






adaptformer由港大等机构提出,旨在解决大型视觉模型微调的算力和存储负担问题。其让网络及权重在多下游任务中尽可能保持一致,仅训练少量参数。通过在transformer的mhsa层并行添加可学习模块,在cifar100预训练后迁移至cifar10,冻结网络时参数量大幅减少,准确率却更高,展现出在迁移学习中的优越性。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

AdaptFormer
论文地址:https://arxiv.org/abs/2205.13535
简介:
港大,腾讯AI实验室,港中文贡献的文章:AdaptFormer: Adapting Vision Transformers for Scalable Visual Recognition. 研究人员认为最新的transformer文章做的是same network with task-specific weight工作,用的是同样的网络,但是对每个下游任务都要fine-tune模型,这样的模型是不可拓展的,每搞一个数据集就要在上边fully finetune, 尤其是现在像ViT-G/14这样有18亿参数的大模型,训练时的算力和存储负担很重。所以他们要搞same network with almost same weights, 不仅网络要一样,应用到下游任务,权重也尽可能一样。只需要训练很少的参数,其他大部分参数是固定的,这些固定的参数就可以跨任务共享。
要做这件事需要构建一种高效的pileline去适配预训练模型到许多下游任务,他们的工作更像VPT (Visual Prompt Tuning),VPT在patch embedding那里增加可学习的参数同时冻结整个主干只finetuen embedding部分,但本项目所作的工作能够大大超越VPT,如下图所示:
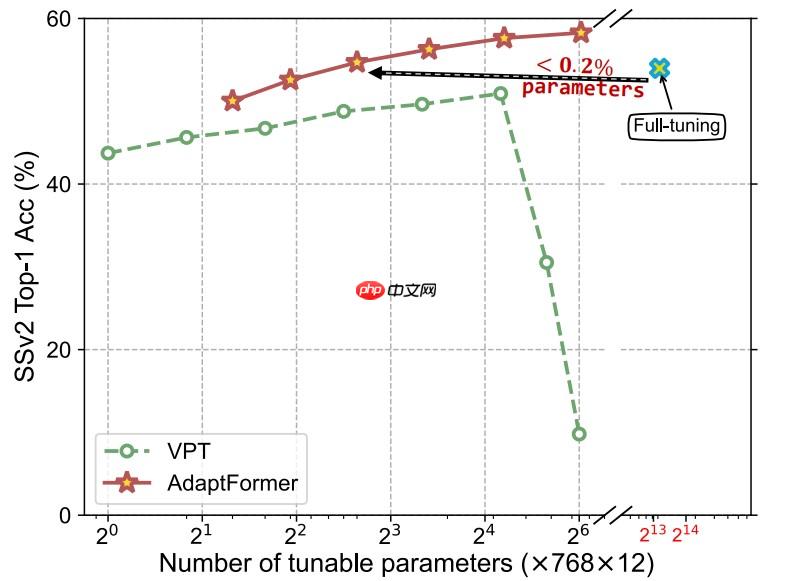
AdaptFormer方法在SSv2数据集上全面打败了VPT
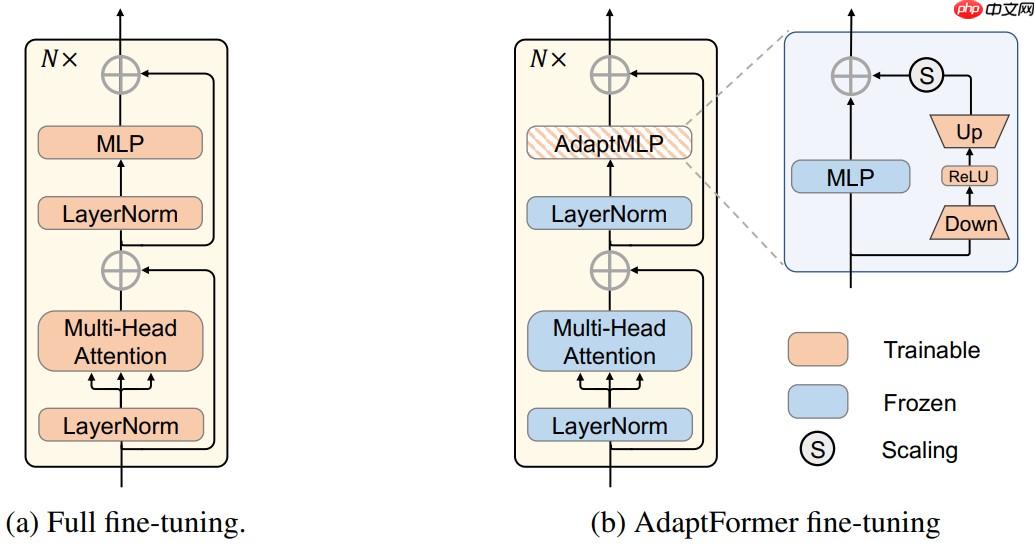
本文的方法和VPT不同的地方在于,AdaptFormer是加到Transformer的MHSA(multi-head self-attention layer)上:
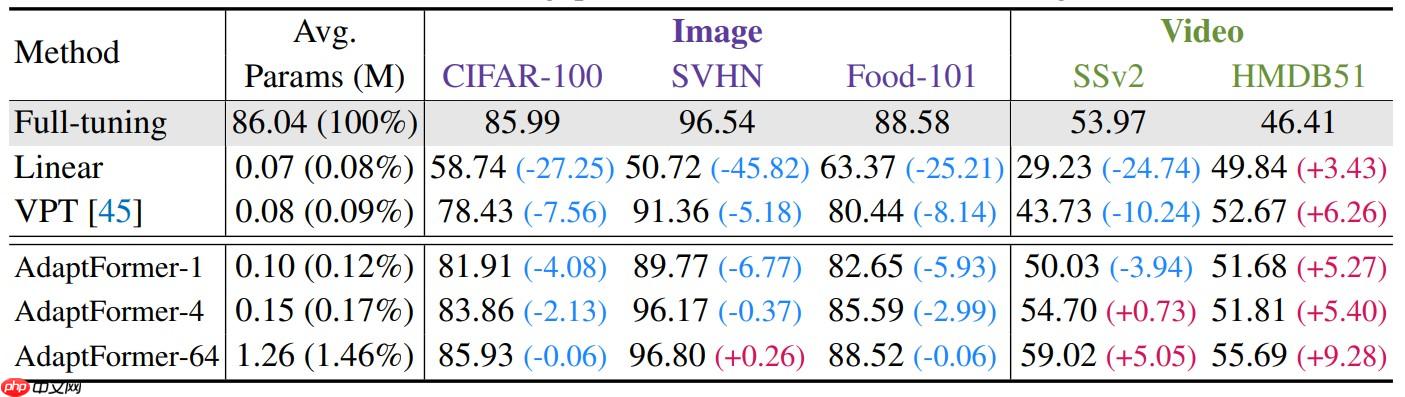
下图为在各种数据集上本方法与VPT等方法的对比:
最后文章希望可以激励更多研究者探索更加高效的fine-tuning方法到大型视觉模型上。
数据集介绍:Cifar100
链接:http://www.cs.toronto.edu/~kriz/cifar.html

CIFAR100数据集有100个类。每个类有600张大小为32 × 32 32\times 3232×32的彩色图像,其中500张作为训练集,100张作为测试集。
数据集介绍:Cifar10
链接:http://www.cs.toronto.edu/~kriz/cifar.html

CIFAR-10是一个更接近普适物体的彩色图像数据集。CIFAR-10 是由Hinton 的学生Alex Krizhevsky 和Ilya Sutskever 整理的一个用于识别普适物体的小型数据集。一共包含10 个类别的RGB彩色图片:飞机(airplane)、汽车(automobile)、鸟类(bird)、猫(cat)、鹿(deer)、狗(dog)、蛙类(frog)、马(horse)、船(ship)和卡车(truck).
