







VibeVoice是什么
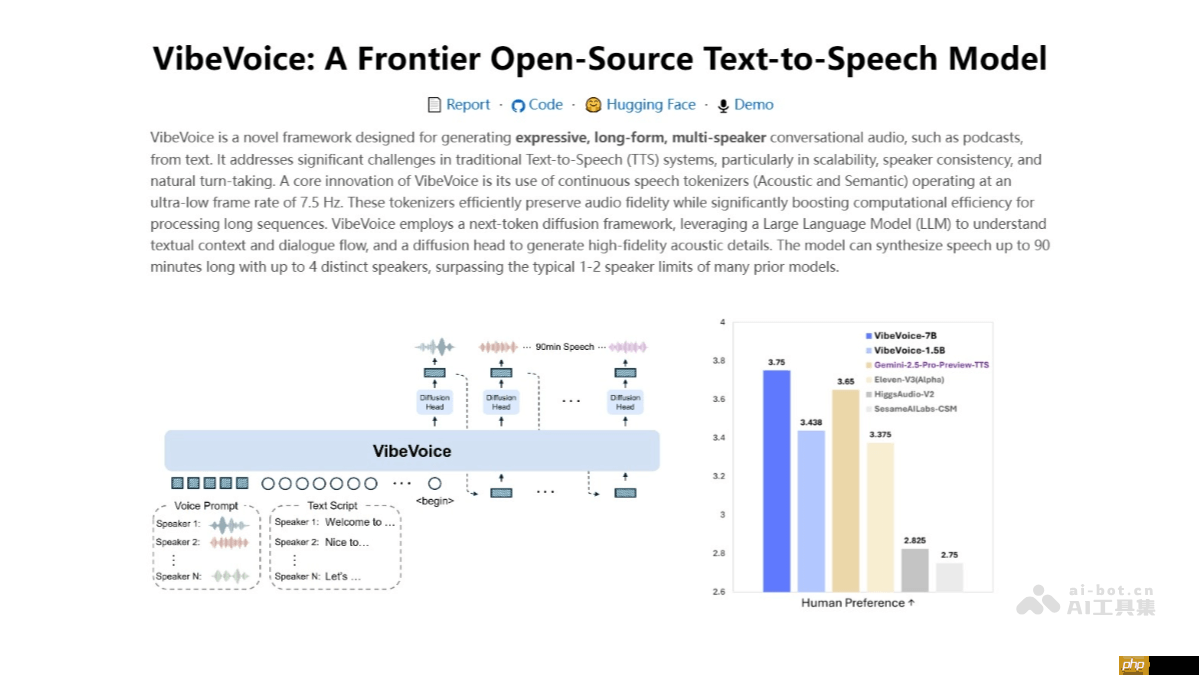
vibevoice 是微软最新推出的文本到语音(tts)模型,能够生成具有丰富情感、支持多位说话者、适用于长篇内容的自然对话音频,例如播客节目。该模型融合了创新的连续语音标记技术与先进的标记扩散生成架构,并结合大型语言模型(llm),实现了对长序列语音的高效建模,同时保持出色的音质表现。vibevoice 可合成最长90分钟的语音内容,支持最多4位不同角色的声音输出,显著超越传统tts系统的能力边界,为情感化语音合成和自然对话生成开辟了新路径。

☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
VibeVoice的主要功能
- 多说话者语音合成:可生成包含最多4位不同说话者的对话音频,适用于播客、有声剧等多人互动场景。
- 超长语音生成:支持连续生成长达90分钟的语音内容,突破常规TTS在时长方面的限制。
- 情感化语音表达:根据上下文生成富有情感、语调自然的语音,增强对话的真实感和感染力。
- 跨语言语音合成:具备多语言支持能力,能处理混合语言的对话内容,适应国际化应用需求。
- 高保真音质输出:生成的语音清晰自然,接近真人发音水平,提供沉浸式的听觉体验。
- 实时语音生成能力:支持低延迟语音合成,可用于实时对话系统和交互式应用场景。
VibeVoice的技术原理
- 连续语音标记化技术:采用语义与声学双路径标记系统,将语音信号分解为低帧率(如7.5 Hz)的连续标记流,兼顾计算效率与音频保真度。其中,语义标记器(Semantic Tokenizer)提取文本语义特征,声学标记器(Acoustic Tokenizer)负责捕捉语音的声学细节。
- 基于扩散的标记生成框架:利用下一代扩散模型架构,结合大型语言模型(LLM)理解文本语境与对话逻辑,通过逐步去噪的方式生成高质量语音标记序列。
- 多说话者一致性建模:引入说话者嵌入(Speaker Embeddings)机制,确保每位说话者的声音特征在整个长音频中保持稳定,实现自然的说话人切换与对话连贯性。
- 高保真声码器重建:采用优化后的神经声码器(Vocoder),将生成的语义与声学标记高效还原为高分辨率音频波形,确保最终输出音质细腻、真实。
VibeVoice的项目地址
- 项目官网:https://www.php.cn/link/2ad6254f399210225fd55b419d4c855e
- GitHub仓库:https://www.php.cn/link/42261fcdb3fa72a280e5adbb43bda240
- HuggingFace模型库:https://www.php.cn/link/5df66942fc13bbf265e17d1a3cb14b91
- 技术论文:https://www.php.cn/link/42261fcdb3fa72a280e5adbb43bda240/blob/main/report/TechnicalReport.pdf
VibeVoice的应用场景
- 播客内容创作:支持多主持人、长时长的自动语音生成,大幅降低播客制作门槛,提升内容生产效率。
- 有声读物生成:通过情感化语音合成,让文学作品朗读更具表现力,提升听众的沉浸感与阅读兴趣。
- 智能虚拟助手:为AI助手提供更自然、人性化的语音交互能力,增强用户沟通体验。
- 教育与培训应用:可用于模拟课堂讨论、语言教学或培训对话,提升教学材料的互动性与生动性。
- 游戏与娱乐场景:为游戏角色赋予富有情感的语音表现,增强叙事张力和玩家沉浸感,适用于互动影视、虚拟主播等场景。




























