本文围绕强化学习展开,先介绍状态、动作、智能体等基本概念,再讲解QLearning,包括其通过状态-动作评分表格(Q表格)依据奖励更新的原理及伪代码。最后以CartPole为例,用gym环境实现QLearning代码实战,展示智能体学习平衡倒立摆的过程。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

强化学习导论
1. RL基本概念引入
2. Qlearning讲解
3. CartPole Qlearning代码实战
强化学习是机器学习中很火热的一个领域。相比于传统的监督学习、无监督学习,其是一种独特的学习范式。RL在游戏AI中的应用已经相当成熟,最知名的便是OpenAI。但RL的入门门槛似乎有点高,刚开始就有很多难以理解的概念。涉及到非常多概率统计、微积分的基础知识。实在太劝退了。本文得目的便是引入最少的概念,旨在帮入门者用最短时间完成一个RL项目。熟悉了Qlearning与SARSA的基本流程,再去理解复杂的数学公式,便可轻松上手,水到渠成。
1.RL基本概念引入
- 状态:是对当前环境的一个概括。在游戏AI中,状态就是当前这一帧的换面。Alphago的状态是围棋棋盘。
- 状态空间:所有可能状态组成的集合。
- 动作:做出的某一个决策。在马里奥里是向上跳,或向左走等等。在Dota2中是某一个英雄释放某一个技能,或者位移到某一点。
- 动作空间:所有动作组成的集合。比如马里奥的{上,左,右}
- 智能体:做出动作的主体。
- 策略函数;对应状态,输出一个动作。是智能体与环境交互的实现方式。
- 环境:Dota2地图上,包括野怪、商店、小兵等等都是环境。马里奥的游戏程序就是环境。
- 奖励:每一次智能体做出动作,环境就会给予奖励,以评价这个动作的好坏。就像马里奥吃到的金币。
对以上概念有了初步的了解,就可以开始QLearning。这里并没有提出状态价值函数、动作价值函数等概念,试图最少的概念开始项目。 (推荐一本书:深度强化学习,王树森。Github上有这本书的电子版。这本书是我看的条理最清晰的一本。)
2.QLearning
强化学习得目的,就是要找到一个好的策略函数。以至于智能体能在这个环境中很好的与环境交互。
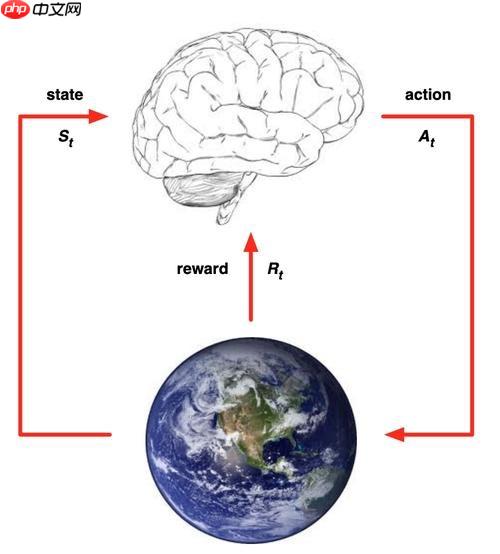
经典的一张图! 我们的智能体在初始时刻有一个状态,随后做出一个动作。环境会根据这个动作,来给予智能体reward。这个reward可能是好的,也可能是差的。同时智能体刷新到一个新的状态。智能体根据这个状态,做出新的动作,同时根据reward学习,调整策略。不断循环下去,最终收敛。
所有的强化学习,都遵从这一流程。那么我的QLearning又是啥呢?学习QLearning有两个点,其一是用查找表的方式来表示策略,另一个是QLearning的表格更新方式。
我们要做出决策,那依据是什么?
