






crossvit是一种双分支transformer,通过不同粒度patch学习特征。l-branch用粗粒度patch,有更多编码器和更宽维度;s-branch用细粒度patch,编码器少且维度窄。其关键是跨注意力融合模块,以线性复杂度融合信息,在imagenet1k上比deit表现更优,精度提升显著。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

CrossViT:用于图像分类的具有交叉注意力的多尺度ViT
摘要
与卷积神经网络相比,最近发展起来的视觉Transformer(ViT)在图像分类方面取得了很好的效果。 受此启发,本文研究了如何学习Transformer模型中的多尺度特征表示来进行图像分类。 为此,我们提出了一种双分支Transformer来组合不同大小的图像贴片(即Transformer中的令牌),以产生更强的图像特征。 我们的方法处理具有两个不同计算复杂度的分支的小Patch和大Patch令牌,然后这些令牌通过注意力多次融合以互补。 此外,为了减少计算量,我们开发了一个简单有效的基于交叉注意力的令牌融合模块,该模块使用每个分支的单个令牌作为查询来与其他分支交换信息。 我们提出的交叉注意只需要计算和存储复杂度的线性时间,而不是二次时间。 大量的实验表明,除了有效的CNN模型外,我们的方法在视觉Transformer上的性能优于或与几个并发工作相当。 例如,在ImageNet1K数据集上,通过一些体系结构的更改,我们的方法比最近的DeiT,在FLOPs和模型参数的小到中等的增加下,表现出了2%的巨大优势。
1. CrossViT
Patch的大小会影响ViT的精度和计算复杂度,使用细粒度Patch会比粗粒度的精度要高,但是计算复杂度更大。为了利用细粒度Patch的精度优势和粗粒度Patch的计算复杂度优势,本文提出了一个双分支的Transformer——CrossViT,采用两种不同粒度的Patch进行特征学习,同时使用一个简单而有效的融合模块对不同粒度的信息进行融合。本文的整体框架如下图所示:
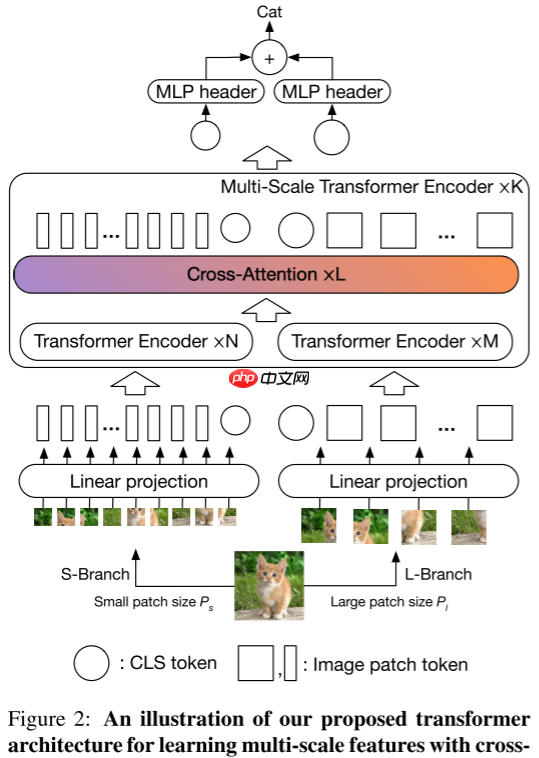
1.1 多尺度ViT
本文提出了一种双分支ViT,主要包含两个分支:
- L-Branch:该分支使用粗粒度Patch作为输入,具有更多的Transformer编码器和更宽的嵌入维度。
- S-Branch:该分支使用细粒度Patch作为输入,具有更少的Transformer编码器和更窄的嵌入维度。
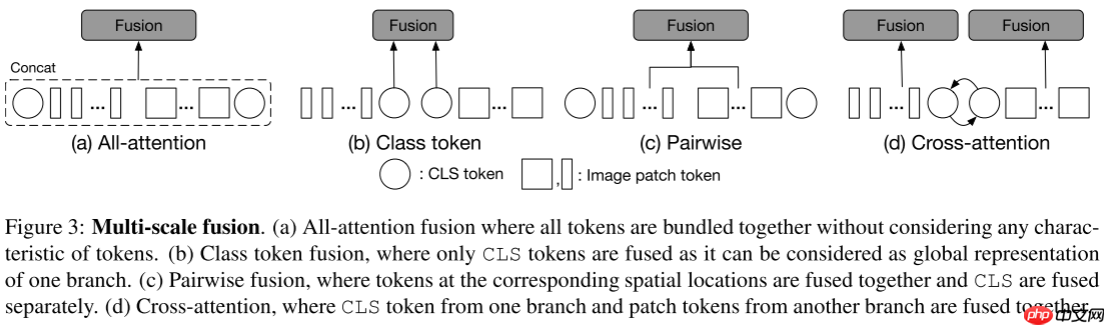
1.2 多尺度特征融合
本文的关键模块是多尺度特征融合,如图3所示主要有如下几个变体:
- 全注意力融合:将两个分支的所有Token进行融合
y=[fl(xl)∥fs(xs)],o=y+MSA(LN(y))o=[ol∥os],zi=gi(oi)
- 类Token融合:仅使用类Token进行两个粒度信息的交换
zi=⎣⎢⎡gi⎝⎛j∈{l,s}∑fj(xclsj)⎠⎞∥xpatch i⎦⎥⎤

- 成对融合:根据空间位置俩俩融合,具体的将粗粒度的分支输出上采样到细粒度分支大小,然后再对应位置进行信息交换
zi=⎣⎢⎡gi⎝⎛j∈{l,s}∑fj(xclsj)⎠⎞∥gi⎝⎛j∈{l,s}∑fj(xpatch j)⎠⎞⎦⎥⎤
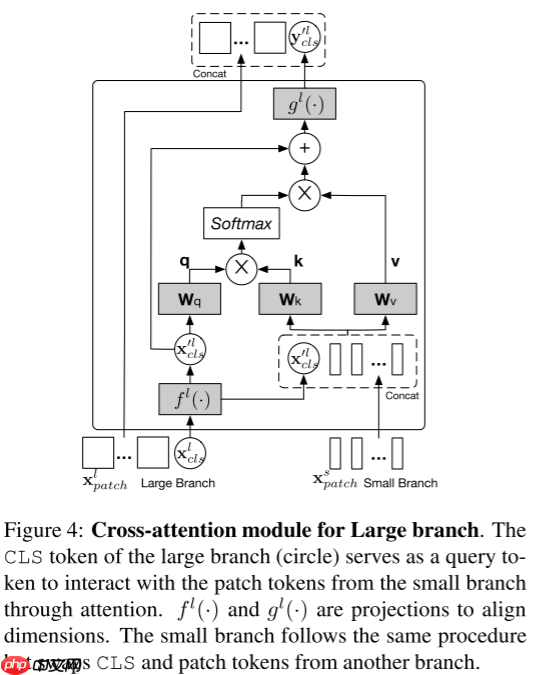
- 跨注意力融合(本文采用的方法):将一个分支的类Token与另一个分支的Patch Token进行自注意力。
x′l=[fl(xclsl)∥xpatch s],
本文的跨注意力融合如图4所示,公式如下所示:
q=xcls′lWq,k=x′lWk,v=x′lWv,A=softmax(qT/C/h),CA(x′l)=Av
yclslzl=fl(xclsl)+MCA(LN([fl(xclsl)∥xpatch s]))=[gl(yclsl)∥xpatch l],
2. 代码复现
2.1 下载并导入所需的库
%matplotlib inlineimport paddleimport numpy as npimport matplotlib.pyplot as pltfrom paddle.vision.datasets import Cifar10from paddle.vision.transforms import Transposefrom paddle.io import Dataset, DataLoaderfrom paddle import nnimport paddle.nn.functional as Fimport paddle.vision.transforms as transformsimport osimport matplotlib.pyplot as pltfrom matplotlib.pyplot import figurefrom functools import partial
2.2 创建数据集
train_tfm = transforms.Compose([
transforms.RandomResizedCrop(224, scale=(0.6, 1.0)),
transforms.ColorJitter(brightness=0.2,contrast=0.2, saturation=0.2),
transforms.RandomHorizontalFlip(0.5),
transforms.RandomRotation(20),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
test_tfm = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
paddle.vision.set_image_backend('cv2')# 使用Cifar10数据集train_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='train', transform = train_tfm, )
val_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='test',transform = test_tfm)print("train_dataset: %d" % len(train_dataset))print("val_dataset: %d" % len(val_dataset))
