随着游戏市场的崛起,游戏相关从业人员急需了解玩家对游戏的实际体验,以便有针对性地指导游戏运营和开发。因此可基于深度学习模型对玩家评论进行情感分析,做网络游戏舆情态势分析项目。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

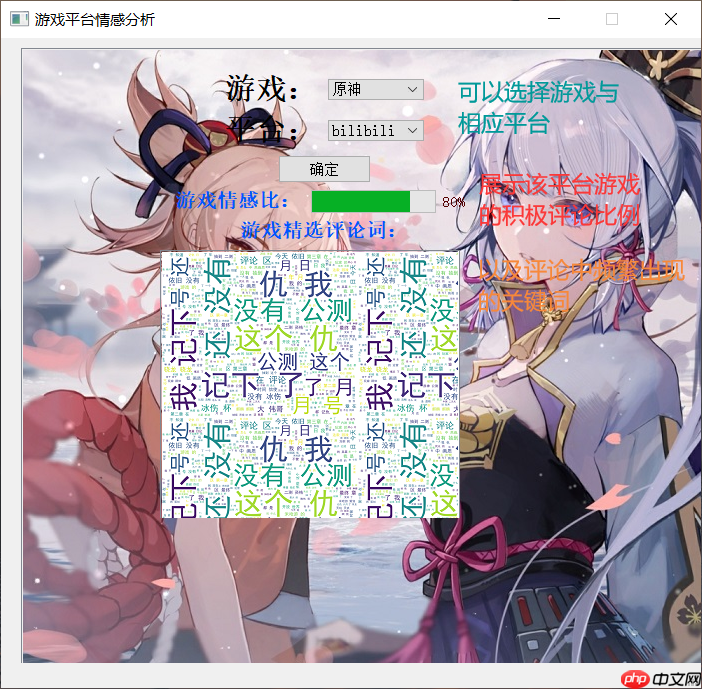
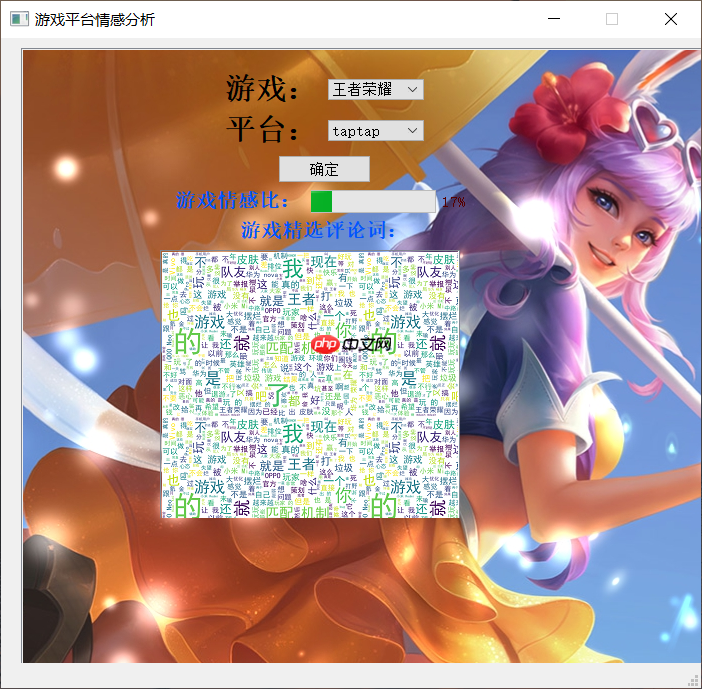
主流互联网游戏评论情感态势分析项目
应用场景:随着游戏市场的崛起,游戏相关从业人员急需了解玩家对游戏的实际体验,以便有针对性地指导游戏运营和开发。与此同时,在舆情信息监测的实际业务中,也存在着信息处理效率过低以及分析结果过于主观等问题。因此,为了解决游戏评论体量大、更新快、含义不清的问题,可基于深度学习模型对玩家评论进行情感分析,做网络游戏舆情态势分析项目。
项目简介:本次项目利用情感分析预训练模型SKEP完成模型训练与预测,利用爬虫程序爬取3个主流平台(TapTap、bilibili、豆瓣)的三个主流互联网游戏(《原神》、《王者荣耀》、《和平精英》)的用户评论进行数据分析,最后利用pyqt5的qtdeisgner进行ui设计,完成数据可视化。
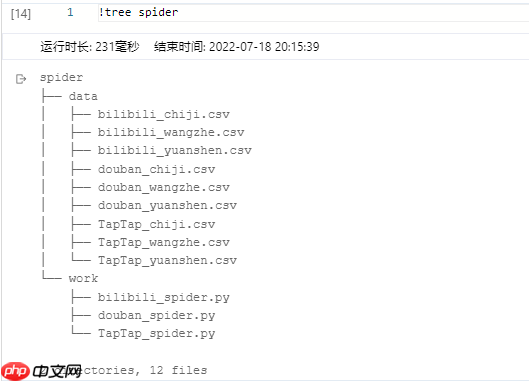
In [15]
!tree
. ├── 4340075.ipynb ├── data │ └── data109273 │ └── taptap_review_ready.csv ├── __pycache__ │ ├── photo.cpython-38.pyc │ └── utils.cpython-37.pyc ├── pyqt5 │ ├── 5.ui │ ├── a1.py │ ├── a1.spec │ ├── ciyun │ │ ├── cb.png │ │ ├── cd.png │ │ ├── ct.png │ │ ├── logo.ico │ │ ├── wb.png │ │ ├── wd.png │ │ ├── wt.png │ │ ├── yb.png │ │ ├── yd.png │ │ ├── yt.png │ │ ├── 原神.jpg │ │ ├── 和平精英.jpg │ │ ├── 新建文本文档.txt │ │ └── 王者.jpg │ ├── dist │ │ └── 游戏平台情感分析.exe │ ├── photo.py │ └── photo.qrc ├── skep_ckpt │ ├── model_0 │ ├── model_100 │ │ ├── model_config.json │ │ ├── model_state.pdparams │ │ ├── tokenizer_config.json │ │ └── vocab.txt │ └── model_200 │ ├── model_config.json │ ├── model_state.pdparams │ ├── tokenizer_config.json │ └── vocab.txt ├── spider │ ├── data │ │ ├── bilibili_chiji.csv │ │ ├── bilibili_wangzhe.csv │ │ ├── bilibili_yuanshen.csv │ │ ├── douban_chiji.csv │ │ ├── douban_wangzhe.csv │ │ ├── douban_yuanshen.csv │ │ ├── TapTap_chiji.csv │ │ ├── TapTap_wangzhe.csv │ │ └── TapTap_yuanshen.csv │ └── work │ ├── bilibili_spider.py │ ├── douban_spider.py │ └── TapTap_spider.py ├── utils.py ├── wordcloud │ ├── bilibili_chiji.png │ ├── bilibili_wangzhe.png │ ├── bilibili_yuanshen.png │ ├── douban_chiji.png │ ├── douban_wangzhe.png │ ├── douban_yuanshen.png │ ├── TapTap_chiji.png │ ├── TapTap_wangzhe.png │ ├── TapTap_yuanshen.png │ └── wordcloud.py ├── work └── 情感分析结果.xlsx 15 directories, 56 files
项目文件:
In [3]
#引入需要的库import paddlenlp as ppnlpimport paddlefrom paddlenlp.datasets import load_datasetfrom paddlenlp.datasets import MapDatasetfrom paddlenlp.data import Stack, Pad, Tupleimport paddle.nn.functional as Fimport numpy as npimport pandas as pdfrom functools import partialimport os
采用数据集为aistdio上“TapTap游戏评论”数据集,链接:https://aistudio.baidu.com/aistudio/datasetdetail/101119
包含TapTap上约300款游戏的标签评论,可用于情感分析的应用,共4888个数据示例
