






本文基于PaddlePaddle复现TabNet网络,该网络可处理表格数据,支持端到端学习,通过顺序注意实现特征选择与可解释性。复现项目在Forest Cover Type数据集精度达0.96777,超PyTorch版本。文中介绍模型结构、数据集、环境配置、训练测试步骤,还总结了复现中自定义算子等问题及解决方法。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

表格学习:基于飞桨复现TabNet网络
1.简介
本项目基于PaddlePaddle复现《 TabNet: Attentive Interpretable Tabular Learning》论文。通常表格数据都是使用XGBoost和LightGBM这类提升树模型来获得较好的性能。该论文提出了一种使用DNN来处理表格数据,并取得了不错的效果。该项目可使用在机器学习方向,表格数据的分类与回归。如鸢尾花分类,房价预测等案例。也可以尝试使用这个网络去打一些机器学习的比赛。
论文地址:
https://arxiv.org/pdf/1908.07442v5.pdf
本项目github地址:
https://github.com/txyugood/tabnet
参考项目:
https://github.com/dreamquark-ai/tabnet
通过该项目中的issue可知,该项目在Forest Cover Type数据集上的精度为0.9639左右。 本文使用PaddlePaddle深度学习框架进行复现,最终在Forest Cover Type数据集达到0.96777的精度,已经超越Pytorch版本的精度。
2.模型介绍
TabNet是一种经典的DNN网络结构,它可以处理未经预处理的表格化数据。它主要的功能有:
1.TabNet支持不进行任何预处理的情况下输入原始表格数据,并使用基于梯度下降的优化方法进行训练,从而实现端到端学习的灵活集成。
2.TabNet使用顺序注意来选择在每个决策步骤中推理的特征,由于学习能力用于最显著的功能,因此能够实现可解释性和更好的学习。这种特征选择是即时的,例如,对于每个输入,它可以是不同的,并且不同于其他实例特征选择方法,TabNet采用单一的深度学习架构进行特征选择和推理。
3。上面的设计选择导致了两个有价值的特性:
(1)TabNet优于其他表格学习模型,用于不同领域的分类和回归问题的各种数据集;
(2)TabNet支持两种解释性:局部解释性和全局解释性。
TabNet的主要结构如下图:
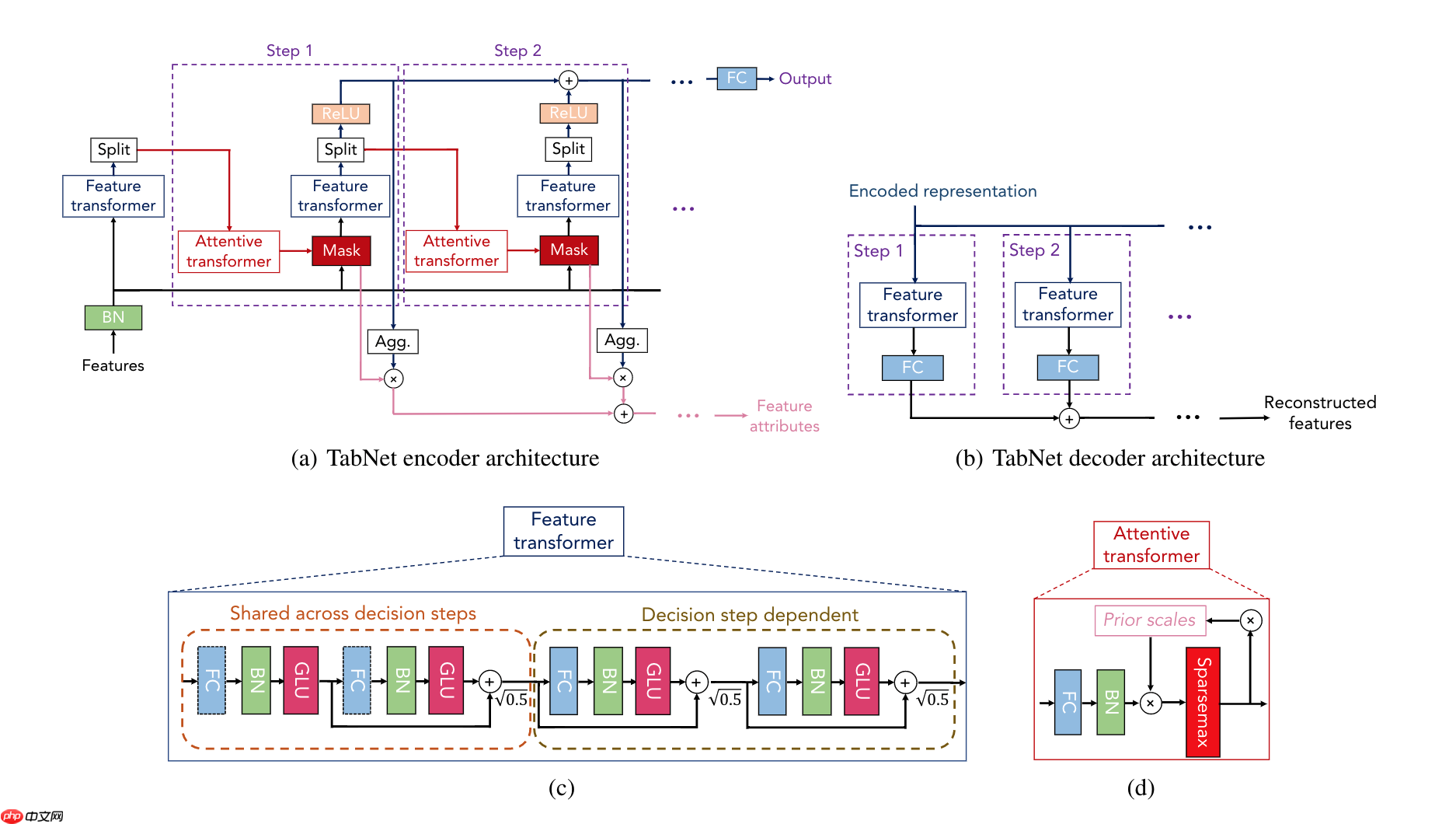
a部分为TabNet编码器,由特征变换器、attentive transformer和特征掩模组成。分割块对处理后的表示进行分割,这些表示将由后续步骤的attentive transformer使用,并用于总体输出。对于每一步,特征选择掩模提供了模型功能的可解释信息,并且可以对掩模进行聚合以获得全局特征的重要属性。
b部分为TabNet解码器,每一步由一个特征转换块组成。
c部分显示了一个特征变换器块示例,一个4层网络,其中2层在所有决策步骤zhong共享,2层依赖于决策步骤。每一层由完全连接(FC)层、BN层和GLU层非线性组成。
d部分是一个attentive transformer block示例–使用先验比例信息对单层映射进行调制,该信息汇总了当前决策步骤之前每个特征的使用量。sparsemax用于系数的标准化,导致显著特征的稀疏选择。
3.数据集下载
运行程序会自动下载数据集并解压到data目录下,不需要手动下载。
如果想手动下载,地址如下。

