







「指令」(Instruction)是ChatGPT模型取得突破性进展的关键因素,可以让语言模型的输出更符合「人类的偏好」。
但指令的标注工作需要耗费大量的人力,即便有了开源的语言模型,资金不足的学术机构、小公司也很难训练出自己ChatGPT.
最近微软的研究人员利用之前提出的Self-Instruct技术,首次尝试使用GPT-4模型来自动生成语言模型所需的微调指令数据。

论文链接:https://arxiv.org/pdf/2304.03277.pdf
代码链接:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM
在基于Meta开源的LLaMA模型上的实验结果表明,由 GPT-4生成的5.2万条英语和汉语instruction-following数据在新任务中的表现优于以前最先进的模型生成的指令数据,研究人员还从GPT-4中收集反馈和比较数据,以便进行全面的评估和奖励模式训练。
训练数据
数据收集
研究人员重用了斯坦福大学发布的Alpaca模型用到的5.2万条指令,其中每条指令都描述了模型应该执行的任务,并遵循与Alpaca相同的prompting策略,同时考虑有输入和无输入的情况,作为任务的可选上下文或输入;使用大型语言模型对指令输出答案。

在Alpaca 数据集中,输出是使用GPT-3.5(text-davinci-003)生成的,但在这篇论文中,研究人员选择使用GPT-4来生成数据,具体包括以下四个数据集:
1. 英文Instruction-Following Data:对于在Alpaca中收集的5.2万条指令,为每一条指令都提供一个英文GPT-4答案。

☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

未来的工作为遵循迭代的过程,使用GPT-4和self-instruct构建一个全新的数据集。
2. 中文Instruction-Following Data:使用ChatGPT将5.2万条指令翻译成中文,并要求GPT-4用中文回答这些指令,并以此建立一个基于LLaMA的中文instruction-following模型,并研究指令调优的跨语言泛化能力。
3. 对比数据(Comparison Data):要求GPT-4对自己的回复提供从1到10的评分,并对GPT-4, GPT-3.5和OPT-IML这三个模型的回复进行评分,以训练奖励模型。
