







腾讯 ai lab 联合香港中文大学(深圳)、南京大学共同推出了一款全新的开源歌曲生成模型 songbloom,其研究成果已成功入选全球顶尖人工智能会议 neurips 2025。
据介绍,SongBloom 是一款专注于高质量歌曲创作的创新性生成模型。仅需提供一段 10 秒的音频参考样本和对应歌词文本,即可自动生成时长为 2 分 30 秒、双通道/48kHz 的完整音乐作品。在主客观综合评估中,该模型不仅显著优于现有开源方案,还在音质还原度与歌词对齐精度两大关键指标上表现出色;同时,在旋律性与音乐表现力方面也接近当前领域最先进水平(SOTA)。
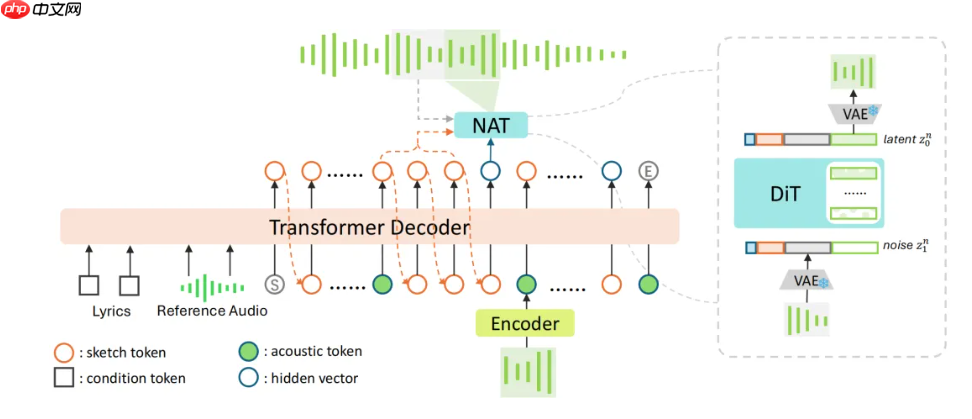
SongBloom 实现了两项核心技术突破:
- 首次将自回归扩散机制应用于长序列歌曲生成任务。通过引入离散的 sketch token 作为“链式思维”式的中间表示,并结合 VAE latent 空间进行最终音频合成,该架构有效融合了自回归模型在结构连贯性和音素同步上的优势,以及扩散模型在连续声学特征建模中提升音质的能力,实现了“结构稳定、细节丰富、情感表达强”的高质量输出。

- 研发团队提出一种全新的交替生成范式(interleaved generation),能够在“语义理解”与“声学生成”两种上下文模式之间动态切换。这一机制既保障了整首歌曲的逻辑结构完整性,又提升了局部声音质感的精细程度,为音乐生成 AI 提供了一条前所未有的技术路径。
据腾讯方面披露,在多项客观评测中,SongBloom 的美学得分不仅大幅领先主流开源基准模型,甚至媲美乃至超越部分领先的商业闭源系统;此外,模型展现出极强的歌词遵循能力,显著缓解了传统生成模型中存在的“幻觉问题”(即生成内容偏离歌词本意),并将音素错误率(PER)降至新低,推动歌词准确率迈上新台阶。

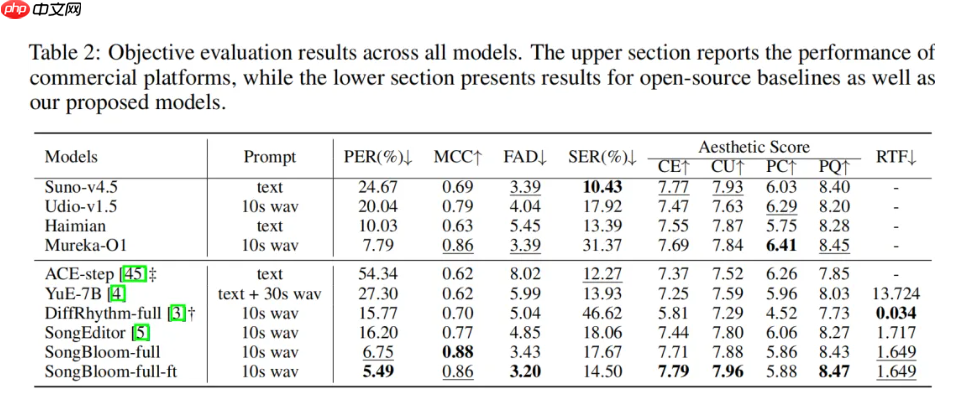
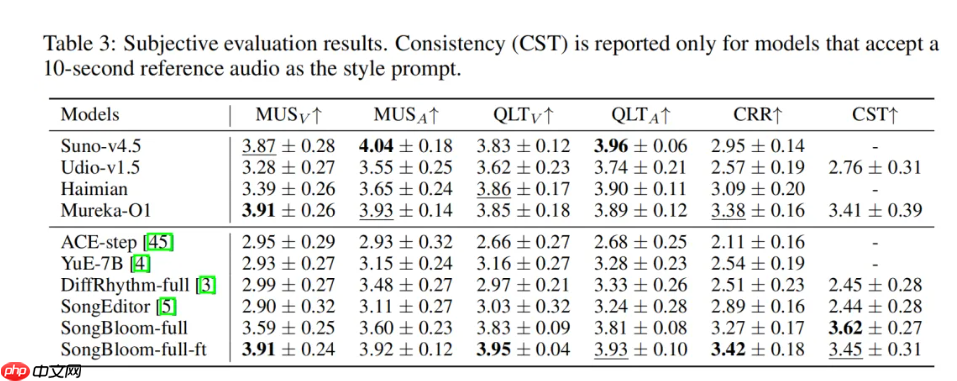
在主观听感测试中,SongBloom 同样表现抢眼。得益于 VAE latent 所保留的高保真声学信息,其生成的人声细腻度已超越目前业内领先的闭源模型 Suno-v4.5;而在整体音乐性方面,亦达到可与多个商用模型相抗衡甚至更优的水准,使 AI 创作的音乐更加贴近专业级制作质感。
目前,项目全部代码及预训练权重均已开放。未来,团队还将陆续发布支持长达 240 秒的完整版模型,以及增强文本控制能力的新版本。
源码地址:点击下载




