采用该数据集优点:涉及游戏种类较多,训练数据样本较多
缺点:缺乏目前主流互联网游戏相关评论,网络热词较少覆盖,无阴阳怪气评论
In [4]
#读取数据集并划分训练集与验证集df=pd.read_csv('data/data109273/taptap_review_ready.csv')#读取数据集的评论内容review = df.review.tolist()#读取数据集的情感指数sentiment = df.sentiment.tolist()
full_data=[]for i in range(len(review)): #将每条评论内容与情感指数形成字典并添加到full_data列表
dic = {'text':review[i],'label':sentiment[i]}
full_data.append(dic)print(len(full_data))#数据集切分train_ds = MapDataset(full_data[:4400])
dev_ds = MapDataset(full_data[4400:4880])
label_list = ['0', '1']print(len(train_ds))print(train_ds[3])
4888
4400
{'text': '对我来说,这种游戏让我感觉很好。刚开始是因为同学推荐我玩,我玩了一下,哇,真的很好,然后,最近没怎么登录游戏,怎么关服了?这就很难受。希望反斗联盟快速上架,我想玩。等待这种事。对我来说度日如年。我就是觉得那个空投好像有点问题。每次那个空投差不多都在对面基地附近。对面英雄又有点难对付。抢又抢不着。这就特别难受了。', 'label': 1}
In [5]
from paddlenlp.transformers import SkepForSequenceClassification, SkepTokenizer# 加载skep模型model = SkepForSequenceClassification.from_pretrained(pretrained_model_name_or_path="skep_ernie_1.0_large_ch", num_classes=len(label_list))# 加载模型对应的Tokenizer,用于数据预处理tokenizer = SkepTokenizer.from_pretrained(pretrained_model_name_or_path="skep_ernie_1.0_large_ch")
[2022-07-16 15:24:57,173] [ INFO] - Downloading https://paddlenlp.bj.bcebos.com/models/transformers/skep/skep_ernie_1.0_large_ch.pdparams and saved to /home/aistudio/.paddlenlp/models/skep_ernie_1.0_large_ch [2022-07-16 15:24:57,176] [ INFO] - Downloading skep_ernie_1.0_large_ch.pdparams from https://paddlenlp.bj.bcebos.com/models/transformers/skep/skep_ernie_1.0_large_ch.pdparams 100%|██████████| 1238309/1238309 [00:17<00:00, 71093.85it/s] W0716 15:25:14.762745 151 device_context.cc:404] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 10.1 W0716 15:25:14.766620 151 device_context.cc:422] device: 0, cuDNN Version: 7.6. [2022-07-16 15:25:22,647] [ INFO] - Downloading skep_ernie_1.0_large_ch.vocab.txt from https://paddlenlp.bj.bcebos.com/models/transformers/skep/skep_ernie_1.0_large_ch.vocab.txt 100%|██████████| 55/55 [00:00<00:00, 10636.12it/s]
In [6]
#数据预处理def convert_example(example,tokenizer,label_list,max_seq_length=128,is_test=False):
if is_test:
text = example['text'] else:
text = example['text']
label = example['label'] #tokenizer.encode方法实现切分token,映射token ID以及拼接特殊token
encoded_inputs = tokenizer.encode(text=text, max_seq_len=max_seq_length)
input_ids = encoded_inputs["input_ids"]
token_type_ids = encoded_inputs["token_type_ids"] if not is_test:
label_map = {} for (i, l) in enumerate(label_list):
label_map[l] = i # label:情感极性类别
