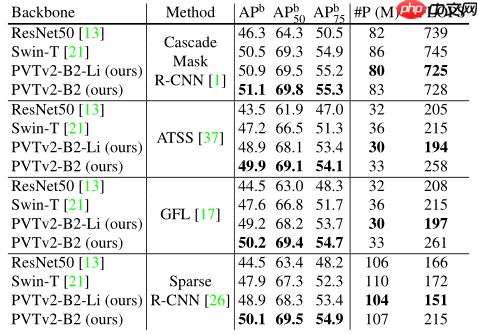
本文复现了PVT v2模型,其基于v1改进,亮点是Linear SRA。代码包含导入包、基础模块定义、模型组网等部分,还提供了不同缩放结构及预训练权重。通过在Cifar10数据集上训练5轮验证性能,模型表现良好。PVT v2引入卷积等操作提升性能,参数量和计算量较小,下游任务表现佳。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

前言
Hi guy,我们怎么又见面了,(俗套的开场白),哈哈哈哈,那么这次来复现一个PVT v2,它是基于v1进行改动
完整代码
导入所需要的包
In [ ]
import paddleimport paddle.nn as nnimport paddle.nn.functional as Ffrom functools import partialimport math trunc_normal_ = nn.initializer.TruncatedNormal(std=.02) zeros_ = nn.initializer.Constant(value=0.) ones_ = nn.initializer.Constant(value=1.) kaiming_normal_ = nn.initializer.KaimingNormal()
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int):
基础模块定义
In [ ]
def to_2tuple(x):
return tuple([x] * 2)def swapdim(x, dim1, dim2):
a = list(range(len(x.shape)))
a[dim1], a[dim2] = a[dim2], a[dim1] return x.transpose(a)def drop_path(x, drop_prob = 0., training = False):
if drop_prob == 0. or not training: return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1)
random_tensor = paddle.to_tensor(keep_prob) + paddle.rand(shape)
random_tensor = paddle.floor(random_tensor)
output = x.divide(keep_prob) * random_tensor return outputclass DropPath(nn.Layer):
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob def forward(self, x):
return drop_path(x, self.drop_prob, self.training)class Identity(nn.Layer):
def __init__(self, *args, **kwargs):
super(Identity, self).__init__()
def forward(self, input):
return input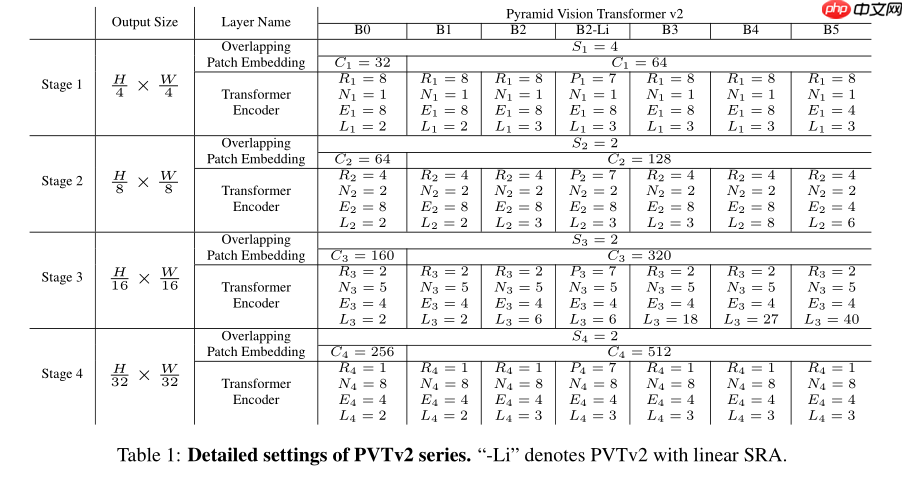

In [ ]
class Mlp(nn.Layer):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0., linear=False):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.dwconv = DWConv(hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
self.linear = linear if self.linear:
self.relu = nn.ReLU() def forward(self, x, H, W):
x = self.fc1(x) if self.linear:
x = self.relu(x)
x = self.dwconv(x, H, W)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x) return xclass Attention(nn.Layer):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., sr_ratio=1, linear=False):
super().__init__() assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.q = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.kv = nn.Linear(dim, dim * 2, bias_attr=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.linear = linear
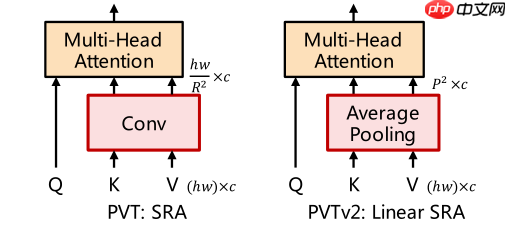
self.sr_ratio = sr_ratio if not linear: if sr_ratio > 1:
self.sr = nn.Conv2D(dim, dim, kernel_size=sr_ratio, stride=sr_ratio)
self.norm = nn.LayerNorm(dim) else:
self.pool = nn.AdaptiveAvgPool2D(7)
self.sr = nn.Conv2D(dim, dim, kernel_size=1, stride=1)
self.norm = nn.LayerNorm(dim)
self.act = nn.GELU() def forward(self, x, H, W):
B, N, C = x.shape
q = self.q(x).reshape([B, N, self.num_heads, C // self.num_heads]).transpose([0, 2, 1, 3]) if not self.linear: if self.sr_ratio > 1:
x_ = x.transpose([0, 2, 1]).reshape([B, C, H, W])
x_ = self.sr(x_).reshape([B, C, -1]).transpose([0, 2, 1])
x_ = self.norm(x_)
kv = self.kv(x_).reshape([B, -1, 2, self.num_heads, C // self.num_heads]).transpose([2, 0, 3, 1, 4]) else:
kv = self.kv(x).reshape([B, -1, 2, self.num_heads, C // self.num_heads]).transpose([2, 0, 3, 1, 4]) else:
x_ = x.transpose([0, 2, 1]).reshape([B, C, H, W])
x_ = self.sr(self.pool(x_)).reshape([B, C, -1]).transpose([0, 2, 1])
x_ = self.norm(x_)
x_ = self.act(x_)
kv = self.kv(x_).reshape([B, -1, 2, self.num_heads, C // self.num_heads]).transpose([2, 0, 3, 1, 4])
k, v = kv[0], kv[1]
attn = (q @ swapdim(k, -2, -1)) * self.scale
attn = F.softmax(attn, axis=-1)
attn = self.attn_drop(attn)
x = swapdim((attn @ v), 1, 2).reshape([B, N, C])
x = self.proj(x)
x = self.proj_drop(x) return xclass Block(nn.Layer):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, sr_ratio=1, linear=False):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim,
num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, sr_ratio=sr_ratio, linear=linear) # NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop, linear=linear) def forward(self, x, H, W):
x = x + self.drop_path(self.attn(self.norm1(x), H, W))
x = x + self.drop_path(self.mlp(self.norm2(x), H, W)) return xclass OverlapPatchEmbed(nn.Layer):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=7, stride=4, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
self.img_size = img_size
self.patch_size = patch_size
self.H, self.W = img_size[0] // patch_size[0], img_size[1] // patch_size[1]
self.num_patches = self.H * self.W
self.proj = nn.Conv2D(in_chans, embed_dim, kernel_size=patch_size, stride=stride,
padding=(patch_size[0] // 2, patch_size[1] // 2))
self.norm = nn.LayerNorm(embed_dim) def forward(self, x):
x = self.proj(x)
_, _, H, W = x.shape
x = x.flatten(2)
x = swapdim(x, 1, 2)
x = self.norm(x) return x, H, Wclass PyramidVisionTransformerV2(nn.Layer):
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dims=[64, 128, 256, 512],
num_heads=[1, 2, 4, 8], mlp_ratios=[4, 4, 4, 4], qkv_bias=False, qk_scale=None, drop_rate=0.,
attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1], num_stages=4, linear=False):
super().__init__()
self.num_classes = num_classes
self.depths = depths
self.num_stages = num_stages
dpr = [x for x in paddle.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
cur = 0
for i in range(num_stages):
patch_embed = OverlapPatchEmbed(img_size=img_size if i == 0 else img_size // (2 ** (i + 1)),
patch_size=7 if i == 0 else 3,
stride=4 if i == 0 else 2,
in_chans=in_chans if i == 0 else embed_dims[i - 1],
embed_dim=embed_dims[i])
block = nn.LayerList([Block(
dim=embed_dims[i], num_heads=num_heads[i], mlp_ratio=mlp_ratios[i], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + j], norm_layer=norm_layer,
sr_ratio=sr_ratios[i], linear=linear) for j in range(depths[i])])
norm = norm_layer(embed_dims[i])
cur += depths[i] setattr(self, f"patch_embed{i + 1}", patch_embed) setattr(self, f"block{i + 1}", block) setattr(self, f"norm{i + 1}", norm) # classification head
self.head = nn.Linear(embed_dims[3], num_classes) if num_classes > 0 else Identity() def freeze_patch_emb(self):
self.patch_embed1.requires_grad = False
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else Identity() def forward_features(self, x):
B = x.shape[0] for i in range(self.num_stages):
patch_embed = getattr(self, f"patch_embed{i + 1}")
block = getattr(self, f"block{i + 1}")