每个图片的尺寸为 32×32,每个类别有6000个图像,数据集中一共有50000张训练图片和10000张测试图片。
代码复现
1.引入依赖包
from __future__ import divisionfrom __future__ import print_functionimport paddle.nn as nnfrom paddle.nn import functional as Ffrom paddle.utils.download import get_weights_path_from_urlimport pickleimport numpy as npfrom paddle import callbacksfrom paddle.vision.transforms import (
ToTensor, RandomHorizontalFlip, RandomResizedCrop, SaturationTransform, Compose,
HueTransform, BrightnessTransform, ContrastTransform, RandomCrop, Normalize, RandomRotation, Resize
)from paddle.vision.datasets import Cifar10, Cifar100from paddle.io import DataLoaderfrom paddle.optimizer.lr import CosineAnnealingDecay, MultiStepDecay, LinearWarmupimport randomimport osimport numpy as npimport cv2from PIL import Imageimport matplotlib.pyplot as pltimport paddlefrom paddle.io import Datasetfrom paddle.nn import Conv2D, MaxPool2D, Linear, Dropout, BatchNorm, AdaptiveAvgPool2D, AvgPool2Dimport paddle.nn.functional as Fimport paddle.nn as nn
IS_STOP_GRADIENT = False
2.图像分块嵌入
# 图像分块、Embeddingclass PatchEmbed(nn.Layer):
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__() # 原始大小为int,转为tuple,即:img_size原始输入224,变换后为[224,224]
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size) # 图像块的个数
num_patches = (img_size[1] // patch_size[1]) * \
(img_size[0] // patch_size[0])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches # kernel_size=块大小,即每个块输出一个值,类似每个块展平后使用相同的全连接层进行处理
# 输入维度为3,输出维度为块向量长度
# 与原文中:分块、展平、全连接降维保持一致
# 输出为[B, C, H, W]
self.proj = nn.Conv2D(
in_chans, embed_dim, kernel_size=patch_size, stride=patch_size) def forward(self, x):
B, C, H, W = x.shape assert H == self.img_size[0] and W == self.img_size[1], \ "Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
# [B, C, H, W] -> [B, C, H*W] ->[B, H*W, C]
x = self.proj(x).flatten(2).transpose((0, 2, 1)) return x
3.Multi-head Attention
class Attention(nn.Layer):
def __init__(self,
dim,
num_heads=8,
qkv_bias=False,
qk_scale=None,
attn_drop=0.,
proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim**-0.5
# 计算 q,k,v 的转移矩阵
self.qkv = nn.Linear(dim, dim * 3, bias_attr=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop) # 最终的线性层
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop) def forward(self, x):
N, C = x.shape[1:] # 线性变换
qkv = self.qkv(x).reshape((-1, N, 3, self.num_heads, C //
self.num_heads)).transpose((2, 0, 3, 1, 4)) # 分割 query key value
q, k, v = qkv[0], qkv[1], qkv[2] # Scaled Dot-Product Attention
# Matmul + Scale
attn = (q.matmul(k.transpose((0, 1, 3, 2)))) * self.scale # SoftMax
attn = nn.functional.softmax(attn, axis=-1)
attn = self.attn_drop(attn) # Matmul
x = (attn.matmul(v)).transpose((0, 2, 1, 3)).reshape((-1, N, C)) # 线性变换
x = self.proj(x)
x = self.proj_drop(x) return x
4.多层感知机
class Mlp(nn.Layer):
def __init__(self,
in_features,
hidden_features=None,
out_features=None,
act_layer=nn.GELU,
drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop) def forward(self, x):
# 输入层:线性变换
x = self.fc1(x) # 应用激活函数
x = self.act(x) # Dropout
x = self.drop(x) # 输出层:线性变换
x = self.fc2(x) # Dropout
x = self.drop(x) return x
5.基础模块
基于上面实现的 Attention、MLP 和下面的 DropPath 模块就可以组合出 Vision Transformer 模型的一个基础模块
def drop_path(x, drop_prob=0., training=False):
if drop_prob == 0. or not training: return x
keep_prob = paddle.to_tensor(1 - drop_prob)
shape = (paddle.shape(x)[0], ) + (1, ) * (x.ndim - 1)
random_tensor = keep_prob + paddle.rand(shape, dtype=x.dtype)
random_tensor = paddle.floor(random_tensor)
output = x.divide(keep_prob) * random_tensor return outputclass DropPath(nn.Layer):
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
6.Block
AdaptFormer网络在Block中进行了更改,MLP层并行了Down Relu Up三层,并通过一个可学习的参数scale进行相加
Paddle中提供的stop_gradient函数有两个功能,对于输出的值,如:

x = self.norm(x)x.sotp_gradient = True
则在此层之前的所有参数均停止更新
x = self.norm(x)self.norm.stop_gradient = True
则只停止这一层网络的参数更新
以上两种用法可以用以冻结网络
通过读取全局变量IS_STOP_GRADIENT决定是否冻结网络
关于此API的说明在官方文档中较少,后续可以进行补充
class Block(nn.Layer):
def __init__(self,
dim,
num_heads,
mlp_ratio=4.,
qkv_bias=False,
qk_scale=None,
drop=0.,
attn_drop=0.,
drop_path=0.,
act_layer=nn.GELU,
norm_layer='nn.LayerNorm',
epsilon=1e-5):
super().__init__()
self.norm1 = eval(norm_layer)(dim, epsilon=epsilon) # Multi-head Self-attention
self.attn = Attention(
dim,
num_heads=num_heads,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
attn_drop=attn_drop,
proj_drop=drop) # DropPath
self.drop_path = DropPath(drop_path) if drop_path > 0. else Identity()
self.norm2 = eval(norm_layer)(dim, epsilon=epsilon)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim,
hidden_features=mlp_hidden_dim,
act_layer=act_layer,
drop=drop)
self.n_embd = 768
self.down_size = 64
self.down_proj = nn.Linear(self.n_embd, self.down_size)
self.non_linear_func = nn.ReLU()
self.up_proj = nn.Linear(self.down_size, self.n_embd)
self.scale = self.create_parameter(shape=(1, 1), default_initializer=nn.initializer.Constant(value=1.)) def forward(self, x):
# Multi-head Self-attention, Add, LayerNorm
###
# 设置是否训练参数
###
self.norm1.stop_gradient = IS_STOP_GRADIENT
self.attn.stop_gradient = IS_STOP_GRADIENT
x = x + self.drop_path(self.attn(self.norm1(x))) # Feed Forward, Add, LayerNorm
residual = x ###
# 设置是否训练norm层参数
###
self.norm2.stop_gradient = IS_STOP_GRADIENT
x = self.norm2(x) ###
# 设置是否训练MLP层参数
###
self.mlp.stop_gradient = IS_STOP_GRADIENT
###
# 以下几层为AdaptFormer改进的核心,迁移训练过程中参数不变
###
down = self.down_proj(x)
down = self.non_linear_func(down)
down = nn.functional.dropout(down, p=0.1)
up = self.up_proj(down)
up = up * self.scale + self.mlp(x)
up = self.drop_path(up)
output = up + residual return output
7.参数初始化配置、独立的不进行任何操作的网络层
# 参数初始化配置trunc_normal_ = nn.initializer.TruncatedNormal(std=.02)
zeros_ = nn.initializer.Constant(value=0.)
ones_ = nn.initializer.Constant(value=1.)# 将输入 x 由 int 类型转为 tuple 类型def to_2tuple(x):
return tuple([x] * 2)# 定义一个什么操作都不进行的网络层class Identity(nn.Layer):
def __init__(self):
super(Identity, self).__init__() def forward(self, input):
return input
8.完整代码
由于Cifar100数据集由32×32的图像构成,图像大小偏小,故将ViT的patch_size 由16调整为3,能够提取图像更多的特征信息。
调整后模型在测试集上的准确率能够随epoch的增加迅速上升,并减少过拟合现象。
class VisionTransformer(nn.Layer):
def __init__(self,
img_size=32,
patch_size=3,
in_chans=3,
class_dim=100,
embed_dim=768,
depth=12,
num_heads=12,
mlp_ratio=4,
qkv_bias=False,
qk_scale=None,
drop_rate=0.,
attn_drop_rate=0.,
drop_path_rate=0.,
norm_layer='nn.LayerNorm',
epsilon=1e-5,
**args):
super().__init__()
self.class_dim = class_dim
self.num_features = self.embed_dim = embed_dim # 图片分块和降维,块大小为patch_size,最终块向量维度为768
self.patch_embed = PatchEmbed(
img_size=img_size,
patch_size=patch_size,
in_chans=in_chans,
embed_dim=embed_dim) # 分块数量
num_patches = self.patch_embed.num_patches # 可学习的位置编码
self.pos_embed = self.create_parameter(
shape=(1, num_patches + 1, embed_dim), default_initializer=zeros_)
self.add_parameter("pos_embed", self.pos_embed) # 人为追加class token,并使用该向量进行分类预测
self.cls_token = self.create_parameter(
shape=(1, 1, embed_dim), default_initializer=zeros_)
self.add_parameter("cls_token", self.cls_token)
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = np.linspace(0, drop_path_rate, depth) # transformer
self.blocks = nn.LayerList([
Block(
dim=embed_dim,
num_heads=num_heads,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[i],
norm_layer=norm_layer,
epsilon=epsilon) for i in range(depth)
])
self.norm = eval(norm_layer)(embed_dim, epsilon=epsilon) # Classifier head
self.head = nn.Linear(embed_dim,