label = np.array([label], dtype="int64") return input_ids, token_type_ids, label else: return input_ids, token_type_ids#数据迭代器def create_dataloader(dataset, trans_fn=None, mode='train', batch_size=1, use_gpu=False, pad_token_id=0, batchify_fn=None):
if trans_fn:
dataset = dataset.map(trans_fn, lazy=True) if mode == 'train' and use_gpu:
sampler = paddle.io.DistributedBatchSampler(dataset=dataset, batch_size=batch_size, shuffle=True) else:
shuffle = True if mode == 'train' else False
sampler = paddle.io.BatchSampler(dataset=dataset, batch_size=batch_size, shuffle=shuffle) #生成一个取样器
dataloader = paddle.io.DataLoader(dataset, batch_sampler=sampler, return_list=True, collate_fn=batchify_fn) return dataloader#将数据处理成模型可读入的数据格式trans_fn = partial(convert_example, tokenizer=tokenizer, label_list=label_list, max_seq_length=128, is_test=False)# 将数据组成批量式数据batchify_fn = lambda samples, fn=Tuple(Pad(axis=0,pad_val=tokenizer.pad_token_id), Pad(axis=0, pad_val=tokenizer.pad_token_id), Stack(dtype="int64")):[data for data in fn(samples)]#batch_size批量数据大小batch_size=64#训练集迭代器train_loader = create_dataloader(train_ds, mode='train', batch_size=batch_size, batchify_fn=batchify_fn, trans_fn=trans_fn)#验证集迭代器dev_loader = create_dataloader(dev_ds, mode='dev', batch_size=batch_size, batchify_fn=batchify_fn, trans_fn=trans_fn)
In [7]
#设置训练参数import timefrom utils import evaluate# 训练轮次epochs = 3# 训练过程中保存模型参数的文件夹ckpt_dir = "skep_ckpt"# len(train_loader)一轮训练所需要的step数num_training_steps = len(train_loader) * epochs# Adam优化器optimizer = paddle.optimizer.AdamW(
learning_rate=2e-5,
parameters=model.parameters())# 交叉熵损失函数criterion = paddle.nn.loss.CrossEntropyLoss()# accuracy评价指标metric = paddle.metric.Accuracy()
In [12]
#模型训练global_step = 0tic_train = time.time()for epoch in range(1, epochs + 1): for step, batch in enumerate(train_loader, start=1):
input_ids, token_type_ids, labels = batch # 喂数据给model
logits = model(input_ids, token_type_ids) # 计算损失函数值
loss = criterion(logits, labels) # 预测分类概率值
probs = F.softmax(logits, axis=1) # 计算acc
correct = metric.compute(probs, labels)
metric.update(correct)
acc = metric.accumulate()
global_step += 1
if global_step % 10 == 0: print( "global step %d, epoch: %d, batch: %d, loss: %.5f, accu: %.5f, speed: %.2f step/s"
% (global_step, epoch, step, loss, acc, 10 / (time.time() - tic_train)))
tic_train = time.time()
# 反向梯度回传,更新参数
loss.backward()
optimizer.step()
optimizer.clear_grad() if global_step % 100 == 0:
save_dir = os.path.join(ckpt_dir, "model_%d" % global_step) if not os.path.exists(save_dir):
os.makedirs(save_dir) # 评估当前训练的模型
evaluate(model, criterion, metric, dev_loader) # 保存当前模型参数等
model.save_pretrained(save_dir) # 保存tokenizer的词表等
tokenizer.save_pretrained(save_dir)
WARNING:root:DataLoader reader thread raised an exception.
Exception in thread Thread-5:
Traceback (most recent call last):
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/threading.py", line 926, in _bootstrap_inner
self.run()
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/threading.py", line 870, in run
self._target(*self._args, **self._kwargs)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dataloader/dataloader_iter.py", line 192, in _thread_loop
six.reraise(*sys.exc_info())
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/six.py", line 719, in reraise
raise value
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dataloader/dataloader_iter.py", line 160, in _thread_loop
batch = self._dataset_fetcher.fetch(indices)
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dataloader/fetcher.py", line 106, in fetch
data = [self.dataset[idx] for idx in batch_indices]
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dataloader/fetcher.py", line 106, in <listcomp>
data = [self.dataset[idx] for idx in batch_indices]
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/datasets/dataset.py", line 181, in __getitem__
idx]) if self._transform_pipline else self.new_data[idx]
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlenlp/datasets/dataset.py", line 172, in _transform
data = fn(data)
File "/tmp/ipykernel_3624/1567443302.py", line 6, in convert_example
text = example['text']
TypeError: tuple indices must be integers or slices, not str
---------------------------------------------------------------------------SystemError Traceback (most recent call last)/tmp/ipykernel_3624/864604143.py in 2 tic_train = time.time() 3 for epoch in range(1, epochs + 1): ----> 4for step, batch in enumerate(train_loader, start=1): 5 input_ids, token_type_ids, labels = batch 6 # 喂数据给model /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dataloader/dataloader_iter.py in __next__(self) 195 try: 196 if in_dygraph_mode(): --> 197 data = self._reader.read_next_var_list() 198 data = _restore_batch(data, self._structure_infos.pop(0)) 199 else: SystemError: (Fatal) Blocking queue is killed because the data reader raises an exception. [Hint: Expected killed_ != true, but received killed_:1 == true:1.] (at /paddle/paddle/fluid/operators/reader/blocking_queue.h:166)