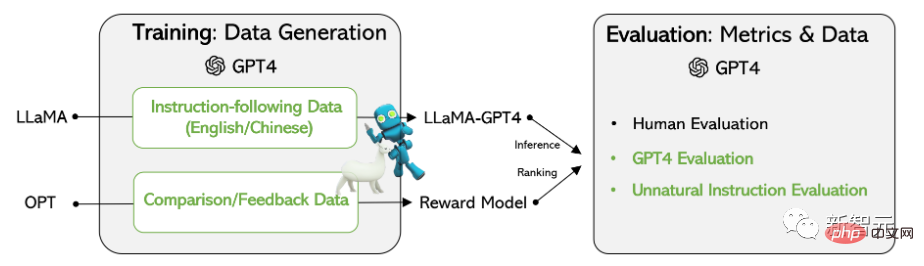
4. 非自然指令的答案:GPT-4的答案是在6.8万条(指令,输入,输出)三元组的数据集上解码的,使用该子集来量化GPT-4和指令调优后的模型在规模上的差距。
数据统计
研究人员对比了GPT-4和GPT-3.5的英语输出回复集合:对于每个输出,都提取了根动词(root verb)和直接宾语名词(direct-object noun),在每个输出集上计算了独特的动词-名词对的频率。
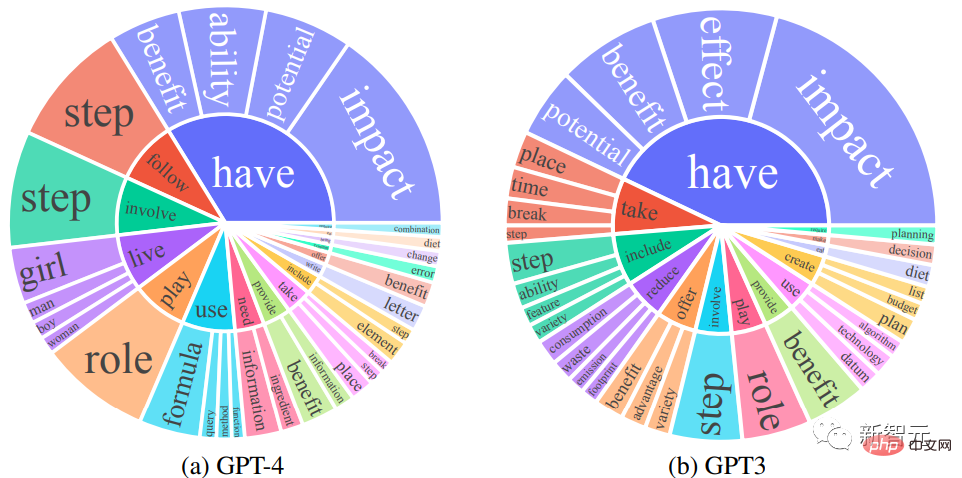
频率高于10的动词-名词对
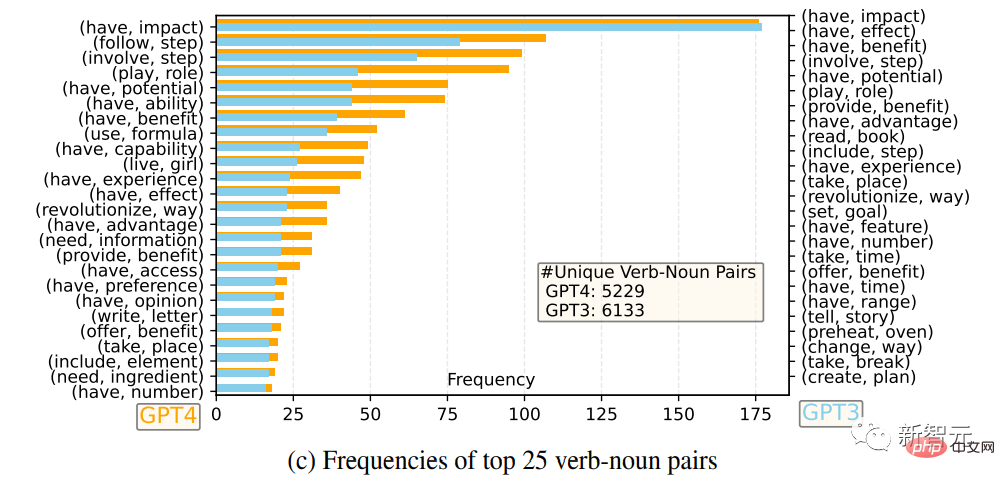
频率最高的25对动词-名词
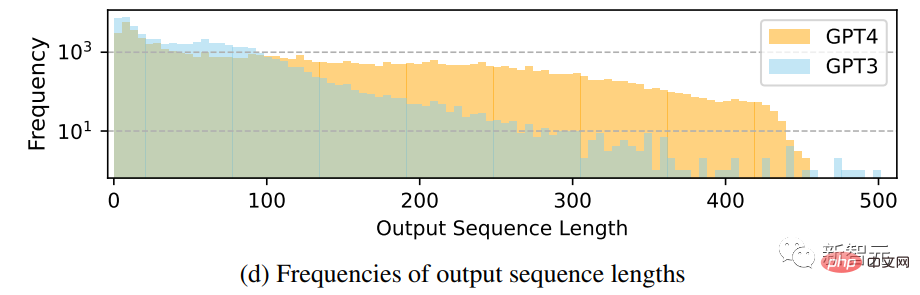
输出序列长度的频率分布对比
可以看到,GPT-4倾向于生成比GPT-3.5更长的序列,Alpaca中GPT-3.5数据的长尾现象比GPT-4的输出分布更明显,可能是因为Alpaca数据集涉及到一个迭代的数据收集过程,在每次迭代中去除相似的指令实例,在目前的一次性数据生成中是没有的。
尽管这个过程很简单,但GPT-4生成的instruction-following数据表现出更强大的对齐性能。
指令调优语言模型
Self-Instruct 调优
研究人员基于LLaMA 7B checkpoint有监督微调后训练得到了两个模型:LLaMA-GPT4是在GPT-4生成的5.2万条英文instruction-following数据上训练的;LLaMA-GPT4-CN是在GPT-4的5.2万条中文instruction-following数据上训练的。
两个模型被用来研究GPT-4的数据质量以及在一种语言中进行指令调优的LLMs时的跨语言泛化特性。
奖励模型
从人类反馈中进行强化学习(Reinforcement Learning from Human Feedback,RLHF)旨在使LLM行为与人类的偏好相一致,以使语言模型的输出对人类更加有用。
RLHF的一个关键组成部分是奖励建模,其问题可以被表述为一个回归任务,以预测给定提示和回复的奖励评分,该方法通常需要大规模的比较数据,即对同一提示的两个模型反应进行比较。