class_dim) if class_dim > 0 else Identity()
trunc_normal_(self.pos_embed)
trunc_normal_(self.cls_token)
self.apply(self._init_weights) # 参数初始化
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight) if isinstance(m, nn.Linear) and m.bias is not None:
zeros_(m.bias) elif isinstance(m, nn.LayerNorm):
zeros_(m.bias)
ones_(m.weight) # 获取图像特征
def forward_features(self, x):
B = paddle.shape(x)[0] # 将图片分块,并调整每个块向量的维度
x = self.patch_embed(x) # 将class token与前面的分块进行拼接
cls_tokens = self.cls_token.expand((B, -1, -1))
x = paddle.concat((cls_tokens, x), axis=1) # 将编码向量中加入位置编码
x = x + self.pos_embed
x = self.pos_drop(x) ###
# 设置是否冻结网络
###
x.stop_gradient = IS_STOP_GRADIENT
# 堆叠 transformer 结构
for blk in self.blocks:
x = blk(x) # LayerNorm
x = self.norm(x) # 提取分类 tokens 的输出
return x[:, 0] def forward(self, x):
# 获取图像特征
x = self.forward_features(x) # 图像分类
x = self.head(x) return x
# 测试vit = VisionTransformer() paddle.summary(vit, (1, 3, 32, 32))
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-2 [[1, 3, 32, 32]] [1, 768, 10, 10] 21,504
PatchEmbed-2 [[1, 3, 32, 32]] [1, 100, 768] 0
Dropout-38 [[1, 101, 768]] [1, 101, 768] 0
LayerNorm-26 [[1, 101, 768]] [1, 101, 768] 1,536
Linear-74 [[1, 101, 768]] [1, 101, 2304] 1,769,472
Dropout-39 [[1, 12, 101, 101]] [1, 12, 101, 101] 0
Linear-75 [[1, 101, 768]] [1, 101, 768] 590,592
Dropout-40 [[1, 101, 768]] [1, 101, 768] 0
Attention-13 [[1, 101, 768]] [1, 101, 768] 0
Identity-13 [[1, 101, 768]] [1, 101, 768] 0
LayerNorm-27 [[1, 101, 768]] [1, 101, 768] 1,536
Linear-78 [[1, 101, 768]] [1, 101, 64] 49,216
ReLU-13 [[1, 101, 64]] [1, 101, 64] 0
Linear-79 [[1, 101, 64]] [1, 101, 768] 49,920
Linear-76 [[1, 101, 768]] [1, 101, 3072] 2,362,368
GELU-13 [[1, 101, 3072]] [1, 101, 3072] 0
Dropout-41 [[1, 101, 768]] [1, 101, 768] 0
Linear-77 [[1, 101, 3072]] [1, 101, 768] 2,360,064
Mlp-13 [[1, 101, 768]] [1, 101, 768] 0
Block-13 [[1, 101, 768]] [1, 101, 768] 1
LayerNorm-28 [[1, 101, 768]] [1, 101, 768] 1,536
Linear-80 [[1, 101, 768]] [1, 101, 2304] 1,769,472
Dropout-42 [[1, 12, 101, 101]] [1, 12, 101, 101] 0
Linear-81 [[1, 101, 768]] [1, 101, 768] 590,592
Dropout-43 [[1, 101, 768]] [1, 101, 768] 0
Attention-14 [[1, 101, 768]] [1, 101, 768] 0
Identity-14 [[1, 101, 768]] [1, 101, 768] 0
LayerNorm-29 [[1, 101, 768]] [1, 101, 768] 1,536
Linear-84 [[1, 101, 768]] [1, 101, 64] 49,216
ReLU-14 [[1, 101, 64]] [1, 101, 64] 0
Linear-85 [[1, 101, 64]] [1, 101, 768] 49,920
Linear-82 [[1, 101, 768]] [1, 101, 3072] 2,362,368
GELU-14 [[1, 101, 3072]] [1, 101, 3072] 0
Dropout-44 [[1, 101, 768]] [1, 101, 768] 0
Linear-83 [[1, 101, 3072]] [1, 101, 768] 2,360,064
Mlp-14 [[1, 101, 768]] [1, 101, 768] 0
Block-14 [[1, 101, 768]] [1, 101, 768] 1
LayerNorm-30 [[1, 101, 768]] [1, 101, 768] 1,536
Linear-86 [[1, 101, 768]] [1, 101, 2304] 1,769,472
Dropout-45 [[1, 12, 101, 101]] [1, 12, 101, 101] 0
Linear-87 [[1, 101, 768]] [1, 101, 768] 590,592
Dropout-46 [[1, 101, 768]] [1, 101, 768] 0
Attention-15 [[1, 101, 768]] [1, 101, 768] 0
Identity-15 [[1, 101, 768]] [1, 101, 768] 0
LayerNorm-31 [[1, 101, 768]] [1, 101, 768] 1,536
Linear-90 [[1, 101, 768]] [1, 101, 64] 49,216
ReLU-15 [[1, 101, 64]] [1, 101, 64] 0
Linear-91 [[1, 101, 64]] [1, 101, 768] 49,920
Linear-88 [[1, 101, 768]] [1, 101, 3072] 2,362,368
GELU-15 [[1, 101, 3072]] [1, 101, 3072] 0
Dropout-47 [[1, 101, 768]] [1, 101, 768] 0
Linear-89 [[1, 101, 3072]] [1, 101, 768] 2,360,064
Mlp-15 [[1, 101, 768]] [1, 101, 768] 0
Block-15 [[1, 101, 768]] [1, 101, 768] 1
LayerNorm-32 [[1, 101, 768]] [1, 101, 768] 1,536
Linear-92 [[1, 101, 768]] [1, 101, 2304] 1,769,472
Dropout-48 [[1, 12, 101, 101]] [1, 12, 101, 101] 0
Linear-93 [[1, 101, 768]] [1, 101, 768] 590,592
Dropout-49 [[1, 101, 768]] [1, 101, 768] 0
