







本文中将介绍一个流行的机器学习项目——文本生成器,你将了解如何构建文本生成器,并了解如何实现马尔可夫链以实现更快的预测模型。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

文本生成器简介
文本生成在各个行业都很受欢迎,特别是在移动、应用和数据科学领域。甚至新闻界也使用文本生成来辅助写作过程。
在日常生活中都会接触到一些文本生成技术,文本补全、搜索建议,Smart Compose,聊天机器人都是应用的例子,
本文将使用马尔可夫链构建一个文本生成器。这将是一个基于字符的模型,它接受链的前一个字符并生成序列中的下一个字母。
通过使用样例单词训练我们的程序,文本生成器将学习常见的字符顺序模式。然后,文本生成器将把这些模式应用到输入,即一个不完整的单词,并输出完成该单词的概率最高的字符。
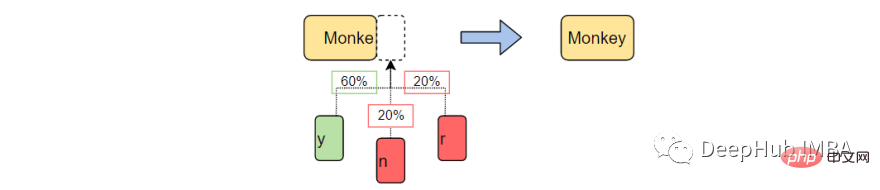
文本生成是自然语言处理的一个分支,它根据之前观察到的语言模式预测并生成下一个字符。
在没有机器学习之前,NLP是通过创建一个包含英语中所有单词的表,并将传递的字符串与现有的单词匹配来进行文字生成的。这种方法有两个问题。
- 搜索成千上万个单词会非常慢。
- 生成器只能补全它以前见过的单词。
机器学习和深度学习的出现,使得NLP允许我们大幅减少运行时并增加通用性,因为生成器可以完成它以前从未遇到过的单词。如果需要NLP可以扩展到预测单词、短语或句子!
对于这个项目,我们将专门使用马尔可夫链来完成。马尔可夫过程是许多涉及书面语言和模拟复杂分布样本的自然语言处理项目的基础。
马尔可夫过程是非常强大的,以至于它们只需要一个示例文档就可以用来生成表面上看起来真实的文本。
什么是马尔可夫链?
马尔可夫链是一种随机过程,它为一系列事件建模,其中每个事件的概率取决于前一个事件的状态。该模型有一组有限的状态,从一个状态移动到另一个状态的条件概率是固定的。
每次转移的概率只取决于模型的前一个状态,而不是事件的整个历史。
例如,假设想要构建一个马尔可夫链模型来预测天气。
在这个模型中我们有两种状态,晴天或雨天。如果我们今天一直处于晴朗的状态,明天就有更高的概率(70%)是晴天。雨也是如此;如果已经下过雨,很可能还会继续下雨。
但是天气会改变状态是有可能的(30%),所以我们也将其包含在我们的马尔可夫链模型中。
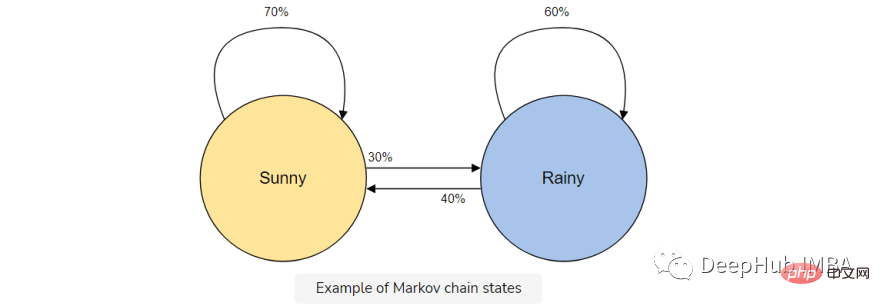
马尔可夫链是我们这个文本生成器的完美模型,因为我们的模型将仅使用前一个字符预测下一个字符。使用马尔可夫链的优点是,它是准确的,内存少(只存储1个以前的状态)并且执行速度快。
文本生成的实现
这里将通过6个步骤完成文本生成器:
- 生成查找表:创建表来记录词频
- 将频率转换为概率:将我们的发现转换为可用的形式
- 加载数据集:加载并利用一个训练集
- 构建马尔可夫链:使用概率为每个单词和字符创建链
- 对数据进行采样:创建一个函数对语料库的各个部分进行采样
- 生成文本:测试我们的模型