train_dataset: 50000 val_dataset: 10000
batch_size=256
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True, num_workers=4) val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, drop_last=False, num_workers=4)
2.3 模型的创建
2.3.1 标签平滑
class LabelSmoothingCrossEntropy(nn.Layer):
def __init__(self, smoothing=0.1):
super().__init__()
self.smoothing = smoothing def forward(self, pred, target):
confidence = 1. - self.smoothing
log_probs = F.log_softmax(pred, axis=-1)
idx = paddle.stack([paddle.arange(log_probs.shape[0]), target], axis=1)
nll_loss = paddle.gather_nd(-log_probs, index=idx)
smooth_loss = paddle.mean(-log_probs, axis=-1)
loss = confidence * nll_loss + self.smoothing * smooth_loss return loss.mean()
2.3.2 DropPath
def drop_path(x, drop_prob=0.0, training=False):
"""
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ...
"""
if drop_prob == 0.0 or not training: return x
keep_prob = paddle.to_tensor(1 - drop_prob)
shape = (paddle.shape(x)[0],) + (1,) * (x.ndim - 1)
random_tensor = keep_prob + paddle.rand(shape, dtype=x.dtype)
random_tensor = paddle.floor(random_tensor) # binarize
output = x.divide(keep_prob) * random_tensor return outputclass DropPath(nn.Layer):
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
2.3.3 CrossViT模型的创建
def to_2tuple(x):
return [x, x]class PatchEmbed(nn.Layer):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768, multi_conv=False):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches if multi_conv: if patch_size[0] == 12:
self.proj = nn.Sequential(
nn.Conv2D(in_chans, embed_dim // 4, kernel_size=7, stride=4, padding=3),
nn.ReLU(),
nn.Conv2D(embed_dim // 4, embed_dim // 2, kernel_size=3, stride=3, padding=0),
nn.ReLU(),
nn.Conv2D(embed_dim // 2, embed_dim, kernel_size=3, stride=1, padding=1),
) elif patch_size[0] == 16:
self.proj = nn.Sequential(
nn.Conv2D(in_chans, embed_dim // 4, kernel_size=7, stride=4, padding=3),
nn.ReLU(),
nn.Conv2D(embed_dim // 4, embed_dim // 2, kernel_size=3, stride=2, padding=1),
nn.ReLU(),
nn.Conv2D(embed_dim // 2, embed_dim, kernel_size=3, stride=2, padding=1),
) else:
self.proj = nn.Conv2D(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size) def forward(self, x):
B, C, H, W = x.shape # FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \ f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose([0, 2, 1]) return x
class Mlp(nn.Layer):
""" MLP as used in Vision Transformer, MLP-Mixer and related networks
"""
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, bias=True, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
bias = to_2tuple(bias)
drop_probs = to_2tuple(drop)
self.fc1 = nn.Linear(in_features, hidden_features, bias_attr=bias[0])
self.act = act_layer()
self.drop1 = nn.Dropout(drop_probs[0])