In [8]
# 加载训练好的模型参数params_path = save_dir+'/model_state.pdparams'if params_path and os.path.isfile(params_path): # 加载模型参数
state_dict = paddle.load(params_path)
model.set_dict(state_dict) print("Loaded parameters from %s" % params_path)
Loaded parameters from skep_ckpt/model_200/model_state.pdparams
In [9]
#定义测试集数据的处理函数def convert_example(example,tokenizer,label_list,max_seq_length=512,is_test=False):
encoded_inputs = tokenizer(text=example, max_seq_len=max_seq_length)
input_ids = np.array(encoded_inputs["input_ids"], dtype="int64")
token_type_ids = np.array(encoded_inputs["token_type_ids"], dtype="int64") return input_ids, token_type_ids
In [10]
#定义预测函数def predict(model, data, tokenizer, label_map, batch_size=1):
examples = [] for text in data:
input_ids, token_type_ids = convert_example(text,tokenizer,label_list=label_map.values(),max_seq_length=512,is_test=True)
examples.append((input_ids, token_type_ids)) #划分数据
batches = [
examples[idx:idx + batch_size] for idx in range(0, len(examples), batch_size)
]
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # token type ids
): [data for data in fn(samples)]
#返回结果集
results = []
model.eval() for batch in batches:
input_ids, token_type_ids = batchify_fn(batch)
input_ids = paddle.to_tensor(input_ids)
token_type_ids = paddle.to_tensor(token_type_ids)
logits = model(input_ids, token_type_ids)
probs = F.softmax(logits, axis=1)
idx = paddle.argmax(probs, axis=1).numpy()
idx = idx.tolist()
labels = [label_map[i] for i in idx]
results.extend(labels) return results

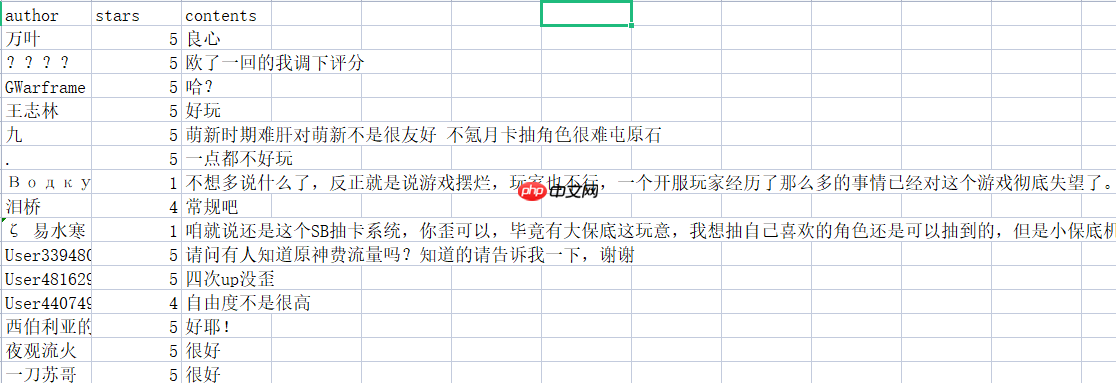
In [11]
#加载测试集import csvwith open('spider/data/bilibili_yuanshen.csv','r',encoding='gbk',errors='ignore')as f:
cs =list(csv.reader(f))#定义存储评论列表comments=[]#csv文件含有表头,故i初始化为1#评论文本在csv文件第三列,故选择cs[i][2]for i in range(1,len(cs)):
comments.append(cs[i][2])print(len(comments))print(comments[1])
997 还一起冒险呢?你有本事放??进去啊?不公测又不给内测资格,??梦中去冒险啊?
In [12]
#对测试集数据情感分析label_map = {0: '0', 1: '1'}
results = predict(model,comments,tokenizer,label_map,batch_size=1)#统计积极评论数量count = 0for result in results: if result == '1':
count =count + 1print(count)#计算积极评论比例positive_ratio = count / len(results)print(positive_ratio)
502 0.5035105315947843
情感分析结果:
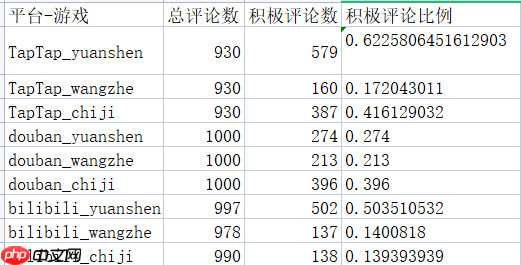
封装为exe文件:
使用pytrhon的pyinstaller直接生成exe文件,需要的相关文件
效果展示: