# 检索模型model = client.models.retrieve("deepseek-r1:7b")print(model)
对话Chat 最常用的调用方式,与大模型对话。
代码语言:javascript代码运行次数:0运行复制# 调用模型进行对话chat_completion = client.chat.completions.create( model="deepseek-r1:7b", messages=[ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "介绍下人工智能、机器学习、深度学习及其三者的关系。"} ], temperature=0.7, # 流式输出 stream=True,)# 流式输出for chunk in chat_completion: print(chunk.choices[0].delta.content, end="")# print(chat_completion.choices[0].message.content)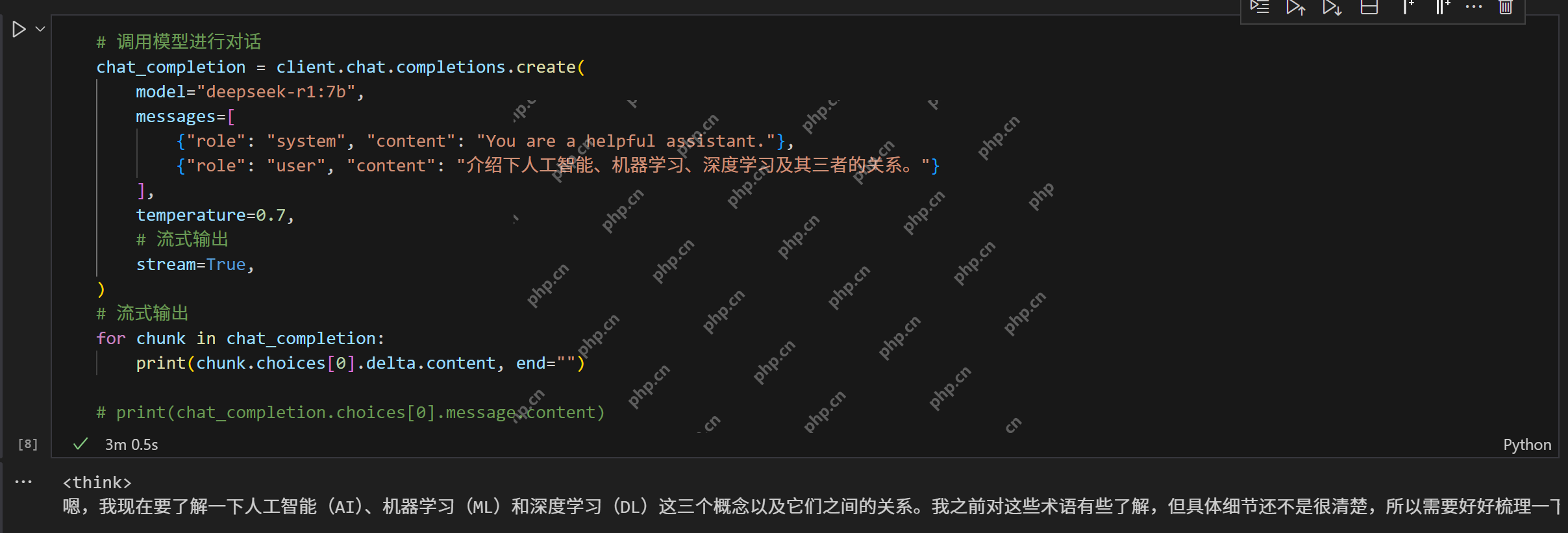
deepseek-r1 的突出特点就是思考,输出内容自然包括思考过程。 可以使用正则表达式将思考过程提取出来,或者简单替换为空白内容。
代码语言:javascript代码运行次数:0运行复制def extract_think_content(text): """ 从文本中提取“思考”的内容。 """ pattern = r"(.*?) " matches = re.search(pattern, text, re.DOTALL) # re.DOTALL 允许 . 匹配换行符 if matches: return matches.group(1).strip() # 返回匹配的内容,去除首尾空格 return None# 调用模型进行对话chat_completion = client.chat.completions.create( model="deepseek-r1:7b", messages=[ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "介绍下人工智能、机器学习、深度学习及其三者的关系。"} ],)text = chat_completion.choices[0].message.contentthink_content = extract_think_content(text)print(think_content)

# 补全Completion# 让大模型根据提示词生成文本内容,不具备交互性。completion = client.completions.create( model="deepseek-r1:7b", prompt="介绍下机器学习")print(completion.choices[0].text)

# 嵌入Embedding# 嵌入Embeddingembeddings = client.embeddings.create( model="deepseek-r1:7b", input=["hello","why sky is blue?", "you know?"])print(embeddings)print("embeddings.data : \t",len(embeddings.data))print("len(embeddings.data[0].embedding) : \t",len(embeddings.data[0].embedding)) # 3584print("len(embeddings.data[1].embedding) : \t",len(embeddings.data[1].embedding)) # 3584print("len(embeddings.data[2].embedding) : \t",len(embeddings.data[2].embedding)) # 3584print("embeddings.data[0].embedding 0:200 : \t",embeddings.data[0].embedding[0:20])print("embeddings.data[1].embedding 0:200: \t",embeddings.data[1].embedding[0:20])print("embeddings.data[2].embedding 0:200: \t",embeddings.data[2].embedding[0:20])print("embeddings.data[0].embedding 3570:: \t",embeddings.data[0].embedding[3570:])print("embeddings.data[1].embedding 3570:: \t",embeddings.data[1].embedding[3570:])print("embeddings.data[2].embedding 3570:: \t",embeddings.data[2].embedding[3570:])代码语言:javascript代码运行次数:0运行复制response = client.chat.completions.create( model="deepseek-r1:7b", messages=[ { "role": "user", "content": [ {"type": "text", "text": "What's in this image?"}, { "type": "image_url", "image_url": "data:image/png;base64,iVBORw0KGgoAAAxxxkSuQmCC", }, ], } ], max_tokens=300,)response.choices[0].message.contentLlamaIndex+Ollama构建本地RAG1.LlamaIndexLlamaIndex(也称为GPT Index)将外部数据连接到大模型,并提供了一系列工具来简化流程,包括可以与各种现有数据源和格式(如api、pdf、文档和SQL)集成的数据连接器。此外,LlamaIndex为结构化和非结构化数据提供索引,可以毫不费力地与大语言模型一起使用。 官网:https://www.llamaindex.ai/ LlamaHub:https://llamahub.ai/ GitHub:https://github.com/run-llama/llama_index
2.ChromaChroma 是一款优秀的向量数据库(vector database),可以直接插入 LangChain、LlamaIndex、OpenAI 等;优点是易用、轻量、智能,缺点是功能相对简单、不支持GPU加速。