self.fc2 = nn.Linear(hidden_features, out_features, bias_attr=bias[1])
self.drop2 = nn.Dropout(drop_probs[1]) def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop1(x)
x = self.fc2(x)
x = self.drop2(x) return x
class CrossAttention(nn.Layer):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads # NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
self.wq = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.wk = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.wv = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop) def forward(self, x):
B, N, C = x.shape
q = self.wq(x[:, 0:1, ...]).reshape((B, 1, self.num_heads, C // self.num_heads)).transpose([0, 2, 1, 3]) # B1C -> B1H(C/H) -> BH1(C/H)
k = self.wk(x).reshape((B, N, self.num_heads, C // self.num_heads)).transpose([0, 2, 1, 3]) # BNC -> BNH(C/H) -> BHN(C/H)
v = self.wv(x).reshape((B, N, self.num_heads, C // self.num_heads)).transpose([0, 2, 1, 3]) # BNC -> BNH(C/H) -> BHN(C/H)
attn = (q @ k.transpose([0, 1, 3, 2])) * self.scale # BH1(C/H) @ BH(C/H)N -> BH1N
attn = F.softmax(attn, axis=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose([0, 2, 1, 3]).reshape((B, 1, C)) # (BH1N @ BHN(C/H)) -> BH1(C/H) -> B1H(C/H) -> B1C
x = self.proj(x)
x = self.proj_drop(x) return x
class CrossAttentionBlock(nn.Layer):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, has_mlp=True):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = CrossAttention(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop) # NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.has_mlp = has_mlp if has_mlp:
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop) def forward(self, x):
x = x[:, 0:1, ...] + self.drop_path(self.attn(self.norm1(x))) if self.has_mlp:
x = x + self.drop_path(self.mlp(self.norm2(x))) return x
class Attention(nn.Layer):
def __init__(self, dim, num_heads=8, qkv_bias=False, attn_drop=0., proj_drop=0.):
super().__init__() assert dim % num_heads == 0, 'dim should be divisible by num_heads'
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias_attr=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop) def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape((B, N, 3, self.num_heads, C // self.num_heads)).transpose([2, 0, 3, 1, 4])
q, k, v = qkv.unbind(0) # make torchscript happy (cannot use tensor as tuple)
attn = (q @ k.transpose([0, 1, 3, 2])) * self.scale
attn = F.softmax(attn, axis=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose([0, 2, 1, 3]).reshape((B, N, C))
x = self.proj(x)
x = self.proj_drop(x) return xclass Block(nn.Layer):
def __init__(
self,
dim,
num_heads,
mlp_ratio=4.,
qkv_bias=False,
drop=0.,
attn_drop=0.,
drop_path=0.,
act_layer=nn.GELU,
