






本文介绍讯飞学术论文分类挑战赛的Paddle版本Baseline,提交分数0.8+。赛题为英文长文本分类,含5W篇训练论文(带类别)和1W篇测试论文(需预测类别)。Baseline基于PaddleHub预训练模型微调,包括数据读取处理(拼接标题和摘要等)、模型构建(选ernie_v2_eng_large等)、训练验证及预测提交等步骤,可优化空间大。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

【Paddle打比赛】讯飞赛题—学术论文分类挑战赛0.8+Baseline
一.项目介绍
1.项目简介:
本项目为讯飞赛题-学术论文分类挑战赛paddle版本Baseline,提交分数0.8+。目前可优化的空间还比较大,可以多做尝试进行提升。感兴趣的也可以进行迁移用到类似的文本分类项目中去。
2.赛事地址:(详情可前往具体比赛页面查看)
学术论文分类挑战赛
3.赛题任务简介:
该赛题为一道较常规的英文长文本分类赛题。其中训练集5W篇论文。其中每篇论文都包含论文id、标题、摘要和类别四个字段。测试集1W篇论文。其中每篇论文都包含论文id、标题、摘要,不包含论文类别字段。选手需要利用论文信息:论文id、标题、摘要,划分论文具体类别。同时一篇论文只属于一个类别,并不存在一篇论文属于多个类别的复杂情况。评价标准采用准确率指标,需特别注意赛题规定不可使用除提供的数据外的其它数据。
4.Baseline思路:
本次Baseline主要基于PaddleHub通过预训练模型在比赛数据集上的微调完成论文文本分类模型训练,最终对测试数据集进行预测并导出提交结果文件完成赛题任务。需注意本项目代码需要使用GPU环境来运行,若显存不足,请改小batchsize。

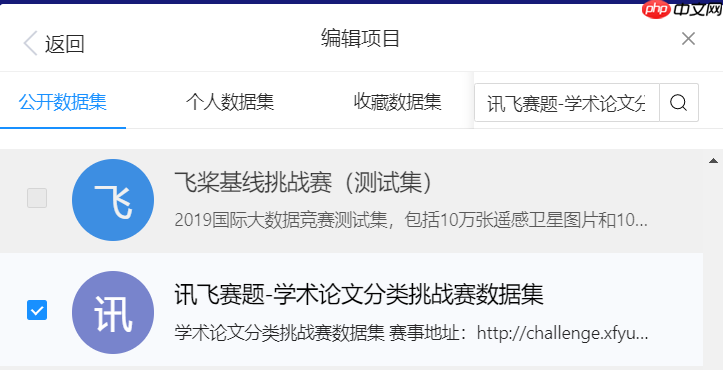
比赛相关数据集已经上传AI Studio,在数据集那搜索‘讯飞赛题-学术论文分类挑战赛数据集’后添加即可。
二.数据读取和处理
2.1 读取数据并查看
# 解压比赛数据集%cd /home/aistudio/data/data100192/ !unzip data.zip
/home/aistudio/data/data100192 Archive: data.zip inflating: sample_submit.csv inflating: test.csv inflating: train.csv
# 读取数据集import pandas as pd
train = pd.read_csv('train.csv', sep='\t') # 有标签的训练数据文件test = pd.read_csv('test.csv', sep='\t') # 要进行预测的测试数据文件sub = pd.read_csv('sample_submit.csv') # 提交结果文件范例
# 查看训练数据前5条train.head()
paperid title \
0 train_00000 Hard but Robust, Easy but Sensitive: How Encod...
1 train_00001 An Easy-to-use Real-world Multi-objective Opti...
2 train_00002 Exploration of reproducibility issues in scien...
3 train_00003 Scheduled Sampling for Transformers
4 train_00004 Hybrid Forests for Left Ventricle Segmentation...
abstract categories
0 Neural machine translation (NMT) typically a... cs.CL
1 Although synthetic test problems are widely ... cs.NE
2 This is the first part of a small-scale expl... cs.DL
3 Scheduled sampling is a technique for avoidi... cs.CL
4 Machine learning models produce state-of-the... cs.CV
# 查看训练数据文件信息train.info()
RangeIndex: 50000 entries, 0 to 49999 Data columns (total 4 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 paperid 50000 non-null object 1 title 50000 non-null object 2 abstract 50000 non-null object 3 categories 50000 non-null object dtypes: object(4) memory usage: 1.5+ MB
# 查看训练数据中总类别分布情况train['categories'].value_counts()
cs.CV 11038 cs.CL 4260 cs.NI 3218 cs.CR 2798 cs.AI 2706 cs.DS 2509 cs.DC 1994 cs.SE 1940 cs.RO 1884 cs.LO 1741 cs.LG 1352 cs.SY 1292 cs.CY 1228 cs.DB 998 cs.GT 984 cs.HC 943 cs.PL 841 cs.IR 770 cs.CC 719 cs.NE 704 cs.CG 683 cs.OH 677 cs.SI 603 cs.DL 537 cs.DM 523 cs.FL 469 cs.AR 363 cs.CE 362 cs.GR 314 cs.MM 261 cs.ET 230 cs.MA 210 cs.NA 176 cs.SC 172 cs.SD 140 cs.PF 139 cs.MS 105 cs.OS 99 cs.GL 18 Name: categories, dtype: int64
# 查看要进行预测的测试数据前5条test.head()
paperid title \
0 test_00000 Analyzing 2.3 Million Maven Dependencies to Re...
1 test_00001 Finding Higher Order Mutants Using Variational...
2 test_00002 Automatic Detection of Search Tactic in Indivi...
3 test_00003 Polygon Simplification by Minimizing Convex Co...
4 test_00004 Differentially passive circuits that switch an...
abstract
0 This paper addresses the following question:...
1 Mutation testing is an effective but time co...
2 Information seeking process is an important ...
3 Let $P$ be a polygon with $r>0$ reflex verti...
4 The concept of passivity is central to analy...
# 查看测试数据文件信息test.info()
RangeIndex: 10000 entries, 0 to 9999 Data columns (total 3 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 paperid 10000 non-null object 1 title 10000 non-null object 2 abstract 10000 non-null object dtypes: object(3) memory usage: 234.5+ KB
2.2 数据处理及划分训练和验证集
# 对数据集进行处理,拼接论文标题和摘要,处理为text_a,label格式train['text_a'] = train['title'] + ' ' + train['abstract'] test['text_a'] = test['title'] + ' ' + test['abstract'] train['label'] = train['categories'] train = train[['text_a', 'label']]
# 查看处理后的数据前5条,看是否符合text_a,label格式train.head()
text_a label 0 Hard but Robust, Easy but Sensitive: How Encod... cs.CL 1 An Easy-to-use Real-world Multi-objective Opti... cs.NE 2 Exploration of reproducibility issues in scien... cs.DL 3 Scheduled Sampling for Transformers Schedule... cs.CL 4 Hybrid Forests for Left Ventricle Segmentation... cs.CV
# 划分训练和验证集:# 将50000条有标签的训练数据直接根据索引按9:1划分为训练和验证集train_data = train[['text_a', 'label']][:45000]
valid_data = train[['text_a', 'label']][45000:]# 对数据进行随机打乱from sklearn.utils import shuffle
train_data = shuffle(train_data)
valid_data = shuffle(valid_data)# 保存训练和验证集文件train_data.to_csv('train_data.csv', sep='\t', index=False)
valid_data.to_csv('valid_data.csv', sep='\t', index=False)
三.基于PaddleHub构建基线模型
PaddleHub可以便捷地获取PaddlePaddle生态下的预训练模型,完成模型的管理和一键预测。配合使用Fine-tune API,可以基于大规模预训练模型快速完成迁移学习,让预训练模型能更好地服务于用户特定场景的应用。
3.1 前置环境准备
# 下载最新版本的paddlehub!pip install -U paddlehub -i https://pypi.tuna.tsinghua.edu.cn/simple
# 导入paddlehub和paddle包import paddlehub as hubimport paddle
3.2 选取预训练模型
# 设置要求进行论文分类的39个类别label_list=list(train.label.unique())print(label_list)
label_map = {
idx: label_text for idx, label_text in enumerate(label_list)
}print(label_map)
['cs.CL', 'cs.NE', 'cs.DL', 'cs.CV', 'cs.LG', 'cs.DS', 'cs.IR', 'cs.RO', 'cs.DM', 'cs.CR', 'cs.AR', 'cs.NI', 'cs.AI', 'cs.SE', 'cs.CG', 'cs.LO', 'cs.SY', 'cs.GR', 'cs.PL', 'cs.SI', 'cs.OH', 'cs.HC', 'cs.MA', 'cs.GT', 'cs.ET', 'cs.FL', 'cs.CC', 'cs.DB', 'cs.DC', 'cs.CY', 'cs.CE', 'cs.MM', 'cs.NA', 'cs.PF', 'cs.OS', 'cs.SD', 'cs.SC', 'cs.MS', 'cs.GL']
{0: 'cs.CL', 1: 'cs.NE', 2: 'cs.DL', 3: 'cs.CV', 4: 'cs.LG', 5: 'cs.DS', 6: 'cs.IR', 7: 'cs.RO', 8: 'cs.DM', 9: 'cs.CR', 10: 'cs.AR', 11: 'cs.NI', 12: 'cs.AI', 13: 'cs.SE', 14: 'cs.CG', 15: 'cs.LO', 16: 'cs.SY', 17: 'cs.GR', 18: 'cs.PL', 19: 'cs.SI', 20: 'cs.OH', 21: 'cs.HC', 22: 'cs.MA', 23: 'cs.GT', 24: 'cs.ET', 25: 'cs.FL', 26: 'cs.CC', 27: 'cs.DB', 28: 'cs.DC', 29: 'cs.CY', 30: 'cs.CE', 31: 'cs.MM', 32: 'cs.NA', 33: 'cs.PF', 34: 'cs.OS', 35: 'cs.SD', 36: 'cs.SC', 37: 'cs.MS', 38: 'cs.GL'}
# 选择ernie_v2_eng_large预训练模型并设置微调任务为39分类任务model = hub.Module(name="ernie_v2_eng_large", task='seq-cls', num_classes=39, label_map=label_map) # 在多分类任务中,num_classes需要显式地指定类别数,此处根据数据集设置为39
Download https://bj.bcebos.com/paddlehub/paddlehub_dev/ernie_v2_eng_large_2.0.2.tar.gz [##################################################] 100.00% Decompress /home/aistudio/.paddlehub/tmp/tmp8enjb395/ernie_v2_eng_large_2.0.2.tar.gz [##################################################] 100.00%
[2021-08-01 17:43:16,200] [ INFO] - Successfully installed ernie_v2_eng_large-2.0.2
[2021-08-01 17:43:16,203] [ INFO] - Downloading https://paddlenlp.bj.bcebos.com/models/transformers/ernie_v2_large/ernie_v2_eng_large.pdparams and saved to /home/aistudio/.paddlenlp/models/ernie-2.0-large-en
[2021-08-01 17:43:16,205] [ INFO] - Downloading ernie_v2_eng_large.pdparams from https://paddlenlp.bj.bcebos.com/models/transformers/ernie_v2_large/ernie_v2_eng_large.pdparams
100%|██████████| 1309198/1309198 [00:19<00:00, 68253.50it/s]
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1297: UserWarning: Skip loading for classifier.weight. classifier.weight is not found in the provided dict.
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1297: UserWarning: Skip loading for classifier.bias. classifier.bias is not found in the provided dict.
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
hub.Module的参数用法如下:
- name:模型名称,可以选择ernie,ernie_tiny,bert-base-cased, bert-base-chinese, roberta-wwm-ext,roberta-wwm-ext-large等。
- task:fine-tune任务。此处为seq-cls,表示文本分类任务。
- num_classes:表示当前文本分类任务的类别数,根据具体使用的数据集确定,默认为2。
PaddleHub还提供BERT等模型可供选择, 当前支持文本分类任务的模型对应的加载示例如下:
| 模型名 | PaddleHub Module |
|---|---|
| ERNIE, Chinese | hub.Module(name='ernie') |
| ERNIE tiny, Chinese | hub.Module(name='ernie_tiny') |
| ERNIE 2.0 Base, English | hub.Module(name='ernie_v2_eng_base') |
| ERNIE 2.0 Large, English | hub.Module(name='ernie_v2_eng_large') |
| BERT-Base, English Cased | hub.Module(name='bert-base-cased') |
| BERT-Base, English Uncased | hub.Module(name='bert-base-uncased') |
| BERT-Large, English Cased | hub.Module(name='bert-large-cased') |
| BERT-Large, English Uncased | hub.Module(name='bert-large-uncased') |
| BERT-Base, Multilingual Cased | hub.Module(nane='bert-base-multilingual-cased') |
| BERT-Base, Multilingual Uncased | hub.Module(nane='bert-base-multilingual-uncased') |
| BERT-Base, Chinese | hub.Module(name='bert-base-chinese') |
| BERT-wwm, Chinese | hub.Module(name='chinese-bert-wwm') |
| BERT-wwm-ext, Chinese | hub.Module(name='chinese-bert-wwm-ext') |
| RoBERTa-wwm-ext, Chinese | hub.Module(name='roberta-wwm-ext') |
| RoBERTa-wwm-ext-large, Chinese | hub.Module(name='roberta-wwm-ext-large') |
| RBT3, Chinese | hub.Module(name='rbt3') |
| RBTL3, Chinese | hub.Module(name='rbtl3') |
| ELECTRA-Small, English | hub.Module(name='electra-small') |
| ELECTRA-Base, English | hub.Module(name='electra-base') |
| ELECTRA-Large, English | hub.Module(name='electra-large') |
| ELECTRA-Base, Chinese | hub.Module(name='chinese-electra-base') |
| ELECTRA-Small, Chinese | hub.Module(name='chinese-electra-small') |
通过以上的一行代码,model初始化为一个适用于文本分类任务的模型,为ERNIE的预训练模型后拼接上一个全连接网络(Full Connected)。
3.3 加载并处理数据
# 统计数据的长度,便于确定max_seq_lenprint('训练数据集拼接后的标题和摘要的最大长度为{}'.format(train['text_a'].map(lambda x:len(x)).max()))print('训练数据集拼接后的标题和摘要的最小长度为{}'.format(train['text_a'].map(lambda x:len(x)).min()))print('训练数据集拼接后的标题和摘要的平均长度为{}'.format(train['text_a'].map(lambda x:len(x)).mean()))print('测试数据集拼接后的标题和摘要的最大长度为{}'.format(test['text_a'].map(lambda x:len(x)).max()))print('测试数据集拼接后的标题和摘要的最小长度为{}'.format(test['text_a'].map(lambda x:len(x)).min()))print('测试数据集拼接后的标题和摘要的平均长度为{}'.format(test['text_a'].map(lambda x:len(x)).mean()))
训练数据集拼接后的标题和摘要的最大长度为3713 训练数据集拼接后的标题和摘要的最小长度为69 训练数据集拼接后的标题和摘要的平均长度为1131.28478 测试数据集拼接后的标题和摘要的最大长度为3501 测试数据集拼接后的标题和摘要的最小长度为74 测试数据集拼接后的标题和摘要的平均长度为1127.0977
import os, io, csvfrom paddlehub.datasets.base_nlp_dataset import InputExample, TextClassificationDataset# 数据集存放位置DATA_DIR="/home/aistudio/data/data100192/"
# 对训练数据进行处理,处理为模型可接受的格式class Papers(TextClassificationDataset):
def __init__(self, tokenizer, mode='train', max_seq_len=128):
if mode == 'train':
data_file = 'train_data.csv'
elif mode == 'dev':
data_file = 'valid_data.csv'
super(Papers, self).__init__(
base_path=DATA_DIR,
data_file=data_file,
tokenizer=tokenizer,
max_seq_len=max_seq_len,
mode=mode,
is_file_with_header=True,
label_list=label_list
) # 解析文本文件里的样本
def _read_file(self, input_file, is_file_with_header: bool = False):
if not os.path.exists(input_file): raise RuntimeError("The file {} is not found.".format(input_file)) else: with io.open(input_file, "r", encoding="UTF-8") as f:
reader = csv.reader(f, delimiter="\t") # ‘\t’分隔数据
examples = []
seq_id = 0
header = next(reader) if is_file_with_header else None
for line in reader:
example = InputExample(guid=seq_id, text_a=line[0], label=line[1])
seq_id += 1
examples.append(example) return examples# 最大序列长度max_seq_len是可以调整的参数,建议值128,根据任务文本长度不同可以调整该值,但最大不超过512。此处由于文本较长故设置为512。train_dataset = Papers(model.get_tokenizer(), mode='train', max_seq_len=512)
dev_dataset = Papers(model.get_tokenizer(), mode='dev', max_seq_len=512)# 处理完后查看数据中前2条for e in train_dataset.examples[:2]: print(e)for e in dev_dataset.examples[:2]: print(e)
[2021-08-01 17:44:12,576] [ INFO] - Downloading vocab.txt from https://paddlenlp.bj.bcebos.com/models/transformers/ernie_v2_large/vocab.txt 100%|██████████| 227/227 [00:00<00:00, 2484.96it/s] [2021-08-01 17:46:28,717] [ INFO] - Found /home/aistudio/.paddlenlp/models/ernie-2.0-large-en/vocab.txt
text=Enforcing Label and Intensity Consistency for IR Target Detection This study formulates the IR target detection as a binary classification problem of each pixel. Each pixel is associated with a label which indicates whether it is a target or background pixel. The optimal label set for all the pixels of an image maximizes aposteriori distribution of label configuration given the pixel intensities. The posterior probability is factored into (or proportional to) a conditional likelihood of the intensity values and a prior probability of label configuration. Each of these two probabilities are computed assuming a Markov Random Field (MRF) on both pixel intensities and their labels. In particular, this study enforces neighborhood dependency on both intensity values, by a Simultaneous Auto Regressive (SAR) model, and on labels, by an Auto-Logistic model. The parameters of these MRF models are learned from labeled examples. During testing, an MRF inference technique, namely Iterated Conditional Mode (ICM), produces the optimal label for each pixel. The detection performance is further improved by incorporating temporal information through background subtraction. High performances on benchmark datasets demonstrate effectiveness of this method for IR target detection. label=cs.CV text=Saliency Preservation in Low-Resolution Grayscale Images Visual salience detection originated over 500 million years ago and is one of nature's most efficient mechanisms. In contrast, many state-of-the-art computational saliency models are complex and inefficient. Most saliency models process high-resolution color (HC) images; however, insights into the evolutionary origins of visual salience detection suggest that achromatic low-resolution vision is essential to its speed and efficiency. Previous studies showed that low-resolution color and high-resolution grayscale images preserve saliency information. However, to our knowledge, no one has investigated whether saliency is preserved in low-resolution grayscale (LG) images. In this study, we explain the biological and computational motivation for LG, and show, through a range of human eye-tracking and computational modeling experiments, that saliency information is preserved in LG images. Moreover, we show that using LG images leads to significant speedups in model training and detection times and conclude by proposing LG images for fast and efficient salience detection. label=cs.CV text=RT-Gang: Real-Time Gang Scheduling Framework for Safety-Critical Systems In this paper, we present RT-Gang: a novel real-time gang scheduling framework that enforces a one-gang-at-a-time policy. We find that, in a multicore platform, co-scheduling multiple parallel real-time tasks would require highly pessimistic worst-case execution time (WCET) and schedulability analysis - even when there are enough cores - due to contention in shared hardware resources such as cache and DRAM controller. In RT-Gang, all threads of a parallel real-time task form a real-time gang and the scheduler globally enforces the one-gang-at-a-time scheduling policy to guarantee tight and accurate task WCET. To minimize under-utilization, we integrate a state-of-the-art memory bandwidth throttling framework to allow safe execution of best-effort tasks. Specifically, any idle cores, if exist, are used to schedule best-effort tasks but their maximum memory bandwidth usages are strictly throttled to tightly bound interference to real-time gang tasks. We implement RT-Gang in the Linux kernel and evaluate it on two representative embedded multicore platforms using both synthetic and real-world DNN workloads. The results show that RT-Gang dramatically improves system predictability and the overhead is negligible. label=cs.DC text=AI Enabling Technologies: A Survey Artificial Intelligence (AI) has the opportunity to revolutionize the way the United States Department of Defense (DoD) and Intelligence Community (IC) address the challenges of evolving threats, data deluge, and rapid courses of action. Developing an end-to-end artificial intelligence system involves parallel development of different pieces that must work together in order to provide capabilities that can be used by decision makers, warfighters and analysts. These pieces include data collection, data conditioning, algorithms, computing, robust artificial intelligence, and human-machine teaming. While much of the popular press today surrounds advances in algorithms and computing, most modern AI systems leverage advances across numerous different fields. Further, while certain components may not be as visible to end-users as others, our experience has shown that each of these interrelated components play a major role in the success or failure of an AI system. This article is meant to highlight many of these technologies that are involved in an end-to-end AI system. The goal of this article is to provide readers with an overview of terminology, technical details and recent highlights from academia, industry and government. Where possible, we indicate relevant resources that can be used for further reading and understanding. label=cs.AI
3.4 选择优化策略和运行配置
# 优化器的选择optimizer = paddle.optimizer.AdamW(learning_rate=4e-6, parameters=model.parameters())# 运行配置trainer = hub.Trainer(model, optimizer, checkpoint_dir='./ckpt', use_gpu=True, use_vdl=True) # fine-tune任务的执行者
3.5 模型训练和验证
trainer.train(train_dataset, epochs=4, batch_size=12, eval_dataset=dev_dataset, save_interval=1) # 配置训练参数,启动训练,并指定验证集
trainer.train 主要控制具体的训练过程,包含以下可控制的参数:
- train_dataset: 训练时所用的数据集;
- epochs: 训练轮数;
- batch_size: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
- num_workers: works的数量,默认为0;
- eval_dataset: 验证集;
- log_interval: 打印日志的间隔, 单位为执行批训练的次数。
- save_interval: 保存模型的间隔频次,单位为执行训练的轮数。
3.6 模型预测与保存结果文件
# 对测试集进行预测import numpy as np# 将输入数据处理为list格式new = pd.DataFrame(columns=['text'])
new['text'] = test["text_a"]# 首先将pandas读取的数据转化为arraydata_array = np.array(new)# 然后转化为list形式data_list =data_array.tolist()# 定义要进行分类的类别label_list=list(train.label.unique())
label_map = {
idx: label_text for idx, label_text in enumerate(label_list)
}# 加载训练好的模型model = hub.Module(
name="ernie_v2_eng_large",
version='2.0.2',
task='seq-cls',
load_checkpoint='./ckpt/best_model/model.pdparams',
num_classes=39,
label_map=label_map)# 对测试集数据进行预测predictions = model.predict(data_list, max_seq_len=512, batch_size=2, use_gpu=True)
# 生成要提交的结果文件sub = pd.read_csv('./sample_submit.csv')
sub['categories'] = predictions
sub.to_csv('submission.csv',index=False)
# 将结果文件移动到work目录下便于保存!cp -r /home/aistudio/data/data100192/submission.csv /home/aistudio/work/
预测完成后,在左侧进入data/data100192/,下载生成结果文件submission.csv后提交即可,分数为0.8+。目前可改进提升的空间还比较大,感兴趣的可以多做尝试!





