Forest Cover Type数据集地址:
https://archive.ics.uci.edu/ml/machine-learning-databases/covtype/covtype.data.gz
4.环境
PaddlePaddle == 2.1.2
python == 3.7
还需安装wget自动下载数据集。安装命令如下:
!pip install wget
5.训练
-
训练使用了原文中数据集划分方式,原文参考的论文为《Xgboost: Scalable GPU accelerated learning》。
相关项目地址:
https://github.com/RAMitchell/GBM-Benchmarks/blob/master/benchmark.py
-
模型参数保持原文中的参数设置:
N_d=N_a=64, λ_sparse=0.0001, B=16384, B_v =512, mB=0.7, N_steps=5 and γ=1.5.
调整了原文中的训练策略,模型准确率有所提升。使用Warmup+CosineAnnealingDecay方式来调整学习率,最大epoch为3000。每个epoch执行22次迭代。Warmup设置为5000次迭代达到0.02的学习率,CosineAnnealingDecay半周期设置为22 * 3000 - 5000。
-
在网络中bn层输入的张量stop_gradient为True时,训练会报错。所以需要处理一下输入才能正常训练,处理方法如下:
将
x = self.initial_bn(x)
改为
c = paddle.to_tensor(np.array([0]).astype('float32'))c.stop_gradient = Truex_1 = x + cx_1.stop_gradient = Falsex = self.initial_bn(x_1) 训练命令:
%cd /home/aistudio/paddle_tabnet/ !python -u train.py
6.测试
首先现在最高精度模型文件。(acc: 0.96777)
训练结果模型下载地址:
链接: https://pan.baidu.com/s/1FdZ1tWEHF7JWTDZqgF1i3Q
密码: 7hm2
%cd /home/aistudio/ !unzip best_model.zip%cd /home/aistudio/paddle_tabnet !python predict.py --model_path ../best_model
7.总结
在本文复现过程遇到了几个问题,虽然都找到了解决办法,但是有的地方还是有些疑惑不知道是不是bug。
- 在自定义算子中,在预测推理过程中,显存会暴涨,排查结果是因为使用了ctx.save_for_backward(supp_size, output)方法导致的。猜测是在推理过程中只有forward所以保存的Tensor没有被消费掉,所以会暴涨?最终在forward方法中添加一个参数tranning判断是training还是eval,如果是eval阶段则不执行ctx.save_for_backward(supp_size, output)。这样确实内存不会暴涨了,相关issue。
- 还是在自定义算子中,使用了grad_input[output == 0] = 0这种语句会导致显存缓缓增加,每次增加的都很少,在迭代一定次数后,显存被占满,最后程序崩溃。通过以下代码代替grad_input[output == 0] = 0最终解决问题,不知道这里是不是bug。
idx = paddle.fluid.layers.where(output == 0) grad_input_gather = paddle.gather_nd(grad_input, idx) grad_input_gather = 0 - grad_input_gather grad_input = paddle.scatter_nd_add(grad_input, idx, grad_input_gather)
以上是遇到的一些问题的总结。




