norm_layer=nn.LayerNorm ):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias, attn_drop=attn_drop, proj_drop=drop) # NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path2 = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
self.mlp = Mlp(in_features=dim, hidden_features=int(dim * mlp_ratio), act_layer=act_layer, drop=drop)
self.drop_path2 = DropPath(drop_path) if drop_path > 0. else nn.Identity() def forward(self, x):
x = x + self.drop_path2(self.attn(self.norm1(x)))
x = x + self.drop_path2(self.mlp(self.norm2(x))) return x
class MultiScaleBlock(nn.Layer):
def __init__(self, dim, patches, depth, num_heads, mlp_ratio, qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
num_branches = len(dim)
self.num_branches = num_branches # different branch could have different embedding size, the first one is the base
self.blocks = nn.LayerList() for d in range(num_branches):
tmp = [] for i in range(depth[d]):
tmp.append(
Block(dim=dim[d], num_heads=num_heads[d], mlp_ratio=mlp_ratio[d], qkv_bias=qkv_bias,
drop=drop, attn_drop=attn_drop, drop_path=drop_path[i], norm_layer=norm_layer)) if len(tmp) != 0:
self.blocks.append(nn.Sequential(*tmp)) if len(self.blocks) == 0:
self.blocks = None
self.projs = nn.LayerList() for d in range(num_branches): if dim[d] == dim[(d+1) % num_branches] and False:
tmp = [nn.Identity()] else:
tmp = [norm_layer(dim[d]), act_layer(), nn.Linear(dim[d], dim[(d+1) % num_branches])]
self.projs.append(nn.Sequential(*tmp))
self.fusion = nn.LayerList() for d in range(num_branches):
d_ = (d+1) % num_branches
nh = num_heads[d_] if depth[-1] == 0: # backward capability:
self.fusion.append(CrossAttentionBlock(dim=dim[d_], num_heads=nh, mlp_ratio=mlp_ratio[d], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop, attn_drop=attn_drop, drop_path=drop_path[-1], norm_layer=norm_layer,
has_mlp=False)) else:
tmp = [] for _ in range(depth[-1]):
tmp.append(CrossAttentionBlock(dim=dim[d_], num_heads=nh, mlp_ratio=mlp_ratio[d], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop, attn_drop=attn_drop, drop_path=drop_path[-1], norm_layer=norm_layer,
has_mlp=False))
self.fusion.append(nn.Sequential(*tmp))
self.revert_projs = nn.LayerList() for d in range(num_branches): if dim[(d+1) % num_branches] == dim[d] and False:
tmp = [nn.Identity()] else:
tmp = [norm_layer(dim[(d+1) % num_branches]), act_layer(), nn.Linear(dim[(d+1) % num_branches], dim[d])]
self.revert_projs.append(nn.Sequential(*tmp)) def forward(self, x):
outs_b = [block(x_) for x_, block in zip(x, self.blocks)] # only take the cls token out
proj_cls_token = [proj(x[:, 0:1]) for x, proj in zip(outs_b, self.projs)] # cross attention
outs = [] for i in range(self.num_branches):
tmp = paddle.concat((proj_cls_token[i], outs_b[(i + 1) % self.num_branches][:, 1:, ...]), axis=1)
tmp = self.fusion[i](tmp)
reverted_proj_cls_token = self.revert_projs[i](tmp[:, 0:1, ...])