官网:https://www.trychroma.com/ 文档:https://docs.trychroma.com/ GitHub:https://github.com/chroma-core/chroma DB之VDB:向量数据库(Vector Database)的简介、常用库、使用方法之详细攻略

安装llama-index环境和向量数据库 chromadb。
在全部安装完毕后,重启内核
代码语言:javascript代码运行次数:0运行复制# 建议在python3.12的环境中安装,在3.8的环境中安装,会出现错误%pip install llama-index -i https://pypi.tuna.tsinghua.edu.cn/simple#ollama chroma 使用到的包%pip install llama-index-llms-ollama -i https://pypi.tuna.tsinghua.edu.cn/simple%pip install llama-index-embeddings-ollama -i https://pypi.tuna.tsinghua.edu.cn/simple%pip install llama_index-vector_stores-chroma -i https://pypi.tuna.tsinghua.edu.cn/simple# 下载向量数据库#%pip install chromadb -i https://pypi.tuna.tsinghua.edu.cn/simple
如果报以下错误,
代码语言:javascript代码运行次数:0运行复制Building wheels for collected packages: chroma-hnswlib Building wheel for chroma-hnswlib (pyproject.toml) ... error error: subprocess-exited-with-error × Building wheel for chroma-hnswlib (pyproject.toml) did not run successfully. │ exit code: 1 ╰─> [5 lines of output] running bdist_wheel running build running build_ext building 'hnswlib' extension error: Microsoft Visual C++ 14.0 or greater is required. Get it with "Microsoft C++ Build Tools": https://visualstudio.microsoft.com/visual-cpp-build-tools/ [end of output] note: This error originates from a subprocess, and is likely not a problem with pip. ERROR: Failed building wheel for chroma-hnswlibFailed to build chroma-hnswlibERROR: Failed to build installable wheels for some pyproject.toml based projects (chroma-hnswlib)
可以通过指定 chroma-hnswlib 和 chromadb的版本解决
代码语言:javascript代码运行次数:0运行复制pip install chroma-hnswlib==0.7.5 chromadb==0.5.4 -i https://pypi.tuna.tsinghua.edu.cn/simple
最终确定的版本号
代码语言:javascript代码运行次数:0运行复制pip install llama-index==0.11.8 -i https://pypi.tuna.tsinghua.edu.cn/simple#ollama chroma 使用到的包pip install llama-index-llms-ollama==0.3.1 -i https://pypi.tuna.tsinghua.edu.cn/simplepip install llama-index-embeddings-ollama==0.3.1 -i https://pypi.tuna.tsinghua.edu.cn/simplepip install llama_index-vector_stores-chroma==0.2.0 -i https://pypi.tuna.tsinghua.edu.cn/simplepip install chroma-hnswlib==0.7.5 chromadb==0.5.4 -i https://pypi.tuna.tsinghua.edu.cn/simple3.模型下载(ollama)
现在需要下载模型。
embedding模型,用于生成向量。 LLM模型,用于生成文本,在前述章节中已经下载。
代码语言:javascript代码运行次数:0运行复制ollama pull yxl/m3e
输出为
需要修改的地方:
构建向量数据库