norm = getattr(self, f"norm{i + 1}")
x, H, W = patch_embed(x) for blk in block:
x = blk(x, H, W)
x = norm(x) if i != self.num_stages - 1:
x = x.reshape([B, H, W, -1]).transpose([0, 3, 1, 2]) return x.mean(axis=1) def forward(self, x):
x = self.forward_features(x)
x = self.head(x) return xclass DWConv(nn.Layer):
def __init__(self, dim=768):
super(DWConv, self).__init__()
self.dwconv = nn.Conv2D(dim, dim, 3, 1, 1, bias_attr=True, groups=dim) def forward(self, x, H, W):
B, N, C = x.shape
x = swapdim(x, 1, 2)
x = x.reshape([B, C, H, W])
x = self.dwconv(x)
x = x.flatten(2)
x = swapdim(x, 1, 2) return x模型缩放
模型各种缩放结构官方性能如下所示
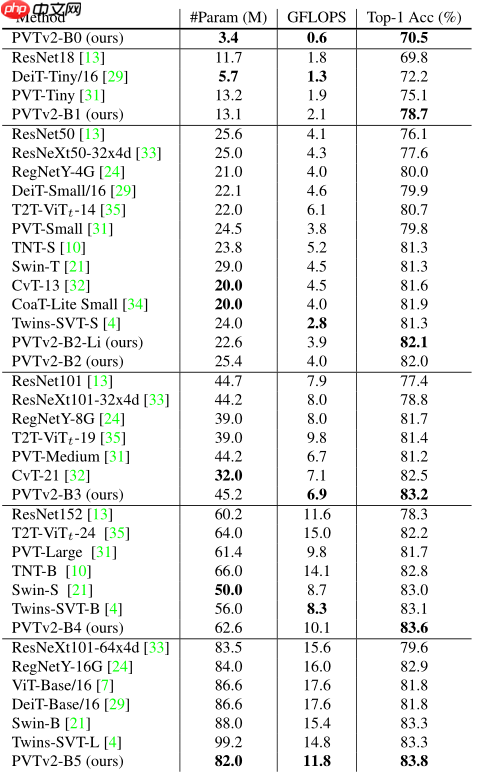
In [ ]
def pvt_v2_b0(**kwargs):
model = PyramidVisionTransformerV2(
patch_size=4, embed_dims=[32, 64, 160, 256], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, epsilon=1e-6), depths=[2, 2, 2, 2], sr_ratios=[8, 4, 2, 1],
**kwargs) return modeldef pvt_v2_b1(**kwargs):
model = PyramidVisionTransformerV2(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, epsilon=1e-6), depths=[2, 2, 2, 2], sr_ratios=[8, 4, 2, 1],
**kwargs) return modeldef pvt_v2_b2(**kwargs):
model = PyramidVisionTransformerV2(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, epsilon=1e-6), depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1], **kwargs) return modeldef pvt_v2_b3(**kwargs):
model = PyramidVisionTransformerV2(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, epsilon=1e-6), depths=[3, 4, 18, 3], sr_ratios=[8, 4, 2, 1],
**kwargs) return modeldef pvt_v2_b4(**kwargs):
model = PyramidVisionTransformerV2(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, epsilon=1e-6), depths=[3, 8, 27, 3], sr_ratios=[8, 4, 2, 1],
**kwargs) return modeldef pvt_v2_b5(**kwargs):
model = PyramidVisionTransformerV2(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[4, 4, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, epsilon=1e-6), depths=[3, 6, 40, 3], sr_ratios=[8, 4, 2, 1],
**kwargs) return modeldef pvt_v2_b2_li(**kwargs):
model = PyramidVisionTransformerV2(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, epsilon=1e-6), depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1], linear=True,
**kwargs) return model查看模型
In [ ]
# 模型各层查看m = pvt_v2_b0()print(m)# 前向计算x = paddle.randn([2, 3, 224, 224])
out = m(x)
loss = out.sum()
loss.backward()print('Single iteration completed successfully')预训练权重加载
Results on ImageNet-1K
| Model | # Param | Top-1 Acc. | Top-5 Acc. |
|---|---|---|---|
| pvt v2 b0 | 3M | 0.703 | 0.900 |
| pvt v2 b1 | 14M | 0.784 | 0.943 |
| pvt v2 b2 | 25M | 0.817 | 0.959 |
| pvt v2 b2 li | 45M | 0.829 | 0.964 |
| pvt v2 b3 | 62M | 0.834 | 0.967 |
| pvt v2 b4 | 82M | 0.835 | 0.966 |
| pvt v2 b5 | 22M | 0.819 | 0.960 |
In [ ]
# pvt v2 b0m = pvt_v2_b0()
m.set_state_dict(paddle.load('/home/aistudio/data/data97429/pvt_v2_b0.pdparams'))# pvt v2 b1m = pvt_v2_b1()
m.set_state_dict(paddle.load('/home/aistudio/data/data97429/pvt_v2_b1.pdparams'))# pvt v2 b2m = pvt_v2_b2()
m.set_state_dict(paddle.load('/home/aistudio/data/data97429/pvt_v2_b2.pdparams'))# pvt v2 b2 linearm = pvt_v2_b2_li()
m.set_state_dict(paddle.load('/home/aistudio/data/data97429/pvt_v2_b2_li.pdparams'))# pvt v2 b3m = pvt_v2_b3()