tmp = paddle.concat((reverted_proj_cls_token, outs_b[i][:, 1:, ...]), axis=1)
outs.append(tmp) return outs
def _compute_num_patches(img_size, patches):
return [i // p * i // p for i, p in zip(img_size,patches)]class VisionTransformer(nn.Layer):
""" Vision Transformer with support for patch or hybrid CNN input stage
"""
def __init__(self, img_size=(224, 224), patch_size=(8, 16), in_chans=3, num_classes=1000, embed_dim=(192, 384), depth=([1, 3, 1], [1, 3, 1], [1, 3, 1]),
num_heads=(6, 12), mlp_ratio=(2., 2., 4.), qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0.,
drop_path_rate=0., hybrid_backbone=None, norm_layer=nn.LayerNorm, multi_conv=False):
super().__init__()
self.num_classes = num_classes if not isinstance(img_size, list):
img_size = to_2tuple(img_size)
self.img_size = img_size
num_patches = _compute_num_patches(img_size, patch_size)
self.num_branches = len(patch_size)
self.patch_embed = nn.LayerList()
self.pos_embed = nn.ParameterList([self.create_parameter(shape=(1, 1 + num_patches[i], embed_dim[i]),
default_initializer=nn.initializer.TruncatedNormal(std=.02)) for i in range(self.num_branches)]) for im_s, p, d in zip(img_size, patch_size, embed_dim):
self.patch_embed.append(PatchEmbed(img_size=im_s, patch_size=p, in_chans=in_chans, embed_dim=d, multi_conv=multi_conv))
self.cls_token = nn.ParameterList([self.create_parameter(shape=(1, 1, embed_dim[i]),
default_initializer=nn.initializer.TruncatedNormal(std=.02)) for i in range(self.num_branches)])
self.pos_drop = nn.Dropout(p=drop_rate)
total_depth = sum([sum(x[-2:]) for x in depth])
dpr = [x.item() for x in paddle.linspace(0, drop_path_rate, total_depth)] # stochastic depth decay rule
dpr_ptr = 0
self.blocks = nn.LayerList() for idx, block_cfg in enumerate(depth):
curr_depth = max(block_cfg[:-1]) + block_cfg[-1]
dpr_ = dpr[dpr_ptr:dpr_ptr + curr_depth]
blk = MultiScaleBlock(embed_dim, num_patches, block_cfg, num_heads=num_heads, mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr_,
norm_layer=norm_layer)
dpr_ptr += curr_depth
self.blocks.append(blk)
self.norm = nn.LayerList([norm_layer(embed_dim[i]) for i in range(self.num_branches)])
self.head = nn.LayerList([nn.Linear(embed_dim[i], num_classes) if num_classes > 0 else nn.Identity() for i in range(self.num_branches)])
self.apply(self._init_weights) def _init_weights(self, m):
tn = nn.initializer.TruncatedNormal(std=.02)
one = nn.initializer.Constant(1.0)
zero = nn.initializer.Constant(0.0) if isinstance(m, nn.Linear):
tn(m.weight) if isinstance(m, nn.Linear) and m.bias is not None:
zero(m.bias) elif isinstance(m, nn.LayerNorm):
zero(m.bias)
one(m.weight) def forward_features(self, x):
B, C, H, W = x.shape
xs = [] for i in range(self.num_branches):