现有的开源模型,如Alpaca、Vicuna和Dolly,由于标注对比数据的成本很高,所以没有用到RLHF,并且最近的研究表明,GPT-4能够识别和修复自己的错误,并准确判断回复的质量。
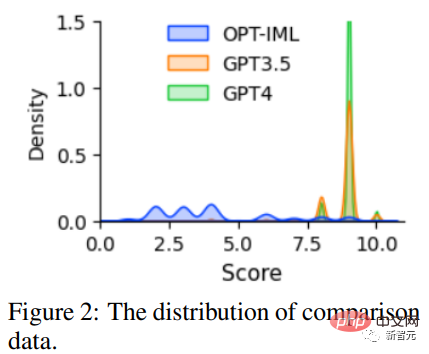
为了促进对RLHF的研究,研究人员使用GPT-4创建了对比数据;为了评估数据质量,研究人员训练一个基于OPT 1.3B的奖励模型,以对不同的回复进行评分:对一个提示和K个回复,GPT-4为每个回复提供一个1到10之间的评分。
实验结果
在 GPT-4数据上评估以前从未见过的任务的self-instruct调优模型的性能仍然是一项困难的任务。
由于主要目标是评估模型理解和遵守各种任务指示的能力,为了实现这一点,研究人员利用三种类型的评估,并通过研究结果证实,「利用 GPT-4生成数据」相比其他机器自动生成的数据来说是一种有效的大型语言模型指令调优方法。
人类评估
为了评估该指令调优后的大型语言模型对齐质量,研究人员遵循之前提出的对齐标准:如果一个助手是有帮助的、诚实的和无害的(HHH),那它就是与人类评估标准对齐的,这些标准也被广泛用于评估人工智能系统与人类价值观的一致性程度。
帮助性(helpfulness):是否能帮助人类实现他们的目标,一个能够准确回答问题的模型是有帮助的。
诚实性(honesty):是否提供真实信息,并在必要时表达其不确定性以避免误导人类用户,一个提供虚假信息的模型是不诚实的。
无害性(harmlessness):是否不会对人类造成伤害,一个产生仇恨言论或提倡暴力的模型不是无害的。
基于HHH对齐标准,研究人员使用众包平台Amazon Mechanical Turk对模型生成结果进行人工评估。
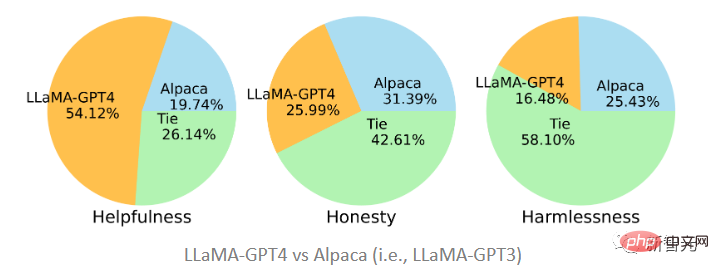
文中提出的两个模型分别在GPT-4和GPT-3生成的数据上进行了微调,可以看到LLaMA-GPT4以51.2%的占比在帮助性上要大大优于在GPT-3上微调的Alpaca(19.74%),而在诚实性和 无害性标准下,则基本处于平局状态,GPT-3要略胜一筹。
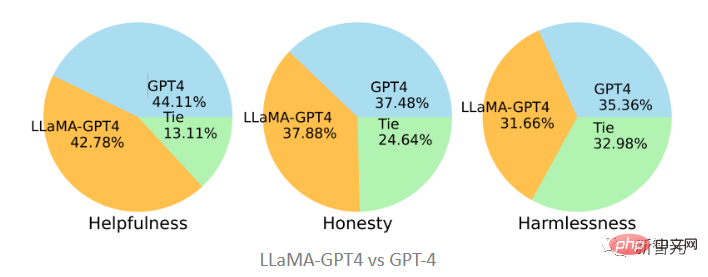
在和原版GPT-4对比时,可以发现二者在三个标准上也是相当一致的,即GPT-4指令调优后的LLaMA表现与原始的GPT-4类似。