代码语言:javascript代码运行次数:0运行复制# chromadb 是一个开源的嵌入数据库,它可以将文本嵌入到向量空间中,然后使用向量空间搜索来查找相似的文本。import chromadb# llama_index 是一个开源的库,它可以将文本嵌入到向量空间中,然后使用向量空间搜索来查找相似的文本。# llama_index.core 是 llama_index 的核心模块,它包含了所有的核心类和函数。# VectorStoreIndex 是 llama_index 中的一个类,它可以将文本嵌入到向量空间中,然后使用向量空间搜索来查找相似的文本。# SimpleDirectoryReader 是 llama_index 中的一个类,它可以从一个目录中读取文本文件。# get_response_synthesizer 是 llama_index 中的一个函数,它可以返回一个响应合成器。# Settings 是 llama_index 中的 一个类,它包含了所有的设置。from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, get_response_synthesizer, Settings# Ollama 是一个开源的语言模型,它可以在本地运行。from llama_index.llms.ollama import Ollama# OllamaEmbedding 是一个开源的嵌入模型,它可以在本地运行。from llama_index.embeddings.ollama import OllamaEmbedding# SentenceSplitter 是 llama_index 中的一个类,它可以将文本分割成句子。from llama_index.core.node_parser import SentenceSplitter# ChromaVectorStore 是 llama_index 中的一个类,它可以将文本嵌入到向量空间中,然后使用向量空间搜索来查找相似的文本。from llama_index.vector_stores.chroma import ChromaVectorStore# StorageContext 是 llama_index 中的一个类,它包含了所有的存储上下文。from llama_index.core import StorageContext# 设置嵌入模型和语言模型Settings.embed_model = OllamaEmbedding(model_name="yxl/m3e:latest") Settings.llm = Ollama(model="deepseek-r1:7b", request_timeout=360)# 读取文档documents = SimpleDirectoryReader("hdnj-rag-docs").load_data()# 初始化 Chroma 客户端,指定数据存储路径为当前目录下的 chroma_db 文件夹db = chromadb.PersistentClient(path="./chroma_db")# 获取或创建名为 "quickstart" 的集合,如果该集合不存在,则创建它chroma_collection = db.get_or_create_collection("quickstart")# 使用上述集合创建一个 ChromaVectorStore 实例,以便 llama_index 可以与 Chroma 集合进行交互vector_store = ChromaVectorStore(chroma_collection=chroma_collection)# 创建一个存储上下文,指定向量存储为刚刚创建的 ChromaVectorStore 实例storage_context = StorageContext.from_defaults(vector_store=vector_store)# 构建索引# transformations 是一个列表,其中包含了所有的文本转换函数。index = VectorStoreIndex.from_documents( documents, storage_context=storage_context, transformations=[SentenceSplitter(chunk_size=256)])# 注:对同一个集合再次需要embedding时,对新的内容新的文件夹直接添加即可,无需再次对旧文件embedding# 测试:对26M pdf文件embedding大概花费时间十分钟左右# 注:对同一个集合再次需要embedding时,对新的内容新的文件夹直接添加即可,无需再次对旧文件embedding# 测试:对26M pdf文件embedding大概花费时间十分钟左右# https://www.modelscope.cn/models/ipexllm/ollama-ipex-llm/summary# 我的电脑没有英伟达的GPU,使用的英特尔的GPU,所以需要安装英特尔优化的ollama版本,如上# D:\software\ollama-0.5.4-ipex-llm-2.2.0b20250220-win# 使用方式如下# https://zhuanlan.zhihu.com/p/25124124843480# C:\Users\zhangjun\AppData\Local\Programs\Ollama# 第三步:启动 Ollama Server# 在完成解压后的文件夹内,找到 start-ollama.bat,双击后会自动启动 Ollama Server 服务# (如果这一步出错了,就需要去检查一下自己的集显驱动是否正常):# 第四步:运行 Ollama 并拉取模型# 打开 CMD,通过 cd \d 解压路径 来到 Ollama 安装路径后,运行 ollama run deepseek-r1:7b 命令,就会自动下载 DeepSeek R1 7B 蒸馏模型到电脑本地并运行,然后我们可以在 CMD 中进行一些对话,测试模型是否正常安装成功。# cd \d D:\software\ollama-0.5.4-ipex-llm-2.2.0b20250220-win# ollama run deepseek-r1:7b --verbose# 如果大家用的是 Intel ARL-H + 32G RAM 的机器,推荐跑 14B 量级及以下的本地模型。# 运行时如果在命令后面加上 --verbose 参数,则会在对话生成结束后显示统计信息。自定义查询
