






本文介绍了文本的向量表示,包括词向量的概念、将单词转化为向量的方式及词向量具备语义信息的特点。还讲解了独热编码、词袋模型、TF-IDF、N-gram模型等离散表示方法,并指出离散表示存在无法衡量词间关系、数据稀疏、计算复杂等缺点。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

1. 文本的向量表示
- 文本的向量表示:核心的思想就是把文本中的单词(句子)表示成对应的数字
- 文本的向量表示也叫Word Embeding & Word Representation。
- 词向量:Word2vec:CBOW & Skip-Gram (单词的词向量)
1.1 问题引入
1.1.1 计算机中如何表示一个词语?
- 请找出和青蛙(frog)最接近的前7个单词是哪些?

- 计算机系统中学习到单词的向量表示时应满足向量空间分布的相似性。
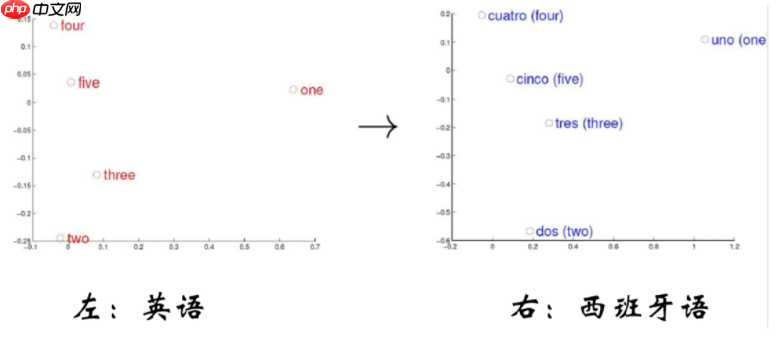
- 计算机系统中学习到单词的向量表示同时应满足向量空间子结构
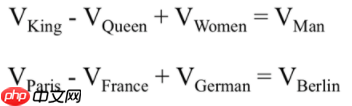
最终目标:单词的向量表示作为机器学习,特别是深度学习的输入和表示空间
1.1.2 词向量的基本概念
- 词向量是一种自然语言中表示单词的方法,即把每个单词表示为N维空间内的一个点,也是高维空间的向量,通过这种方法,可以把自然语言的计算转换为空间向量的计算。
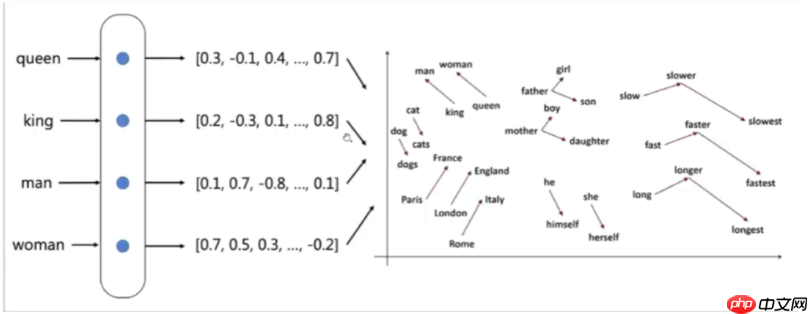
1.1.3 实现词向量的两大挑战

1.1.4 单词转化为向量
- 通过词向量表(Excel,数据库表,text文本文件,numpy文件(npz)进行查询,词向量表中每行存储了单词和对应的向量表示
- 第一列单词的本身
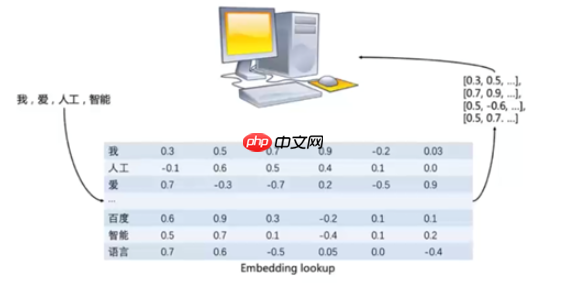
1.1.5 词向量具备语义信息
- 科研人员都有一个共识,可以使用一个单词附近的词语来表示这个单词的含义


- 第二个“苹果”指的是水果苹果
- 第三个根据语境得到“菠萝”指的是一个手机。
- 我们可以使用同样的想法来训练词向量,让这些词向量能够表示语义信息的能力。
1.2 文本的离散表示方法
1.2.1 独热编码(One-Hot Encoder)
- 独热码:只管来说就是有多少个状态就用多少个比特位来表示。而且只有一个比特位为1,其他全为0的一种表示方法。
- 红、黄、蓝。 {红:1,蓝:2,黄:3}
- 红:1 0 0;黄色:0 1 0;蓝色:0 0 1
- 对于文本的向量表示该如何使用独热编码表示:深度学习
深 1 0 0 0 度 0 1 0 0 学 0 0 1 0 习 0 0 0 1
In [2]
# 实现one-hot encoder编码表示"""
性别 区域 成绩
0 0 3
1 1 0
0 2 1
1 0 2
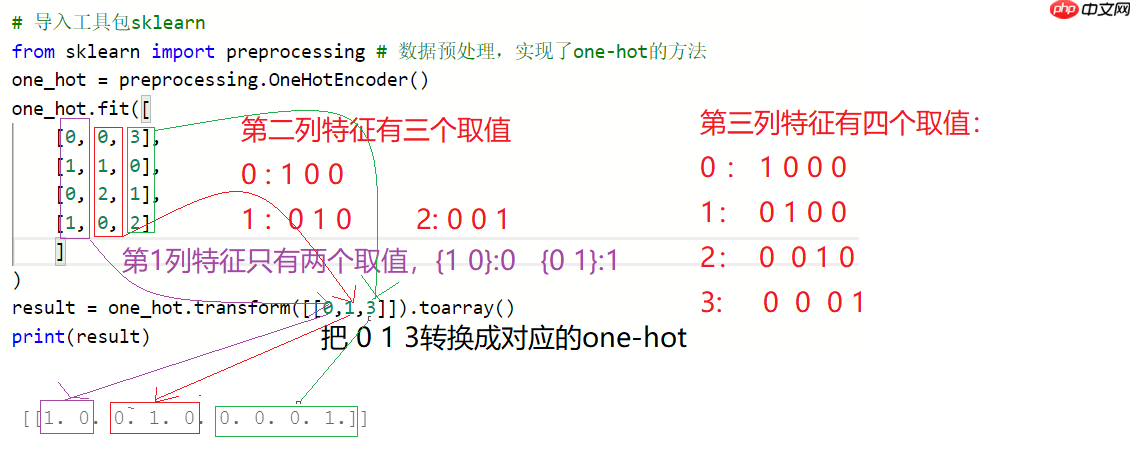
需求:请输出[0, 1, 3]每个数字的one-hot编码表示
"""# 导入工具包sklearnfrom sklearn import preprocessing # 数据预处理,实现了one-hot的方法one_hot = preprocessing.OneHotEncoder()
one_hot.fit([
[0, 0, 3],
[1, 1, 0],
[0, 2, 1],
[1, 0, 2]
]
)
result = one_hot.transform([[0,2,2]]).toarray()print(result)
[[1. 0. 0. 0. 1. 0. 0. 1. 0.]]
1.2.2 词袋模型(Bag of words)
- 词袋模型:将所有的词语装进一个袋子中,不考虑词法和语序的问题,每个单词都是独立的,同时对每个单词统计其在语料库中出现的次数。
- 实现词袋模型的步骤
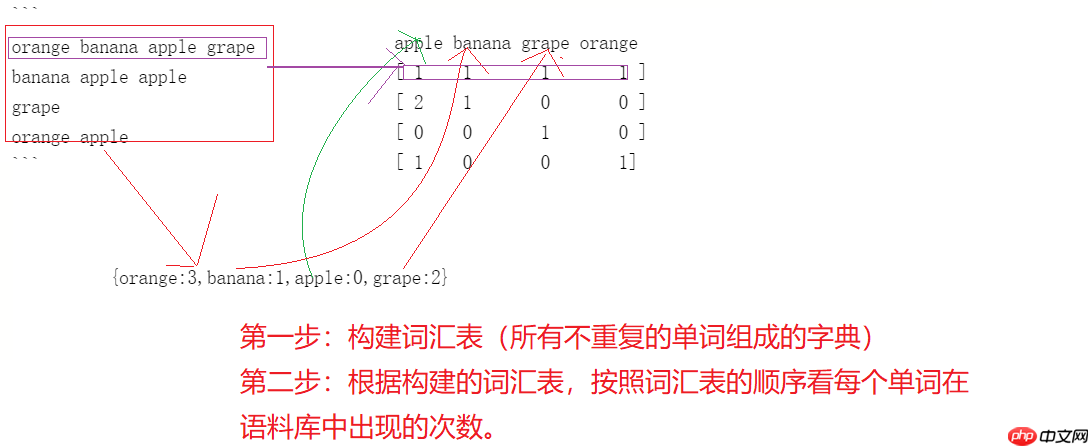
- 构建词汇表:语料库中所有不重复的单词组成的字典
- 构建字典时按照单词的字典(a\b.)顺序组成,{orange:3,banana:1,apple:0,grape:2}
orange banana apple grape banana apple apple grapeorange apple
- 把每个句子转化成对应的向量表示
In [11]
# 1. 导入工具库from sklearn.feature_extraction.text import CountVectorizer # 计数texts = [ "orange banana apple grape", "banana apple apple apple", "grape", "orange apple", ] count_vec = CountVectorizer() # 创建词袋模型的对象count_vec_fit = count_vec.fit_transform(texts) # 训练语料库print(count_vec.vocabulary_) # 输出根据语料库构建的词汇表print(count_vec_fit.toarray()) # 把文本转换成对应的向量表示
{'orange': 3, 'banana': 1, 'apple': 0, 'grape': 2}
[[1 1 1 1]
[3 1 0 0]
[0 0 1 0]
[1 0 0 1]]
1.2.3 词频-逆文本频率
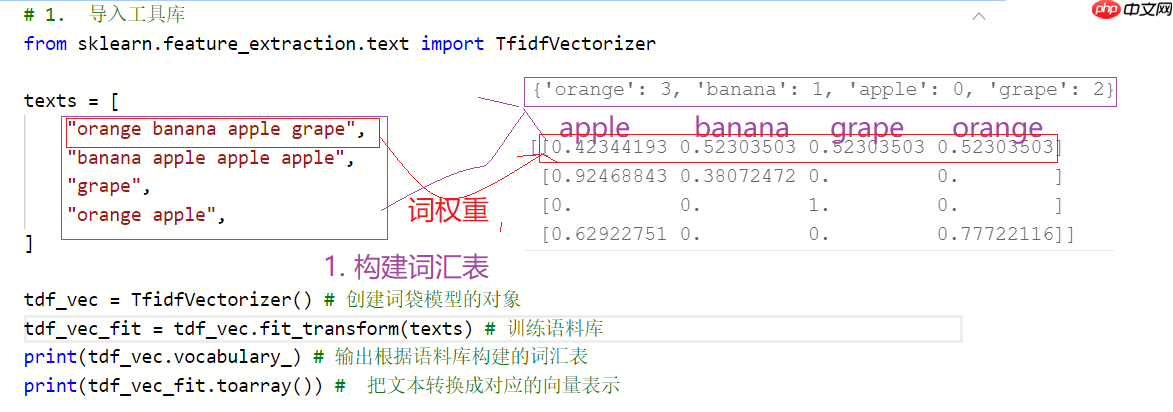
- TF-IDF是一种用于咨询检索与文本挖掘的常用加权技术,词袋模型使用的是词频,TF-IDF用的是词的权重。
- 词频:指的是一个给定的词语在文本中出现的频率。
- 逆向文本频率:是一个词语普遍重要性的度量。
注意事项:如果一个单词在句子中出现的频率非常的高,说明该单词具有一定的重要性,但如果一个词语在整篇语料库中出现的频率都很高,就说明这个单词很普遍(常见)。
In [12]
# 1. 导入工具库from sklearn.feature_extraction.text import TfidfVectorizer texts = [ "orange banana apple grape", "banana apple apple apple", "grape", "orange apple", ] tdf_vec = TfidfVectorizer() # 创建词袋模型的对象tdf_vec_fit = tdf_vec.fit_transform(texts) # 训练语料库print(tdf_vec.vocabulary_) # 输出根据语料库构建的词汇表print(tdf_vec_fit.toarray()) # 把文本转换成对应的向量表示
{'orange': 3, 'banana': 1, 'apple': 0, 'grape': 2}
[[0.42344193 0.52303503 0.52303503 0.52303503]
[0.92468843 0.38072472 0. 0. ]
[0. 0. 1. 0. ]
[0.62922751 0. 0. 0.77722116]]
1.2.4 N-gram模型(语言模型)
- 考虑了词语之间的顺序
- 缺点:词表的维度会随之单词的增加而急剧增加,在实际的工作中,n=4以上的情形是没有用过的,因为算法的复杂度太高。
1.2.4 bi-gram的表示方法
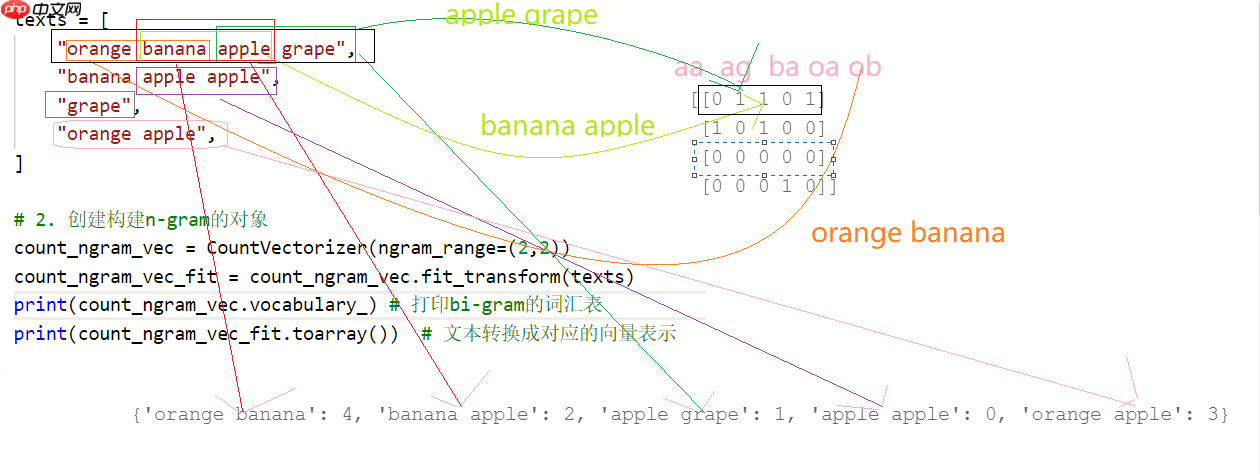
1.2.6 tri-gram的表示方法
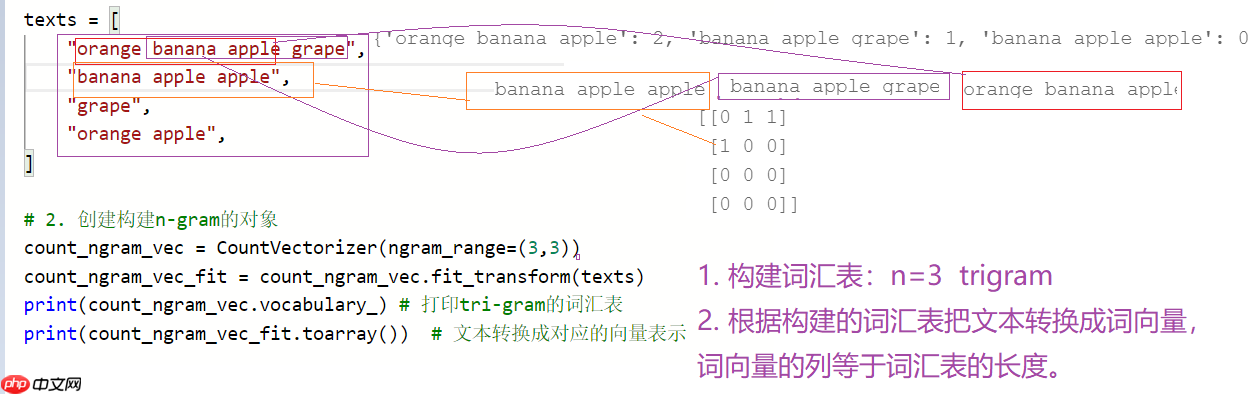
In [13]
from sklearn.feature_extraction.text import CountVectorizer # 词频的统计可以实现n-gram# 1. 构建语料库texts = [ "orange banana apple grape", "banana apple apple", "grape", "orange apple", ]# 2. 创建构建n-gram的对象count_ngram_vec = CountVectorizer(ngram_range=(2,3)) count_ngram_vec_fit = count_ngram_vec.fit_transform(texts)print(count_ngram_vec.vocabulary_) # 打印bi-gram的词汇表print(count_ngram_vec_fit.toarray()) # 文本转换成对应的向量表示
{'orange banana': 6, 'banana apple': 2, 'apple grape': 1, 'orange banana apple': 7, 'banana apple grape': 4, 'apple apple': 0, 'banana apple apple': 3, 'orange apple': 5}
[[0 1 1 0 1 0 1 1]
[1 0 1 1 0 0 0 0]
[0 0 0 0 0 0 0 0]
[0 0 0 0 0 1 0 0]]
1.3 总结
1.3.1 离散的文本向量表示方法的缺点
- 无法衡量词向量词向量之间的关系
酒店 1 0 0 宾馆 0 1 0 旅社 0 0 1
- 无论使用那种度量方式都不能表示这三个单词之间的关系
- 数据非常稀疏
- N-gram模型的计算复杂度太高




