x_ = F.interpolate(x, size=(self.img_size[i], self.img_size[i]), mode='bicubic') if H != self.img_size[i] else x
tmp = self.patch_embed[i](x_)
cls_tokens = self.cls_token[i].expand((B, -1, -1)) # stole cls_tokens impl from Phil Wang, thanks
tmp = paddle.concat((cls_tokens, tmp), axis=1)
tmp = tmp + self.pos_embed[i]
tmp = self.pos_drop(tmp)
xs.append(tmp) for blk in self.blocks:
xs = blk(xs) # NOTE: was before branch token section, move to here to assure all branch token are before layer norm
xs = [self.norm[i](x) for i, x in enumerate(xs)]
out = [x[:, 0] for x in xs] return out def forward(self, x):
xs = self.forward_features(x)
ce_logits = [self.head[i](x) for i, x in enumerate(xs)]
ce_logits = paddle.mean(paddle.stack(ce_logits, axis=0), axis=0) return ce_logits
def crossvit_tiny_224(pretrained=False, **kwargs):
model = VisionTransformer(img_size=[240, 224],
patch_size=[12, 16], embed_dim=[96, 192], depth=[[1, 4, 0], [1, 4, 0], [1, 4, 0]],
num_heads=[3, 3], mlp_ratio=[4, 4, 1], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, epsilon=1e-6), **kwargs) return modeldef crossvit_small_224(pretrained=False, **kwargs):
model = VisionTransformer(img_size=[240, 224],
patch_size=[12, 16], embed_dim=[192, 384], depth=[[1, 4, 0], [1, 4, 0], [1, 4, 0]],
num_heads=[6, 6], mlp_ratio=[4, 4, 1], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, epsilon=1e-6), **kwargs) return modeldef crossvit_base_224(pretrained=False, **kwargs):
model = VisionTransformer(img_size=[240, 224],
patch_size=[12, 16], embed_dim=[384, 768], depth=[[1, 4, 0], [1, 4, 0], [1, 4, 0]],
num_heads=[12, 12], mlp_ratio=[4, 4, 1], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, epsilon=1e-6), **kwargs) return modeldef crossvit_9_224(pretrained=False, **kwargs):
model = VisionTransformer(img_size=[240, 224],
patch_size=[12, 16], embed_dim=[128, 256], depth=[[1, 3, 0], [1, 3, 0], [1, 3, 0]],
num_heads=[4, 4], mlp_ratio=[3, 3, 1], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, epsilon=1e-6), **kwargs) return modeldef crossvit_15_224(pretrained=False, **kwargs):
model = VisionTransformer(img_size=[240, 224],
patch_size=[12, 16], embed_dim=[192, 384], depth=[[1, 5, 0], [1, 5, 0], [1, 5, 0]],
num_heads=[6, 6], mlp_ratio=[3, 3, 1], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, epsilon=1e-6), **kwargs) return modeldef crossvit_18_224(pretrained=False, **kwargs):
model = VisionTransformer(img_size=[240, 224],
patch_size=[12, 16], embed_dim=[224, 448], depth=[[1, 6, 0], [1, 6, 0], [1, 6, 0]],
num_heads=[7, 7], mlp_ratio=[3, 3, 1], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, epsilon=1e-6), **kwargs) return modeldef crossvit_9_dagger_224(pretrained=False, **kwargs):
model = VisionTransformer(img_size=[240, 224],