1、生成查找表
首先,我们将创建一个表,记录训练语料库中每个字符状态的出现情况。从训练语料库中保存最后的' K '字符和' K+1 '字符,并将它们保存在一个查找表中。
例如,想象我们的训练语料库包含,“the man was, they, then, the, the”。那么单词的出现次数为:
- “the” — 3
- “then” — 1
- “they” — 1
- “man” — 1
下面是查找表中的结果:

在上面的例子中,我们取K = 3,表示将一次考虑3个字符,并将下一个字符(K+1)作为输出字符。在上面的查找表中将单词(X)作为字符,将输出字符(Y)作为单个空格(" "),因为第一个the后面没有单词了。此外还计算了这个序列在数据集中出现的次数,在本例中为3次。
这样就生成了语料库中的每个单词的数据,也就是生成所有可能的X和Y对。
下面是我们如何在代码中生成查找表:
def generateTable(data,k=4):
T = {}
for i in range(len(data)-k):
X = data[i:i+k]
Y = data[i+k]
#print("X %s and Y %s "%(X,Y))
if T.get(X) is None:
T[X] = {}
T[X][Y] = 1
else:
if T[X].get(Y) is None:
T[X][Y] = 1
else:
T[X][Y] += 1
return T
T = generateTable("hello hello helli")
print(T)
#{'llo ': {'h': 2}, 'ello': {' ': 2}, 'o he': {'l': 2}, 'lo h': {'e': 2}, 'hell': {'i': 1, 'o': 2}, ' hel': {'l': 2}}代码的简单解释:
在第3行,创建了一个字典,它将存储X及其对应的Y和频率值。第9行到第17行,检查X和Y的出现情况,如果查找字典中已经有X和Y对,那么只需将其增加1。
2、将频率转换为概率
一旦我们有了这个表和出现的次数,就可以得到在给定x出现之后出现Y的概率。公式是:

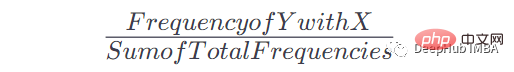
例如如果X = the, Y = n,我们的公式是这样的:
当X =the时Y = n的频率:2,表中总频率:8,因此:P = 2/8= 0.125= 12.5%
以下是我们如何应用这个公式将查找表转换为马尔科夫链可用的概率:
def convertFreqIntoProb(T):
for kx in T.keys():
s = float(sum(T[kx].values()))
for k in T[kx].keys():
T[kx][k] = T[kx][k]/s
return T
T = convertFreqIntoProb(T)
print(T)
#{'llo ': {'h': 1.0}, 'ello': {' ': 1.0}, 'o he': {'l': 1.0}, 'lo h': {'e': 1.0}, 'hell': {'i': 0.3333333333333333, 'o': 0.6666666666666666}, ' hel': {'l': 1.0}}简单解释:
把一个特定键的频率值加起来,然后把这个键的每个频率值除以这个加起来的值,就得到了概率。
3、加载数据集
接下来将加载真正的训练语料库。可以使用任何想要的长文本(.txt)文档。
为了简单起见将使用一个政治演讲来提供足够的词汇来教授我们的模型。
text_path = "train_corpus.txt"
def load_text(filename):
with open(filename,encoding='utf8') as f:
return f.read().lower()
text = load_text(text_path)
print('Loaded the dataset.')这个数据集可以为我们这个样例的项目提供足够的事件,从而做出合理准确的预测。与所有机器学习一样,更大的训练语料库将产生更准确的预测。
4、建立马尔可夫链
让我们构建马尔可夫链,并将概率与每个字符联系起来。这里将使用在第1步和第2步中创建的generateTable()和convertFreqIntoProb()函数来构建马尔可夫模型。
def MarkovChain(text,k=4): T = generateTable(text,k) T = convertFreqIntoProb(T) return T model = MarkovChain(text)
第1行,创建了一个方法来生成马尔可夫模型。该方法接受文本语料库和K值,K值是告诉马尔可夫模型考虑K个字符并预测下一个字符的值。第2行,通过向方法generateTable()提供文本语料库和K来生成查找表,该方法是我们在上一节中创建的。第3行,使用convertFreqIntoProb()方法将频率转换为概率值,该方法也是我们在上一课中创建的。
5、文本采样
创建一个抽样函数,它使用未完成的单词(ctx)、第4步中的马尔可夫链模型(模型)和用于形成单词基的字符数量(k)。
我们将使用这个函数对传递的上下文进行采样,并返回下一个可能的字符,并判断它是正确的字符的概率。
import numpy as np
def sample_next(ctx,model,k):
ctx = ctx[-k:]
if model.get(ctx) is None:
return " "
possible_Chars = list(model[ctx].keys())
possible_values = list(model[ctx].values())
print(possible_Chars)
print(possible_values)
return np.random.choice(possible_Chars,p=possible_values)
sample_next("commo",model,4)
#['n']
#[1.0]代码解释:
函数sample_next接受三个参数:ctx、model和k的值。
ctx是用来生成一些新文本的文本。但是这里只有ctx中的最后K个字符会被模型用来预测序列中的下一个字符。例如,我们传递common,K = 4,模型用来生成下一个字符的文本是是ommo,因为马尔可夫模型只使用以前的历史。
在第 9 行和第 10 行,打印了可能的字符及其概率值,因为这些字符也存在于我们的模型中。我们得到下一个预测字符为n,其概率为1.0。因为 commo 这个词在生成下一个字符后更可能是更常见的
在第12行,我们根据上面讨论的概率值返回一个字符。
6、生成文本
最后结合上述所有函数来生成一些文本。
def generateText(starting_sent,k=4,maxLen=1000):
sentence = starting_sent
ctx = starting_sent[-k:]
for ix in range(maxLen):
next_prediction = sample_next(ctx,model,k)
sentence += next_prediction
ctx = sentence[-k:]
return sentence
print("Function Created Successfully!")
text = generateText("dear",k=4,maxLen=2000)
print(text)结果如下:
dear country brought new consciousness. i heartily great service of their lives, our country, many of tricoloring a color flag on their lives independence today.my devoted to be oppression of independence.these day the obc common many country, millions of oppression of massacrifice of indian whom everest. my dear country is not in the sevents went was demanding and nights by plowing in the message of the country is crossed, oppressed, women, to overcrowding for years of the south, it is like the ashok chakra of constitutional states crossed, deprived, oppressions of freedom, i bow my heart to proud of our country.my dear country, millions under to be a hundred years of the south, it is going their heroes.
上面的函数接受三个参数:生成文本的起始词、K的值以及需要文本的最大字符长度。运行代码将得到一个以“dear”开头的2000个字符的文本。
虽然这段讲话可能没有太多意义,但这些词都是完整的,通常模仿了单词中熟悉的模式。
接下来要学什么
这是一个简单的文本生成项目。通过这个项目可以了解自然语言处理和马尔可夫链实际工作模式,可以在继续您的深度学习之旅时使用。
本文只是为了介绍马尔可夫链来进行的实验项目,因为它不会再实际应用中起到任何的作用,如果你想获得更好的文本生成效果,那么请学习GPT-3这样的工具。


