Attention-16 [[1, 101, 768]] [1, 101, 768] 0
Identity-16 [[1, 101, 768]] [1, 101, 768] 0
LayerNorm-33 [[1, 101, 768]] [1, 101, 768] 1,536
Linear-96 [[1, 101, 768]] [1, 101, 64] 49,216
ReLU-16 [[1, 101, 64]] [1, 101, 64] 0
Linear-97 [[1, 101, 64]] [1, 101, 768] 49,920
Linear-94 [[1, 101, 768]] [1, 101, 3072] 2,362,368
GELU-16 [[1, 101, 3072]] [1, 101, 3072] 0
Dropout-50 [[1, 101, 768]] [1, 101, 768] 0
Linear-95 [[1, 101, 3072]] [1, 101, 768] 2,360,064
Mlp-16 [[1, 101, 768]] [1, 101, 768] 0
Block-16 [[1, 101, 768]] [1, 101, 768] 1
LayerNorm-34 [[1, 101, 768]] [1, 101, 768] 1,536
Linear-98 [[1, 101, 768]] [1, 101, 2304] 1,769,472
Dropout-51 [[1, 12, 101, 101]] [1, 12, 101, 101] 0
Linear-99 [[1, 101, 768]] [1, 101, 768] 590,592
Dropout-52 [[1, 101, 768]] [1, 101, 768] 0
Attention-17 [[1, 101, 768]] [1, 101, 768] 0
Identity-17 [[1, 101, 768]] [1, 101, 768] 0
LayerNorm-35 [[1, 101, 768]] [1, 101, 768] 1,536
Linear-102 [[1, 101, 768]] [1, 101, 64] 49,216
ReLU-17 [[1, 101, 64]] [1, 101, 64] 0
Linear-103 [[1, 101, 64]] [1, 101, 768] 49,920
Linear-100 [[1, 101, 768]] [1, 101, 3072] 2,362,368
GELU-17 [[1, 101, 3072]] [1, 101, 3072] 0
Dropout-53 [[1, 101, 768]] [1, 101, 768] 0
Linear-101 [[1, 101, 3072]] [1, 101, 768] 2,360,064
Mlp-17 [[1, 101, 768]] [1, 101, 768] 0
Block-17 [[1, 101, 768]] [1, 101, 768] 1
LayerNorm-36 [[1, 101, 768]] [1, 101, 768] 1,536
Linear-104 [[1, 101, 768]] [1, 101, 2304] 1,769,472
Dropout-54 [[1, 12, 101, 101]] [1, 12, 101, 101] 0
Linear-105 [[1, 101, 768]] [1, 101, 768] 590,592
Dropout-55 [[1, 101, 768]] [1, 101, 768] 0
Attention-18 [[1, 101, 768]] [1, 101, 768] 0
Identity-18 [[1, 101, 768]] [1, 101, 768] 0
LayerNorm-37 [[1, 101, 768]] [1, 101, 768] 1,536
Linear-108 [[1, 101, 768]] [1, 101, 64] 49,216
ReLU-18 [[1, 101, 64]] [1, 101, 64] 0
Linear-109 [[1, 101, 64]] [1, 101, 768] 49,920
Linear-106 [[1, 101, 768]] [1, 101, 3072] 2,362,368
GELU-18 [[1, 101, 3072]] [1, 101, 3072] 0
Dropout-56 [[1, 101, 768]] [1, 101, 768] 0
Linear-107 [[1, 101, 3072]] [1, 101, 768] 2,360,064
Mlp-18 [[1, 101, 768]] [1, 101, 768] 0
Block-18 [[1, 101, 768]] [1, 101, 768] 1
LayerNorm-38 [[1, 101, 768]] [1, 101, 768] 1,536
Linear-110 [[1, 101, 768]] [1, 101, 2304] 1,769,472
Dropout-57 [[1, 12, 101, 101]] [1, 12, 101, 101] 0
Linear-111 [[1, 101, 768]] [1, 101, 768] 590,592
Dropout-58 [[1, 101, 768]] [1, 101, 768] 0
Attention-19 [[1, 101, 768]] [1, 101, 768] 0
Identity-19 [[1, 101, 768]] [1, 101, 768] 0
LayerNorm-39 [[1, 101, 768]] [1, 101, 768] 1,536
Linear-114 [[1, 101, 768]] [1, 101, 64] 49,216
ReLU-19 [[1, 101, 64]] [1, 101, 64] 0
Linear-115 [[1, 101, 64]] [1, 101, 768] 49,920
Linear-112 [[1, 101, 768]] [1, 101, 3072] 2,362,368
GELU-19 [[1, 101, 3072]] [1, 101, 3072] 0
Dropout-59 [[1, 101, 768]] [1, 101, 768] 0
Linear-113 [[1, 101, 3072]] [1, 101, 768] 2,360,064
Mlp-19 [[1, 101, 768]] [1, 101, 768] 0
Block-19 [[1, 101, 768]] [1, 101, 768] 1
LayerNorm-40 [[1, 101, 768]] [1, 101, 768] 1,536
Linear-116 [[1, 101, 768]] [1, 101, 2304] 1,769,472
Dropout-60 [[1, 12, 101, 101]] [1, 12, 101, 101] 0
Linear-117 [[1, 101, 768]] [1, 101, 768] 590,592
Dropout-61 [[1, 101, 768]] [1, 101, 768] 0
Attention-20 [[1, 101, 768]] [1, 101, 768] 0
Identity-20 [[1, 101, 768]] [1, 101, 768] 0
LayerNorm-41 [[1, 101, 768]] [1, 101, 768] 1,536
Linear-120 [[1, 101, 768]] [1, 101, 64] 49,216
ReLU-20 [[1, 101, 64]] [1, 101, 64] 0
Linear-121 [[1, 101, 64]] [1, 101, 768] 49,920
Linear-118 [[1, 101, 768]] [1, 101, 3072] 2,362,368
GELU-20 [[1, 101, 3072]] [1, 101, 3072] 0
Dropout-62 [[1, 101, 768]] [1, 101, 768] 0
Linear-119 [[1, 101, 3072]] [1, 101, 768] 2,360,064
Mlp-20 [[1, 101, 768]] [1, 101, 768] 0
Block-20 [[1, 101, 768]] [1, 101, 768] 1
LayerNorm-42 [[1, 101, 768]] [1, 101, 768] 1,536