最简单的方式就是建议一个状态-动作评分表格。

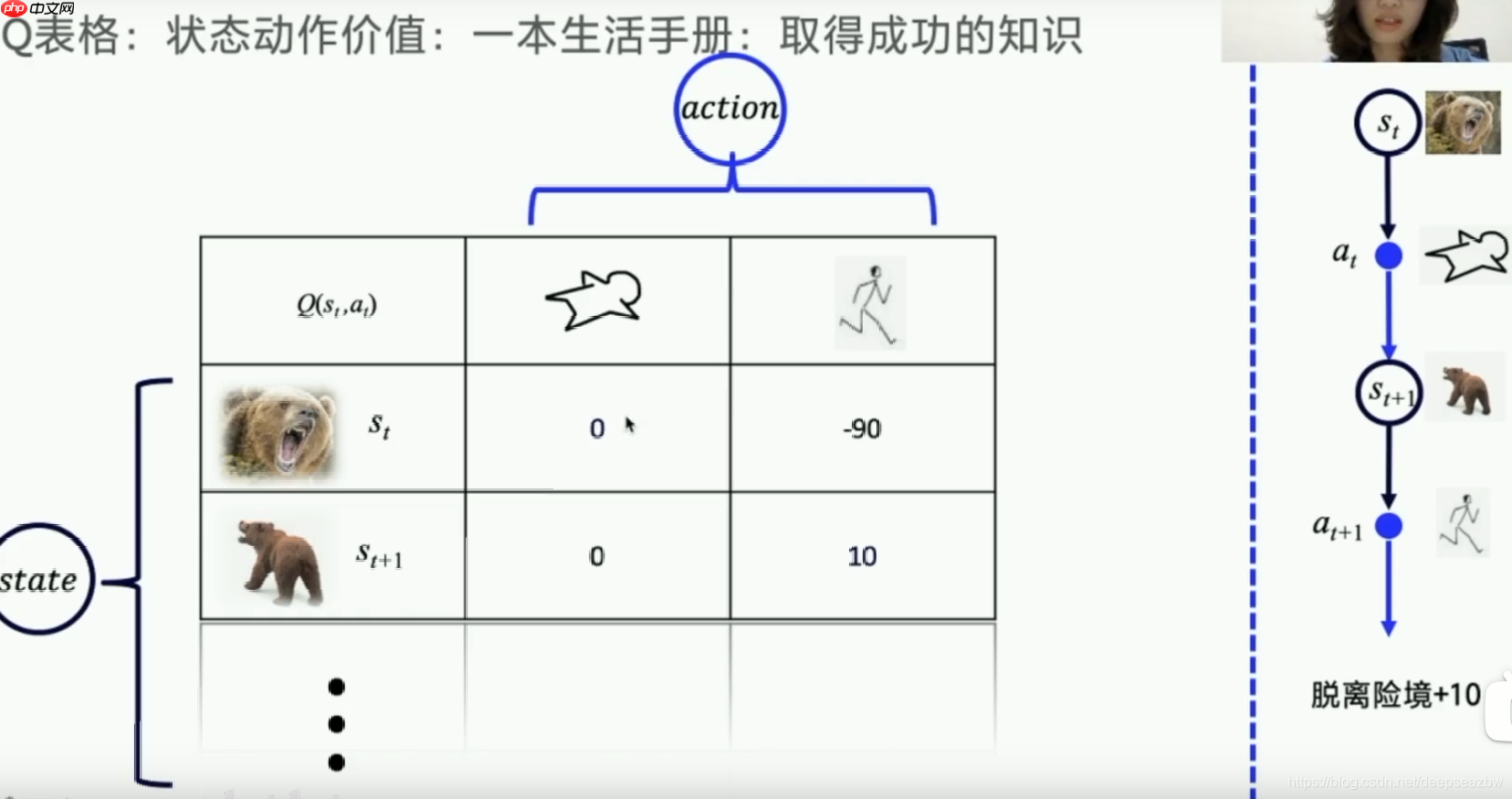
(安利一下科科老师的课,配套推荐的几本书食用更佳。)
这里我们就建立了一个在森林生活的表格,我们根据熊的状态来判断该选取哪一个动作。那么,问题来了:我们咋知道这个表格里哪一个动作评分是咋样的呢?其答案是通过不断尝试,然后一次次根据reward更新。这个表格又称为Q表格。
伪代码:
初始化Q表格,随机每一个状态的Q值
对于每个Episode循环
设置初始状态S
对于每个Step循环
根据Q函数与状态S,选择动作A
做一个动作A,观测R和S'
赋值:Q(S,A)=Q(S,A)+a[R+ymaxQ(S',a)-Q(S,A)]
赋值:S=S'
直到S终止。
'''
再推荐一本书,《白话强化学习与Pytorch》,非常的nice。
S->A->R,S'->A。这里的玄机就在于,用下一刻S'的Q值来更新当前的Q值。因为Q本来就是要预测做了这个动作后,下一刻是好还是坏。那么更新了状态之后,自然会从下一个状态里,选择Q值最高的那个动作。R就是reward,环境给的反馈。有了这些东西,我们开始上路!(有一些前置知识的同学可能会陷入疑问,那个什么动作价值函数,不是和之后每一个动作都相关吗?这里咋就用下一个的来更新呢?我最初学的时候,也陷入了迷惑。但,请先忘记动作价值函数与状态价值函数,撸完这个项目之后,再回过头来仔细思考复杂的积分求和公式。)
3.CartPole QLearning代码实战
- gym gym是OpenAI做的一个开源实验环境。内部集成了很多环境用以开展强化学习。首先介绍的就是我们的CartPole
将这一段代码复制到本地的Python环境,然后运行。
import gym
env = gym.make('CartPole-v0') #创造一个游戏环境state = env.reset() #刷新游戏环境for t in range(100):
env.render()
print(state)
action = env.action_space.sample() #随机从动作空间选取一个动作
state, reward, done, info = env.step(action)
if done:
print('Finished')
break
env.close()
是不是感觉有点炫酷?我们的任务就是控制CartPole这个平衡倒立摆。一旦摆(Pole)的位置超过固定角度,或小车(Cart)超过特殊位置,就视为游戏失败。最终我们会得到一个能坚持很长时间的倒立摆。
#以下代码改编于《边做边学深度强化学习》#导入常用的库#---------------------------------------------------------------------------------------------------------------------------------------------------------------import numpy as npimport matplotlib.pyplot as pltimport gym#定义一些常量#---------------------------------------------------------------------------------------------------------------------------------------------------------------#游戏名称:CartPole-vo 也就是我们的平衡倒立摆ENV = 'CartPole-v0'#离散化区间.小车的状态是有无限多钟,但我们的Q表格里只能表示有限的映射关系。所以将原先连续的一个状态,分为6个区间。NUM_DIGITIZED = 6#GAMMA就是Q学习中的折扣率(0~1),用以表示智能体对长期回报的看法。GAMMA为0,表示只看当前的回报。GAMMA为1,则是极其重视长期回报。GAMMA = 0.99 #学习率。ETA越大,则进行每一步更新时,受reward影响更多。ETA = 0.5 #假如连续控制200次,游戏还没结束,视为成功通关。MAX_STEPS = 200#总共进行2000次训练。(不一定会训练2000次,详情见env.run,有详解。)NUM_EPISODES = 2000
#定义Brain类,智能体与环境交互的主要实现途径。class Brain:
#num_states为4,代表着Cart的位置和速度,Pole的角度和角速度四种状态变量。num_action为2,分别为向左和向右。
#这俩个参数从环境env中获取,然后传入Brain.
def __init__(self, num_states, num_actions):
self.num_actions = num_actions
#创建一个Q表格,也就是我们的Q函数。这里是一个(6^4,2)格式的矩阵。
#其中所有数字为0~1的随机数。这是一种启动方式,也可以全部为0。毕竟只是初始化一个表格,最终都能通过学习收敛。当然,如果通过设置初始化值
#加快收敛速度,也是一个研究方向。
self.q_table = np.random.uniform(low=0, high=1, size=(NUM_DIGITIZED**num_states, num_actions))
#离散化。因为我们的状态是连续的,比如Cart的速度。但表格里只能装下有限的状态,所以通过bins创建一个列表,表示区间。
def bins(self, clip_min, clip_max, num):
#比如小车的极限位置是-2.4到2.4,np.linspace(-2.4, 2.4, 7)[1: -1] =array([-1.6, -0.8, 0. , 0.8, 1.6])
return np.linspace(clip_min, clip_max, num + 1)[1: -1]
#用四个变量(Cart位置、速度Pole位置、速度)提取状态observation
def digitize_state(self, observation):
cart_pos, cart_v, pole_angle, pole_v = observation #离散化变量依靠np.digitize。
#比如:np.digitize(-1.5,[-1.6, -0.8, 0. , 0.8, 1.6])=1
# np.digitize(-2.7,[-1.6, -0.8, 0. , 0.8, 1.6])=0
# np.digitize(-0.77,[-1.6, -0.8, 0. , 0.8, 1.6])=2
#也就是落在这个区间里。虽然边界值区间是(-2.4,-1.6),但是我们认为-∞到-1.6为一个区间。视为游戏结束。
digitized = [
np.digitize(cart_pos, bins = self.bins(-2.4, 2.4, NUM_DIGITIZED)),
np.digitize(cart_v, bins=self.bins(-3.0, 3.0, NUM_DIGITIZED)),
np.digitize(pole_angle, bins=self.bins(-0.5, 0.5, NUM_DIGITIZED)),
np.digitize(pole_v, bins=self.bins(-2.0, 2.0, NUM_DIGITIZED))
] #每一个状态由0~5表示。每一刻的状态由[2,1,2,4]这样的列表表示。
#这里是用1296个数表示状态。(6进制) 其位权就是其索引,就是6的i次方。
#可以理解为对1296个状态进行编码
return sum([x* (NUM_DIGITIZED**i) for i, x in enumerate(digitized)])
#更新Q表格,也就是根据state和reward
def update_Q_table(self, observation, action, reward, observation_next):
#用observation获取编码后的状态,也就是利用前面写好的digitize函数。
state = self.digitize_state(observation) #获取下一次状态(依然是编码之后)。
state_next = self.digitize_state(observation_next) #如之前所述,q_table是一个1296*2的矩阵。用state_next索引到那一行的两个动作。求出两个动作中Q值最大的那个动作。(动作价值)
#这也是区别去SARSA算法的地方。
Max_Q_next = max(self.q_table[state_next][:]) #更新Q表格(这里出现了之前定义的ETA和GAMMA,也就是学习率和折扣率,详情见上面)
self.q_table[state, action] = self.q_table[state, action] + \
ETA * (reward + GAMMA * Max_Q_next - self.q_table[state, action]) #动作决策,输入参数是当前状态,以及是第几轮训练。
def decide_action(self, observation, episode):
#依然是digitize_state函数。(所有拿到的observation观测值都无法直接使用,必须用digitiaze_state转换为可以使用的state)
state = self.digitize_state(observation) #这里实现的是随机选取动作,你可能会疑问,为啥随机选取动作的概率还得随训练轮数变换?
#其意义在于前期让智能体更大胆的尝试,后期学到比较好的Q表格后再应用知识。
#这样更有利于泛化。
epsilon = 0.5 * (1 / (episode + 1)) if epsilon <= np.random.uniform(0, 1):
action = np.argmax(self.q_table[state][:]) else:
action = np.random.choice(self.num_actions)
return action
#定义一个Agent类。你可能觉得我们已经把Brain做好了,多弄个Agent属实多次一举。这里确实Agent没啥用,Agent也只是调用Brain来执行决策以及更新Q表格。#如此定义的好处会在大工程中显现。class Agent:
def __init__(self, num_states, num_actions):
self.brain = Brain(num_states, num_actions) def update_Q_function(self, observation, action, reward, observation_next):
self.brain.update_Q_table(
observation, action, reward, observation_next) def get_action(self, observation, step):
action = self.brain.decide_action(observation, step) return action
#定义环境类class Environment:
def __init__(self):
#利用gym生成环境
self.env = gym.make(ENV) #返回值是4,代表着Cart的位置和速度,Pole的角度和角速度四种状态变量。
num_states = self.env.observation_space.shape[0] #4
#返回值是2,代表着运动。分别为向左和向右。
num_actions = self.env.action_space.n #2
#生成这个环境中的智能体,传入这个智能体的状态变量和动作变量。
self.agent = Agent(num_states, num_actions)
#定义run方法,执行环境与智能体交互。
def run(self):
#一个中间变量,存放已经连续通关的局数。当连续通关10次,结束训练(也有可能直到2000次训练,依然没出现连赢10把。不过连续玩2000局也会自动结束。)。
complete_episodes = 0
#训练是否结束。
is_episode_final = False
#空
frames = []
#开始进行训练,上文中这里设置的是2000(NUM_EPISODES),也就是2000次。
for episode in range(NUM_EPISODES):
#环境重置。要使用gym,必须先调用一次。无论是之前游戏刚结束 还是第一次调用环境。同时会返回一个observation(或者说state)
observation = self.env.reset() #initialize environment
#每一轮控制200(MAX_STEPS)步,结束游戏。
for step in range(MAX_STEPS):
#智能体观测环境,做出决策
action = self.agent.get_action(observation, episode)
#返回值有四个,分别状态、奖励值、游戏状态(False游戏进行,True表示游戏截至)、信息(CartPole这个环境没啥附加信息,别的会有)
#环境给出反馈reward,并更新状态。当然,这次强化学习任务并不需要这里的奖励和信息俩个量。我们另设置了奖励,为一轮游戏结束时结算奖励。
observation_next, _, done, _ = self.env.step(action) #reward and info not need
#游戏结束,则进行结算。
if done:
#小于180步结束游戏时
if step < 180: #奖励值为负
reward = -1
#连续胜场清楚为0
complete_episodes = 0
#超过180步时,注意,这里有时是180步-200步之间停止游戏,也就是未通关,但依然计算reward。这样做是为了加快收敛。
#可以通关调整这个参数,观察结果。增加180到200,会导致收敛缓慢。
else:
#奖励值为正数。
reward = 1
#连续胜场加1。
complete_episodes += 1
#游戏依然进行
else: #奖励值为0
reward = 0
#更新Q表格(所需要的参数为上一次状态,上一次执行的策略,当前状态,奖励值,)
self.agent.update_Q_function(observation, action, reward, observation_next) #更新状态变量
observation = observation_next #如果游戏结束(本轮游戏)
if done: #输出这是第几轮训练,进行了多少步
print('{0} Episode: Finished after {1} time steps'.format(episode, step + 1)) #蹦出循环
break
#整个训练结束(条件为连续10轮超过200步,或者进行了2000轮训练。)
if is_episode_final is True: #跳出循环
break
#当连胜超过10轮, is_episode_final调整为True
if complete_episodes >= 10: print('succeeded for 10 times')
is_episode_final = True
#实例化环境env=Environment() #开始执行交互env.run()
效果展示