GPT-4自动评估
受 Vicuna 的启发,研究人员也选择用GPT-4来评估不同聊天机器人模型对80个未见过的问题所生成回答的质量,从 LLaMA-GPT-4(7B)和 GPT-4模型中收集回复,并从以前的研究中获得其他模型的答案,然后要求GPT-4对两个模型之间的回复质量进行评分,评分范围从1到10,并将结果与其他强竞争模型(ChatGPT 和 GPT-4)进行比较。
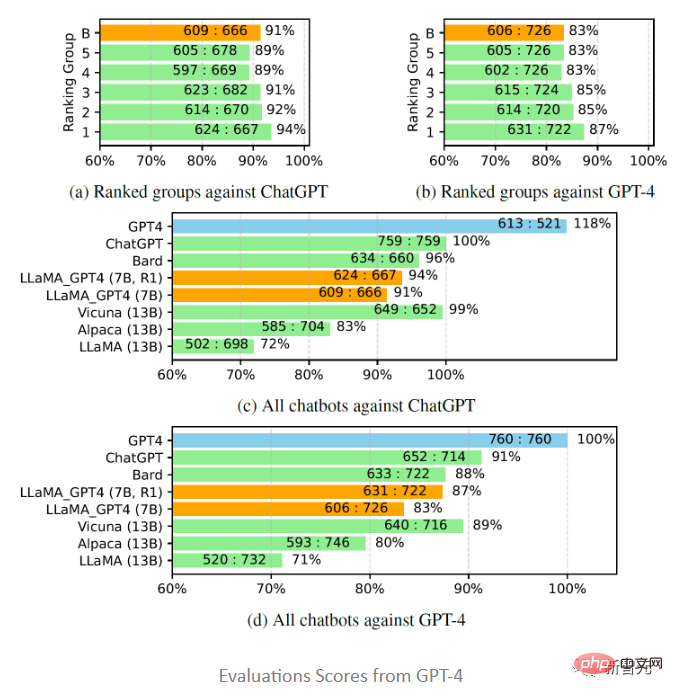
评估结果显示,反馈数据和奖励模型对提高 LLaMA 的性能是有效的;用GPT-4对LLaMA进行指令调优,往往比用text-davinci-003调优(即Alpaca)和不调优(即LLaMA)的性能更高;7B LLaMA GPT4的性能超过了13B Alpaca和LLaMA,但和GPT-4等大型商业聊天机器人相比,仍有差距。
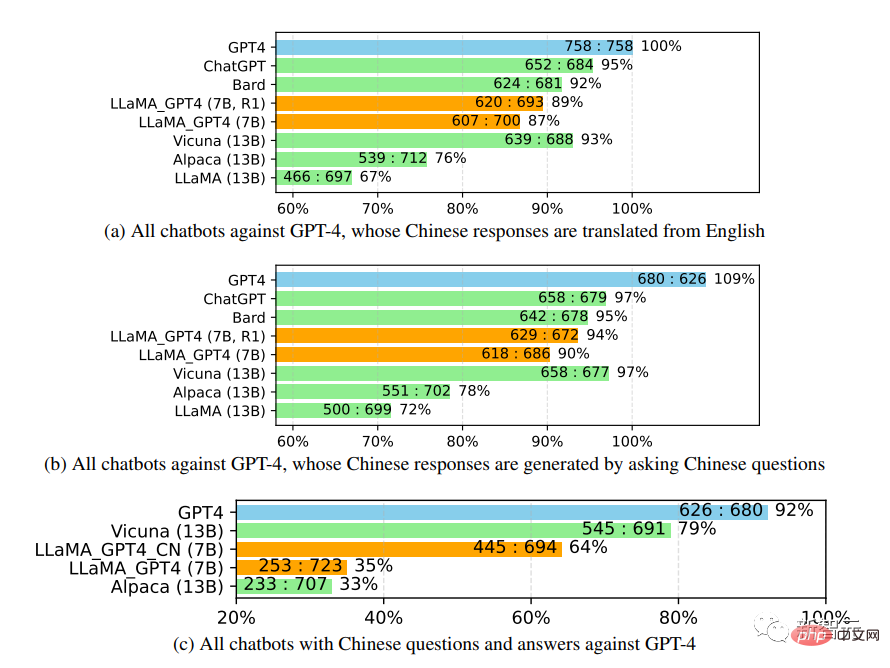
进一步研究中文聊天机器人的性能时,首先使用GPT-4将聊天机器人的问题也从英文翻译成中文,用GPT-4获得答案,可以得到两个有趣的观察结果:
1. 可以发现GPT-4评价的相对分数指标是相当一致的,无论是在不同的对手模型(即ChatGPT或GPT-4)和语言(即英语或中文)方面。
2. 仅就GPT-4的结果而言,翻译后的回复比中文生成的回复表现得更好,可能是因为GPT-4是在比中文更丰富的英文语料库中训练的,所以具有更强的英文instruction-following能力。
非自然指令评估(Unnatural Instruction Evaluation)
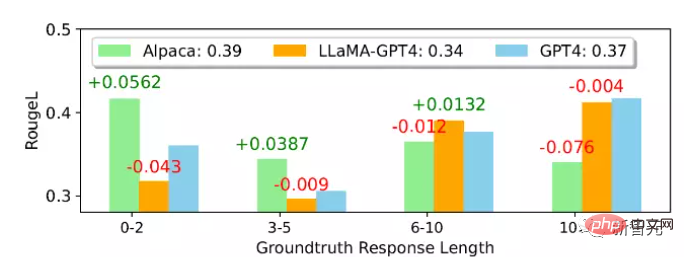
从平均ROUGE-L得分来看,Alpaca优于LLaMA-GPT 4和GPT-4,可以注意到,LLaMA-GPT4和GPT4在ground truth回复长度增加时逐渐表现得更好,最终在长度超过4时表现出更高的性能,意味着当场景更具创造性时,可以更好地遵循指令。
在不同的子集中,LLaMA-GPT4跟GPT-4的行为相差无几;当序列长度较短时,LLaMA-GPT4和GPT-4都能生成包含简单的基本事实答案的回复,但会增加额外的词语,使回复更像聊天,可能会导致ROUGE-L得分降低。




