Linear-122 [[1, 101, 768]] [1, 101, 2304] 1,769,472
Dropout-63 [[1, 12, 101, 101]] [1, 12, 101, 101] 0
Linear-123 [[1, 101, 768]] [1, 101, 768] 590,592
Dropout-64 [[1, 101, 768]] [1, 101, 768] 0
Attention-21 [[1, 101, 768]] [1, 101, 768] 0
Identity-21 [[1, 101, 768]] [1, 101, 768] 0
LayerNorm-43 [[1, 101, 768]] [1, 101, 768] 1,536
Linear-126 [[1, 101, 768]] [1, 101, 64] 49,216
ReLU-21 [[1, 101, 64]] [1, 101, 64] 0
Linear-127 [[1, 101, 64]] [1, 101, 768] 49,920
Linear-124124 [[1, 101, 768]] [1, 101, 3072] 2,362,368
GELU-21 [[1, 101, 3072]] [1, 101, 3072] 0
Dropout-65 [[1, 101, 768]] [1, 101, 768] 0
Linear-125 [[1, 101, 3072]] [1, 101, 768] 2,360,064
Mlp-21 [[1, 101, 768]] [1, 101, 768] 0
Block-21 [[1, 101, 768]] [1, 101, 768] 1
LayerNorm-44 [[1, 101, 768]] [1, 101, 768] 1,536
Linear-128 [[1, 101, 768]] [1, 101, 2304] 1,769,472
Dropout-66 [[1, 12, 101, 101]] [1, 12, 101, 101] 0
Linear-129 [[1, 101, 768]] [1, 101, 768] 590,592
Dropout-67 [[1, 101, 768]] [1, 101, 768] 0
Attention-22 [[1, 101, 768]] [1, 101, 768] 0
Identity-22 [[1, 101, 768]] [1, 101, 768] 0
LayerNorm-45 [[1, 101, 768]] [1, 101, 768] 1,536
Linear-132 [[1, 101, 768]] [1, 101, 64] 49,216
ReLU-22 [[1, 101, 64]] [1, 101, 64] 0
Linear-133 [[1, 101, 64]] [1, 101, 768] 49,920
Linear-130 [[1, 101, 768]] [1, 101, 3072] 2,362,368
GELU-22 [[1, 101, 3072]] [1, 101, 3072] 0
Dropout-68 [[1, 101, 768]] [1, 101, 768] 0
Linear-131 [[1, 101, 3072]] [1, 101, 768] 2,360,064
Mlp-22 [[1, 101, 768]] [1, 101, 768] 0
Block-22 [[1, 101, 768]] [1, 101, 768] 1
LayerNorm-46 [[1, 101, 768]] [1, 101, 768] 1,536
Linear-134 [[1, 101, 768]] [1, 101, 2304] 1,769,472
Dropout-69 [[1, 12, 101, 101]] [1, 12, 101, 101] 0
Linear-135 [[1, 101, 768]] [1, 101, 768] 590,592
Dropout-70 [[1, 101, 768]] [1, 101, 768] 0
Attention-23 [[1, 101, 768]] [1, 101, 768] 0
Identity-23 [[1, 101, 768]] [1, 101, 768] 0
LayerNorm-47 [[1, 101, 768]] [1, 101, 768] 1,536
Linear-138 [[1, 101, 768]] [1, 101, 64] 49,216
ReLU-23 [[1, 101, 64]] [1, 101, 64] 0
Linear-139 [[1, 101, 64]] [1, 101, 768] 49,920
Linear-136 [[1, 101, 768]] [1, 101, 3072] 2,362,368
GELU-23 [[1, 101, 3072]] [1, 101, 3072] 0
Dropout-71 [[1, 101, 768]] [1, 101, 768] 0
Linear-137 [[1, 101, 3072]] [1, 101, 768] 2,360,064
Mlp-23 [[1, 101, 768]] [1, 101, 768] 0
Block-23 [[1, 101, 768]] [1, 101, 768] 1
LayerNorm-48 [[1, 101, 768]] [1, 101, 768] 1,536
Linear-140 [[1, 101, 768]] [1, 101, 2304] 1,769,472
Dropout-72 [[1, 12, 101, 101]] [1, 12, 101, 101] 0
Linear-141 [[1, 101, 768]] [1, 101, 768] 590,592
Dropout-73 [[1, 101, 768]] [1, 101, 768] 0
Attention-24 [[1, 101, 768]] [1, 101, 768] 0
Identity-24 [[1, 101, 768]] [1, 101, 768] 0
LayerNorm-49 [[1, 101, 768]] [1, 101, 768] 1,536
Linear-144 [[1, 101, 768]] [1, 101, 64] 49,216
ReLU-24 [[1, 101, 64]] [1, 101, 64] 0
Linear-145 [[1, 101, 64]] [1, 101, 768] 49,920
Linear-142 [[1, 101, 768]] [1, 101, 3072] 2,362,368
GELU-24 [[1, 101, 3072]] [1, 101, 3072] 0
Dropout-74 [[1, 101, 768]] [1, 101, 768] 0
Linear-143 [[1, 101, 3072]] [1, 101, 768] 2,360,064
Mlp-24 [[1, 101, 768]] [1, 101, 768] 0
Block-24 [[1, 101, 768]] [1, 101, 768] 1
LayerNorm-50 [[1, 101, 768]] [1, 101, 768] 1,536
Linear-146 [[1, 768]] [1, 100] 76,900
===========================================================================
Total params: 86,316,400
Trainable params: 86,316,400
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.01
Forward/backward pass size (MB): 170.98
Params size (MB): 329.27
Estimated Total Size (MB): 500.26
---------------------------------------------------------------------------
{'total_params': 86316400, 'trainable_params': 86316400}
9.自定义数据集处理方式
class ToArray(object):
def __call__(self, img):
img = np.array(img)
img = np.transpose(img, [2, 0, 1])
img = img / 255.