m.set_state_dict(paddle.load('/home/aistudio/data/data97429/pvt_v2_b3.pdparams'))# pvt v2 b4m = pvt_v2_b4()
m.set_state_dict(paddle.load('/home/aistudio/data/data97429/pvt_v2_b4.pdparams'))# pvt v2 b5m = pvt_v2_b5()
m.set_state_dict(paddle.load('/home/aistudio/data/data97429/pvt_v2_b5.pdparams'))Cifar10 验证性能
数据准备
In [15]
import paddle.vision.transforms as Tfrom paddle.vision.datasets import Cifar10
paddle.set_device('gpu')#数据准备transform = T.Compose([
T.Resize(size=(224,224)),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225],data_format='HWC'),
T.ToTensor()
])
train_dataset = Cifar10(mode='train', transform=transform)
val_dataset = Cifar10(mode='test', transform=transform)Cache file /home/aistudio/.cache/paddle/dataset/cifar/cifar-10-python.tar.gz not found, downloading https://dataset.bj.bcebos.com/cifar/cifar-10-python.tar.gz Begin to download Download finished
模型准备
In [16]
m = pvt_v2_b0()
m.set_state_dict(paddle.load('/home/aistudio/data/data97429/pvt_v2_b0.pdparams'))
model = paddle.Model(m)开始训练
由于时间篇幅只训练5轮,感兴趣的同学可以继续训练
In [17]
model.prepare(optimizer=paddle.optimizer.AdamW(learning_rate=0.0001, parameters=model.parameters()),
loss=paddle.nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy())
visualdl=paddle.callbacks.VisualDL(log_dir='visual_log') # 开启训练可视化model.fit(
train_data=train_dataset,
eval_data=val_dataset,
batch_size=16,
epochs=5,
verbose=1,
callbacks=[visualdl]
)The loss value printed in the log is the current step, and the metric is the average value of previous step. Epoch 1/5
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:77: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working return (isinstance(seq, collections.Sequence) and
step 3125/3125 [==============================] - loss: 0.2681 - acc: 0.8151 - 124124ms/step Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 625/625 [==============================] - loss: 0.2054 - acc: 0.9154 - 57ms/step Eval samples: 10000 Epoch 2/5 step 3125/3125 [==============================] - loss: 0.3357 - acc: 0.9383 - 126ms/step Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 625/625 [==============================] - loss: 0.1274 - acc: 0.9245 - 58ms/step Eval samples: 10000 Epoch 3/5 step 3125/3125 [==============================] - loss: 0.0413 - acc: 0.9594 - 126ms/step Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 625/625 [==============================] - loss: 0.0439 - acc: 0.9367 - 57ms/step Eval samples: 10000 Epoch 4/5 step 3125/3125 [==============================] - loss: 0.0458 - acc: 0.9696 - 126ms/step Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 625/625 [==============================] - loss: 0.2247 - acc: 0.9351 - 56ms/step Eval samples: 10000 Epoch 5/5 step 3125/3125 [==============================] - loss: 0.0024 - acc: 0.9760 - 128ms/step Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 625/625 [==============================] - loss: 0.0181 - acc: 0.9374 - 57ms/step Eval samples: 10000
训练可视化
总结
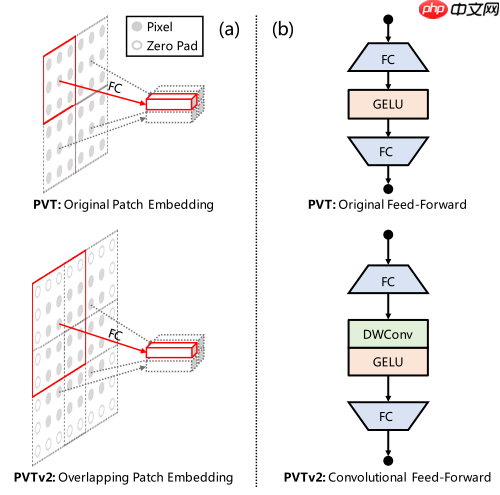
- PVT v2 引入了卷积操作、zero-padding、avgpool的注意力层,从三个方面提升了性能
- 相比同时期的ViT模型,具有更小的参数量和计算量
- 在下游任务,PVT v2 展现了良好的性能