以下是对给定文章进行伪原创的输出,确保不改变文章的大意和图片的位置,并保持原文的语言:
- 字典字符集的笛卡尔乘积
问题描述:对于一个由字典字符集组合而成的表达式,如何求出所有可能的元素组合?例如,表达式[0-9][a-z],其中0-9代表10个数字,a-z代表26个小写字母,其所有可能的元素组合为0a, 0b, ..., 0z, 1a, 1b, ..., 9z。字典字符集的笛卡尔乘积示例如下:
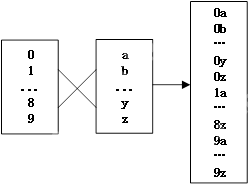
问题分析:对于任意一个由字典字符集构成的表达式[dic0][dic1]...[dicn],可以将其从左到右视为一个由字典元素组成的“数”,这符合我们日常表示数值的高低位习惯。例如,如果所有字典都是[0-9],那么表达式[0-9][0-9]就代表数值字符串00到99。笛卡尔乘积的空间是各个字典高度的乘积,给定其空间中的任意一个元素下标,就可以对应到每个字典中的元素下标。比如[0-9][0-9]的笛卡尔乘积空间是10*10=100,第0个元素是00,第99个元素是99。
每个字典元素都有一个位权重。例如,表达式[0-9][0-9]中,第一个字典的位权重w=10,第二个字典的位权重w=1。我们常说的个位、十位、百位,就是基于数值位的位权重来称呼的。位权重的意义在于,数值是其位权重的多少倍,就取第几个元素。例如,第99个元素(下标从0开始),数值99是十位的位权重w=10的9倍,所以元素为字符‘9’,对数值99取w=10的余数得9,9是个位的位权重w=1的9倍,所以元素为字符‘9’,因此构成了字符串99。
实现示例:对于表达式[0-9][a-z][A-Z],其笛卡尔乘积的具体过程可以描述如下:(1)从左至右(高位到低位)计算各个字典字符集所在数位的计算单位,通过当前字典右边的字典高度相乘得到,例如[0-9]的计数单位w=2626=676,[a-z]的计数单位w=261=26,[A-Z]的计数单位w=1。(2)给定笛卡尔乘积空间的元素下标i,根据i找到各个字典内的元素下标的过程如下,从高位开始查找,即从左开始查找。(2.1)查找字典[0-9]中的元素下标:[0-9].index=i/[0-9].w;(2.2)查找字典[a-z]中的元素下标[a-z].index:i=i%[0-9].w; [a-z].index=i/[a-z].w;(2.3)查找字典[A-Z]中的元素下标[A-Z].index:i=i%[a-z].w;[A-Z].index=i/1=i。(3)将i从0递增至笛卡尔乘积的空间大小减一,即10*26*26-1,重复步骤2,即可完成表达式[0-9][a-z][A-Z]的笛卡尔乘积。
例如,给定第677个笛卡尔乘积的元素,那么[0-9].index=1,所以取[0-9]内的元素‘1’,[a-z].index=671%676/26=0,所以取出元素‘a’,[A-Z].index=1/1=1,所以取出元素‘B’,因此第677个元素就是“1aB”。
- 源码
以下代码在Linux平台上编译运行,稍作修改即可移植到Windows平台。其功能是完成多个字典字符集的笛卡尔乘积,并通过OpenMP进行并行加速。该代码的正确性已在实际项目中通过验证。
代码语言:JavaScript
代码运行次数:0
运行
复制
#include
#include
#include
#include




