return img.astype('float32')class RandomApply(object):
def __init__(self, transform, p=0.5):
super().__init__()
self.p = p
self.transform = transform
def __call__(self, img):
if self.p < random.random(): return img
img = self.transform(img) return img
class LRSchedulerM(callbacks.LRScheduler):
def __init__(self, by_step=False, by_epoch=True, warm_up=True):
super().__init__(by_step, by_epoch)
assert by_step ^ warm_up
self.warm_up = warm_up
def on_epoch_end(self, epoch, logs=None):
if self.by_epoch and not self.warm_up: if self.model._optimizer and hasattr(
self.model._optimizer, '_learning_rate') and isinstance(
self.model._optimizer._learning_rate, paddle.optimizer.lr.LRScheduler):
self.model._optimizer._learning_rate.step()
def on_train_batch_end(self, step, logs=None):
if self.by_step or self.warm_up:
if self.model._optimizer and hasattr(
self.model._optimizer, '_learning_rate') and isinstance(
self.model._optimizer._learning_rate, paddle.optimizer.lr.LRScheduler):
self.model._optimizer._learning_rate.step() if self.model._optimizer._learning_rate.last_epoch >= self.model._optimizer._learning_rate.warmup_steps:
self.warm_up = Falsedef _on_train_batch_end(self, step, logs=None):
logs = logs or {}
logs['lr'] = self.model._optimizer.get_lr()
self.train_step += 1
if self._is_write():
self._updates(logs, 'train')def _on_train_begin(self, logs=None):
self.epochs = self.params['epochs'] assert self.epochs
self.train_metrics = self.params['metrics'] + ['lr'] assert self.train_metrics
self._is_fit = True
self.train_step = 0callbacks.VisualDL.on_train_batch_end = _on_train_batch_end
callbacks.VisualDL.on_train_begin = _on_train_begin
10.模型实验
由于PaddleClas提供的Vision Transformer网络结构名称与本项目的网络名称定义不同,故无法使用官方的预训练模型
本次试验尝试通过在Cifar100数据集获取预训练模型,再迁移至Cifar10数据集,通过比较冻结网络与不冻结网络的Acc Top-1区别,探究AdaptFormer网络的可行性。
Cifar100数据集训练模型: AdaptFormer_BaseModel
训练参数为:
- Epoch = 80
- learning_rate = 0.01
- weight_decay = 5e-4
- momentum = 0.9
- batch_size = 128
model = paddle.Model(VisionTransformer(class_dim=100))# 加载checkpoint# model.load('output/AdaptFormer/80.pdparams', skip_mismatch=True)MAX_EPOCH = 80LR = 0.01WEIGHT_DECAY = 5e-4MOMENTUM = 0.9BATCH_SIZE = 128IS_STOP_GRADIENT = FalseCIFAR_MEAN = [0.5071, 0.4865, 0.4409]
CIFAR_STD = [0.1942, 0.1918, 0.1958]
DATA_FILE = Nonemodel.prepare(
paddle.optimizer.Momentum(
learning_rate=LinearWarmup(CosineAnnealingDecay(LR, MAX_EPOCH), 2000, 0., LR),
momentum=MOMENTUM,
parameters=model.parameters(),
weight_decay=WEIGHT_DECAY),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy(topk=(1,5)))# 定义数据集增强方式transforms = Compose([
RandomCrop(32, padding=4),
RandomApply(BrightnessTransform(0.1)),
RandomApply(ContrastTransform(0.1)),
RandomHorizontalFlip(),