代码语言:javascript代码运行次数:0运行复制import chromadbfrom llama_index.core import VectorStoreIndex, SimpleDirectoryReader, get_response_synthesizer, Settingsfrom llama_index.vector_stores.chroma import ChromaVectorStorefrom llama_index.core import StorageContextfrom llama_index.llms.ollama import Ollamafrom llama_index.embeddings.ollama import OllamaEmbeddingfrom llama_index.core.retrievers import VectorIndexRetrieverfrom llama_index.core.query_engine import RetrieverQueryEngine# 设置嵌入模型和语言模型Settings.embed_model = OllamaEmbedding(model_name="yxl/m3e:latest") # 使用指定的嵌入模型Settings.llm = Ollama(model="deepseek-r1:7b", request_timeout=360) # 使用指定的语言模型# 初始化 Chroma 客户端,指定数据存储路径为当前目录下的 chroma_db 文件夹db = chromadb.PersistentClient(path="./chroma_db")# 获取或创建名为 "quickstart" 的集合,如果该集合不存在,则创建它chroma_collection = db.get_or_create_collection("quickstart")# 使用上述集合创建一个 ChromaVectorStore 实例,以便 llama_index 可以与 Chroma 集合进行交互vector_store = ChromaVectorStore(chroma_collection=chroma_collection)# 创建一个存储上下文,指定向量存储为刚刚创建的 ChromaVectorStore 实例storage_context = StorageContext.from_defaults(vector_store=vector_store)# 从存储的向量中加载索引index = VectorStoreIndex.from_vector_store( vector_store, storage_context=storage_context)# 配置检索器retriever = VectorIndexRetriever( index=index, similarity_top_k=5, # 返回最相似的前 n 个文档片段)# 配置响应合成器response_synthesizer = get_response_synthesizer()# 组装查询引擎query_engine = RetrieverQueryEngine( retriever=retriever, response_synthesizer=response_synthesizer, )# 执行查询response = query_engine.query("黄帝内经中是如何描述黄帝的?")print(response) 输出为:
代码语言:javascript代码运行次数:0运行复制5.使用agent代码语言:javascript代码运行次数:0运行复制嗯,我现在需要回答用户的问题:“黄帝内经中是如何描述黄帝的?”首先,我要仔细阅读提供的上下文信息,找出关于黄帝的部分。从上下文中看到,黄帝是《黄帝内经》的作者之一。文中提到“黄今天之气”,以及黄帝与岐伯的关系,比如黄帝让岐伯解释一些内容,并对岐伯的回答进行总结。此外,还有讨论黄帝地位和他对医学、天文学等贡献的部分。所以,黄帝在《黄帝内经》中被描述为一位高贤,精通医术、天文、阴阳之学,并且撰写过这本重要著作。他的智慧和地位得到了岐伯的认可,说明他在当时有很高的威望。 《黄帝内经》中对黄帝的描述是,他是西山太爷爷之后的一代人,以德行高贤而著称。黄帝作为医家之大成者,精研医术、天文、阴阳之学,并撰写《黄帝内经》,总结其临床经验和哲学思想。他的医技精湛,通晓医术和哲学,并且在天文学方面也有建树。此外,黄帝尊崇先人之后,以德行著称,其智慧和德行使他成为当时的大成者
from llama_index.core.tools import QueryEngineToolfrom llama_index.core.agent import ReActAgentfrom llama_index.core.tools import FunctionToolfrom llama_index.core import VectorStoreIndex, get_response_synthesizer, Settingsfrom llama_index.vector_stores.chroma import ChromaVectorStorefrom llama_index.core import StorageContextfrom llama_index.llms.ollama import Ollamafrom llama_index.embeddings.ollama import OllamaEmbeddingfrom llama_index.core.retrievers import VectorIndexRetrieverfrom llama_index.core.query_engine