patch_size=[12, 16], embed_dim=[128, 256], depth=[[1, 3, 0], [1, 3, 0], [1, 3, 0]],
num_heads=[4, 4], mlp_ratio=[3, 3, 1], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, epsilon=1e-6), multi_conv=True, **kwargs) return modeldef crossvit_15_dagger_224(pretrained=False, **kwargs):
model = VisionTransformer(img_size=[240, 224],
patch_size=[12, 16], embed_dim=[192, 384], depth=[[1, 5, 0], [1, 5, 0], [1, 5, 0]],
num_heads=[6, 6], mlp_ratio=[3, 3, 1], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, epsilon=1e-6), multi_conv=True, **kwargs) return modeldef crossvit_18_dagger_224(pretrained=False, **kwargs):
model = VisionTransformer(img_size=[240, 224],
patch_size=[12, 16], embed_dim=[224, 448], depth=[[1, 6, 0], [1, 6, 0], [1, 6, 0]],
num_heads=[7, 7], mlp_ratio=[3, 3, 1], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, epsilon=1e-6), multi_conv=True, **kwargs) return model
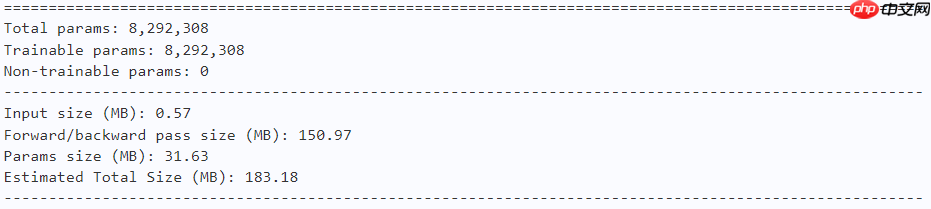
2.3.4 模型的参数
model = crossvit_9_dagger_224(num_classes=10) paddle.summary(model, (1, 3, 224, 224))
2.4 训练
learning_rate = 0.0003n_epochs = 100paddle.seed(42) np.random.seed(42)
work_path = 'work/model'# CrossViT-9-*model = crossvit_9_dagger_224(num_classes=10)
criterion = LabelSmoothingCrossEntropy()
scheduler = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=learning_rate, T_max=50000 // batch_size * n_epochs, verbose=False)
optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=scheduler, weight_decay=1e-5)
gate = 0.0threshold = 0.0best_acc = 0.0val_acc = 0.0loss_record = {'train': {'loss': [], 'iter': []}, 'val': {'loss': [], 'iter': []}} # for recording lossacc_record = {'train': {'acc': [], 'iter': []}, 'val': {'acc': [], 'iter': []}} # for recording accuracyloss_iter = 0acc_iter = 0for epoch in range(n_epochs): # ---------- Training ----------
model.train()
train_num = 0.0
train_loss = 0.0
val_num = 0.0
val_loss = 0.0
accuracy_manager = paddle.metric.Accuracy()
val_accuracy_manager = paddle.metric.Accuracy() print("#===epoch: {}, lr={:.10f}===#".format(epoch, optimizer.get_lr())) for batch_id, data in enumerate(train_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
logits = model(x_data)
loss = criterion(logits, y_data)
acc = accuracy_manager.compute(logits, labels)
accuracy_manager.update(acc) if batch_id % 10 == 0:
loss_record['train']['loss'].append(loss.numpy())
loss_record['train']['iter'].append(loss_iter)
loss_iter += 1
loss.backward()
optimizer.step()
scheduler.step()
optimizer.clear_grad()
train_loss += loss
train_num += len(y_data)
total_train_loss = (train_loss / train_num) * batch_size
train_acc = accuracy_manager.accumulate()
acc_record['train']['acc'].append(train_acc)
acc_record['train']['iter'].append(acc_iter)