RandomRotation(15),
ToArray(),
Normalize(CIFAR_MEAN, CIFAR_STD), # Resize(size=72)])
val_transforms = Compose([ToArray(), Normalize(CIFAR_MEAN, CIFAR_STD)])# 加载训练和测试数据集train_set = Cifar100(DATA_FILE, mode='train', transform=transforms)
test_set = Cifar100(DATA_FILE, mode='test', transform=val_transforms)# 定义保存方式和训练可视化checkpoint_callback = paddle.callbacks.ModelCheckpoint(save_freq=20, save_dir='output/AdaptFormer_BaseModel')
callbacks = [LRSchedulerM(),checkpoint_callback, callbacks.VisualDL('vis_logs/AdaptFormer_BaseModel.log')]# 训练模型model.fit(
train_set,
test_set,
epochs=MAX_EPOCH,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=0,
verbose=1,
callbacks=callbacks,
)
经过80轮的迭代,训练结果如图:
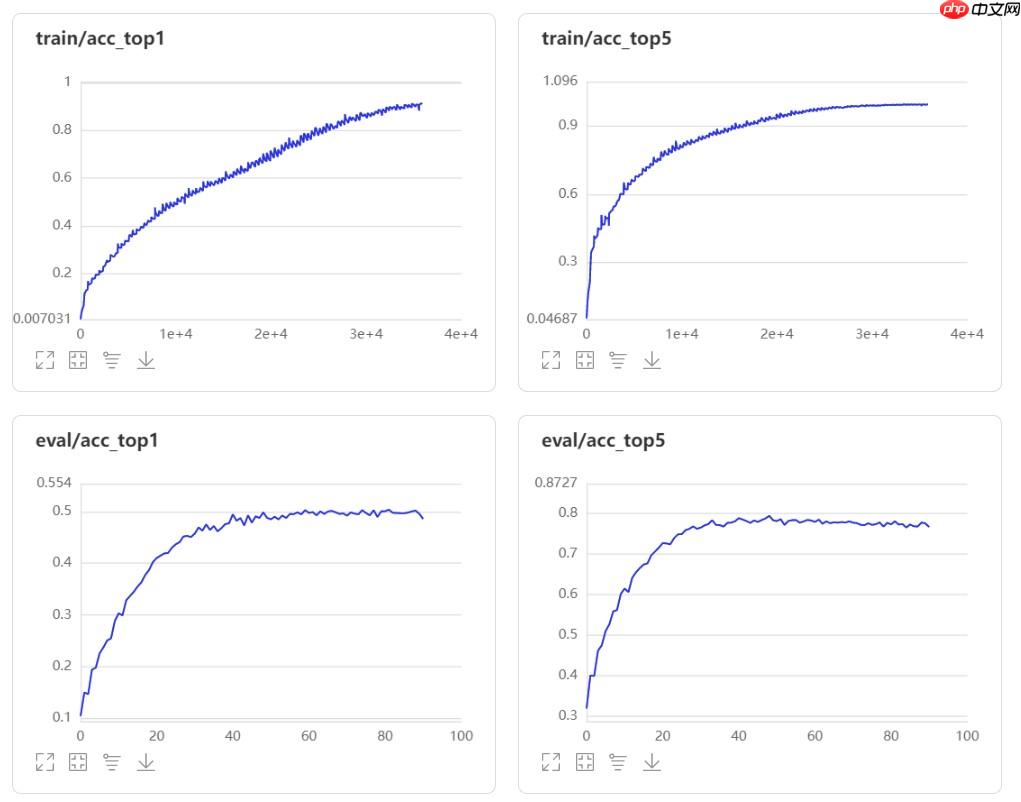
Cifar10数据集迁移模型实验
训练参数:
- Epoch = 10
- learning_rate = 0.01
- weight_decay = 5e-4
- momentum = 0.9
- batch_size = 128
- IS_STOP_GRADIENT = True (实验组)
- IS_STOP_GRADIENT = False (对照组)
model = paddle.Model(VisionTransformer(class_dim=10))# 加载checkpointmodel.load('output/AdaptFormer_BaseModel/80.pdparams', skip_mismatch=True)
MAX_EPOCH = 10LR = 0.01WEIGHT_DECAY = 5e-4MOMENTUM = 0.9BATCH_SIZE = 128IS_STOP_GRADIENT = True # 实验组IS_STOP_GRADIENT = False # 对照组CIFAR_MEAN = [0.5071, 0.4865, 0.4409]
CIFAR_STD = [0.1942, 0.1918, 0.1958]
DATA_FILE = Nonemodel.prepare(
paddle.optimizer.Momentum(
learning_rate=LinearWarmup(CosineAnnealingDecay(LR, MAX_EPOCH), 2000, 0., LR),
momentum=MOMENTUM,
parameters=model.parameters(),
weight_decay=WEIGHT_DECAY),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy(topk=(1,5)))# 定义数据集增强方式transforms = Compose([
RandomCrop(32, padding=4),
RandomApply(BrightnessTransform(0.1)),
RandomApply(ContrastTransform(0.1)),
RandomHorizontalFlip(),
RandomRotation(15),
ToArray(),
Normalize(CIFAR_MEAN, CIFAR_STD), # Resize(size=72)])
val_transforms = Compose([ToArray(), Normalize(CIFAR_MEAN, CIFAR_STD)])# 加载训练和测试数据集train_set = Cifar10(DATA_FILE, mode='train', transform=transforms)
test_set = Cifar10(DATA_FILE, mode='test', transform=val_transforms)# 定义保存方式和训练可视化checkpoint_callback = paddle.callbacks.ModelCheckpoint(save_freq=20, save_dir='output/AdaptFormer_BaseModel')
callbacks = [LRSchedulerM(),checkpoint_callback, callbacks.VisualDL('vis_logs/AdaptFormer_BaseModel.log')]# 训练模型model.fit(
train_set,
test_set,
epochs=MAX_EPOCH,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=0,
verbose=1,
callbacks=callbacks,
)
实验结果
冻结网络迁移训练(左图):
训练参数量:4.56 MB
8个Epoch后Acc Top-1:0.7784
不冻结网络迁移训练(右图):
训练参数量:329.27 MB
10个Epoech后Acc Top-1:0.7662
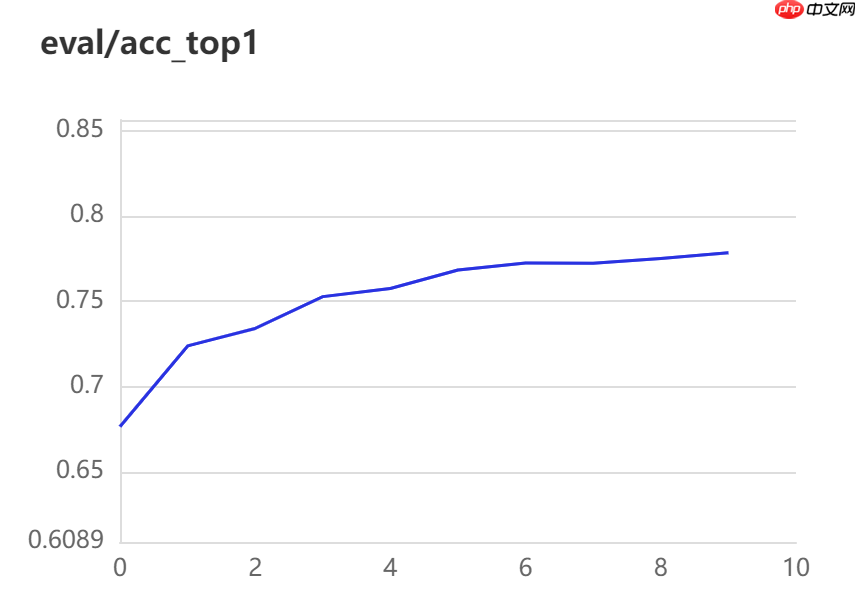
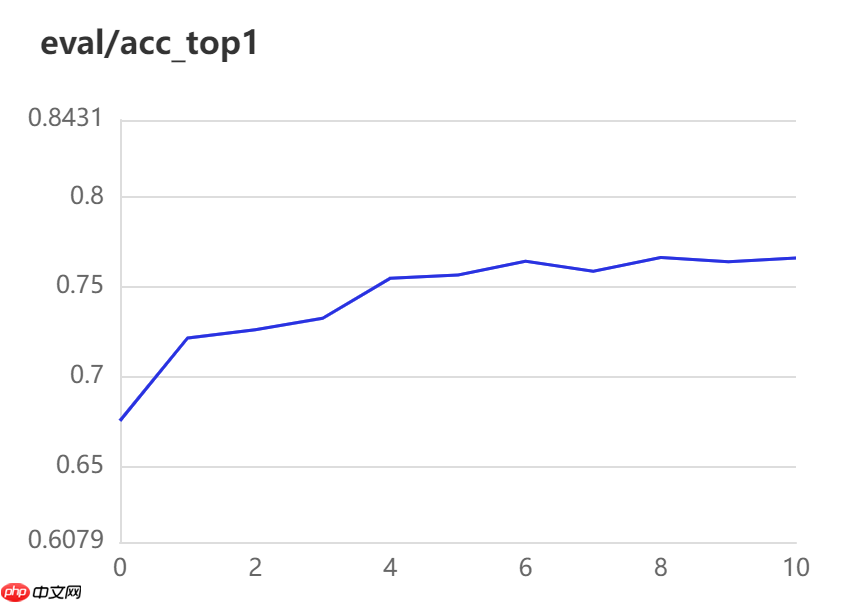
冻结后网络需要训练的参数仅为完整训练参数的1.38% ,但是模型的准确率在减少两个Epoch的情况下相对于完整训练反而增加了一个百分点,由此可以体现AdaptFormer网络在迁移学习中的优越性




