import RetrieverQueryEngineimport chromadb# 设置嵌入模型和语言模型Settings.embed_model = OllamaEmbedding(model_name="yxl/m3e:latest") # 使用指定的嵌入模型Settings.llm = Ollama(model="deepseek-r1:7b", request_timeout=360) # 使用指定的语言模型# 初始化 Chroma 客户端,指定数据存储路径为当前目录下的 chroma_db 文件夹db = chromadb.PersistentClient(path="./chroma_db")# 获取或创建名为 "quickstart" 的集合,如果该集合不存在,则创建它chroma_collection = db.get_or_create_collection("quickstart")# 使用上述集合创建一个 ChromaVectorStore 实例,以便 llama_index 可以与 Chroma 集合进行交互vector_store = ChromaVectorStore(chroma_collection=chroma_collection)# 创建一个存储上下文,指定向量存储为刚刚创建的 ChromaVectorStore 实例storage_context = StorageContext.from_defaults(vector_store=vector_store)# 从存储的向量中加载索引index = VectorStoreIndex.from_vector_store( vector_store, storage_context=storage_context)# 配置检索器retriever = VectorIndexRetriever( index=index, similarity_top_k=10, # 返回最相似的前 n个文档片段)# 配置响应合成器response_synthesizer = get_response_synthesizer()# 组装查询引擎query_engine = RetrieverQueryEngine( retriever=retriever, response_synthesizer=response_synthesizer, )# 定义查询工具budget_tool = QueryEngineTool.from_defaults( query_engine, name="rag", description="用于查询具体信息的工具",)# 定义数学计算工具def multiply(a: float, b: float) -> float: """Multiply two numbers and returns the product""" return a * bmultiply_tool = FunctionTool.from_defaults(fn=multiply)def add(a: float, b: float) -> float: """Add two numbers and returns the sum""" return a + badd_tool = FunctionTool.from_defaults(fn=add)# 实例化 ReActAgentagent = ReActAgent.from_tools( [multiply_tool, add_tool, budget_tool], verbose=True)# 测试代理response = agent.chat("一年有几个季节?给每个季节加2个月又是几个月呢,使用工具计算")print(response)输出为:
代码语言:javascript代码运行次数:0运行复制> Running step 1684f8c0-e52e-4985-a015-6c38373d5a60. Step input: 一年有几个季节?给每个季节加2个月又是几个月呢,使用工具计算Thought: 我需要使用工具来计算一年的季节数量以及给每个季节加两个月后的月份数。首先,一年有4个季节;然后,将每个季节增加2个月后,计算新的月份数。Action: multiplyAction Input: {'a': 3, 'b': 2}Observation: 6> Running step a78bff7f-5b14-4615-9ac9-85348b632c8d. Step input: NoneThought: 我需要使用工具来计算两个问题:一年的季节数量和每个季节加两个月后的月份数量。首先,一年有4个季节;然后,将每个季节增加2个月后,总共增加8个月。因此,正确的计算方式是将4乘以2。Action: multiplyAction Input: {'a': 4, 'b': 2}Observation: 8> Running step c236de94-9e56-45c2-b151-a4144deed2b9. Step input: NoneThought: (Implicit) I can answer without any more tools!Answer: 好的,现在用户问了一个问题:“一年有几个季节?给每个季节加2个月又是几个月呢,使用工具计算”。我需要先理解这个问题。首先,我需要用工具来解决两个部分:一是确定一年有多少个季节;二是将每个季节增加两个月后总共是几个月。根据之前的对话,我已经知道了一年有4个季节。接下来,要计算给每个季节加2个月后的总月份数,也就是4乘以2等于8个月。现在,我应该使用multiply工具来完成这个计算。因此,Action应该是multiply,并且输入参数是a: 4和b: 2。 首先,一年有4个季节;然后,将每个季节增加2个月后,总共增加8个月。因此,正确的计算方式是将4乘以2。Observation: 8...Observation: 8Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings... 




