acc_iter += 1
# Print the information.
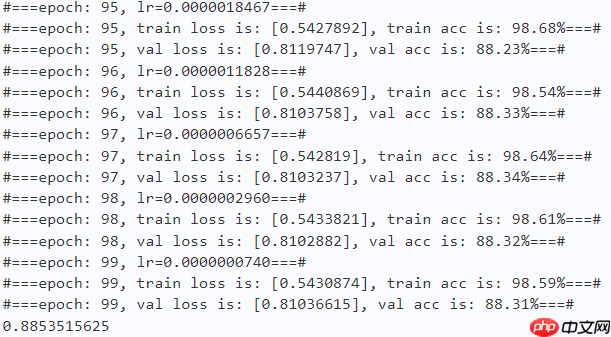
print("#===epoch: {}, train loss is: {}, train acc is: {:2.2f}%===#".format(epoch, total_train_loss.numpy(), train_acc*100)) # ---------- Validation ----------
model.eval() for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1) with paddle.no_grad():
logits = model(x_data)
loss = criterion(logits, y_data)
acc = val_accuracy_manager.compute(logits, labels)
val_accuracy_manager.update(acc)
val_loss += loss
val_num += len(y_data)
total_val_loss = (val_loss / val_num) * batch_size
loss_record['val']['loss'].append(total_val_loss.numpy())
loss_record['val']['iter'].append(loss_iter)
val_acc = val_accuracy_manager.accumulate()
acc_record['val']['acc'].append(val_acc)
acc_record['val']['iter'].append(acc_iter)
print("#===epoch: {}, val loss is: {}, val acc is: {:2.2f}%===#".format(epoch, total_val_loss.numpy(), val_acc*100)) # ===================save====================
if val_acc > best_acc:
best_acc = val_acc
paddle.save(model.state_dict(), os.path.join(work_path, 'best_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'best_optimizer.pdopt'))print(best_acc)
paddle.save(model.state_dict(), os.path.join(work_path, 'final_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'final_optimizer.pdopt'))
2.5 结果分析
def plot_learning_curve(record, title='loss', ylabel='CE Loss'):
''' Plot learning curve of your CNN '''
maxtrain = max(map(float, record['train'][title]))
maxval = max(map(float, record['val'][title]))
ymax = max(maxtrain, maxval) * 1.1
mintrain = min(map(float, record['train'][title]))
minval = min(map(float, record['val'][title]))
ymin = min(mintrain, minval) * 0.9
total_steps = len(record['train'][title])
x_1 = list(map(int, record['train']['iter']))
x_2 = list(map(int, record['val']['iter']))
figure(figsize=(10, 6))
plt.plot(x_1, record['train'][title], c='tab:red', label='train')
plt.plot(x_2, record['val'][title], c='tab:cyan', label='val')
plt.ylim(ymin, ymax)
plt.xlabel('Training steps')
plt.ylabel(ylabel)
plt.title('Learning curve of {}'.format(title))
plt.legend()
plt.show()
plot_learning_curve(loss_record, title='loss', ylabel='CE Loss')
<Figure size 1000x600 with 1 Axes>
plot_learning_curve(acc_record, title='acc', ylabel='Accuracy')
<Figure size 1000x600 with 1 Axes>
import time
work_path = 'work/model'model = crossvit_9_dagger_224(num_classes=10)
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
aa = time.time()for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1) with paddle.no_grad():
logits = model(x_data)
bb = time.time()print("Throughout:{}".format(int(len(val_dataset)//(bb - aa))))
Throughout:873
def get_cifar10_labels(labels):
"""返回CIFAR10数据集的文本标签。"""
text_labels = [ 'airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'] return [text_labels[int(i)] for i in labels]
def show_images(imgs, num_rows, num_cols, pred=None, gt=None, scale=1.5):
"""Plot a list of images."""
figsize = (num_cols * scale, num_rows * scale)
_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten() for i, (ax, img) in enumerate(zip(axes, imgs)): if paddle.is_tensor(img):
ax.imshow(img.numpy()) else:
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False) if pred or gt:
ax.set_title("pt: " + pred[i] + "\ngt: " + gt[i]) return axes
work_path = 'work/model'X, y = next(iter(DataLoader(val_dataset, batch_size=18))) model = crossvit_9_dagger_224(num_classes=10) model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams')) model.set_state_dict(model_state_dict) model.eval() logits = model(X) y_pred = paddle.argmax(logits, -1) X = paddle.transpose(X, [0, 2, 3, 1]) axes = show_images(X.reshape((18, 224, 224, 3)), 1, 18, pred=get_cifar10_labels(y_pred), gt=get_cifar10_labels(y)) plt.show()
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
<Figure size 2700x150 with 18 Axes>
总结
本文探究了一种多尺度的ViT——CrossViT,通过不同粒度的分支来捕获多尺度信息,并提出了一种跨注意力操作来进行两个分支信息的交互。实现思想简单有效。




























